AI startup Prime Intellect trains first distributed LLM across three continents

AI startup Prime Intellect says it has completed training a 10-billion-parameter language model using computers spread across the US, Europe, and Asia.
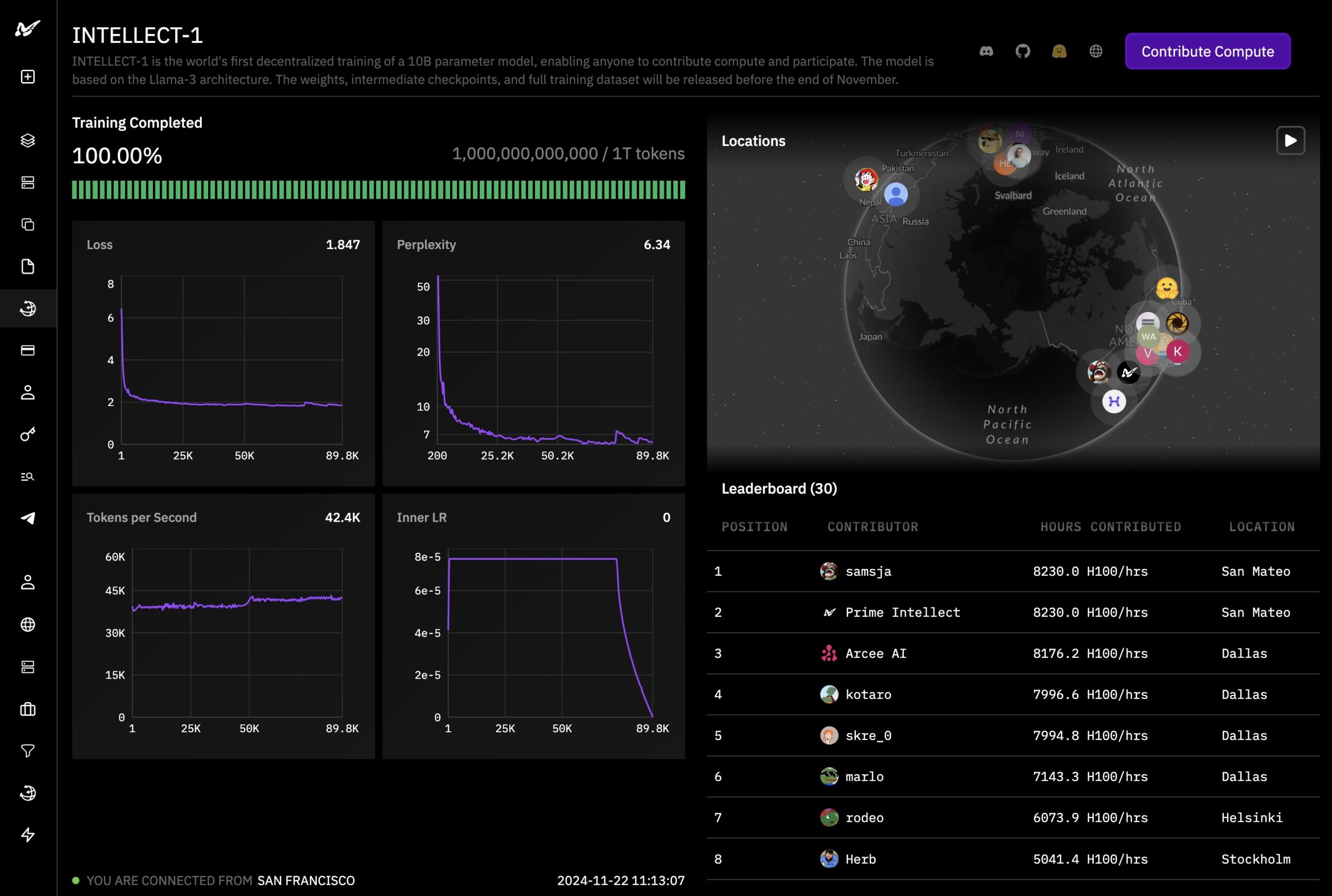
The company claims Intellect-1 is the first language model of this size trained using a distributed approach, and plans to make both Intellect-1 and its training data available as open source next week.
The project aims to show that smaller organizations can build large AI models too, with a goal of letting anyone contribute computing power to create transparent, freely available AI systems. The vision is to allow anyone to contribute computing power toward creating transparent, freely available open-source AGI systems.
New training method reduces data transfer requirements
The project uses Prime Intellect's open-source version of DeepMind's Distributed Low-Communication method (DiLoCo), called OpenDiLoCo. This approach lets organizations train AI models across globally distributed systems while minimizing data transfer requirements.
Building on this foundation, Prime Intellect created a system for reliable distributed training that can handle computing resources being added or removed on the fly. The system optimizes communication across a worldwide network of graphics cards.
The model is based on the LLaMA-3 architecture and trained on open datasets. Its training data of more than 6 trillion tokens comes primarily from four sources: Fineweb-edu, DLCM, Stack v2, and OpenWebMath.
Looking ahead
Prime Intellect calls this a first step toward bigger goals. The company wants to scale up its distributed training to work with more advanced open-source models. They're building a system to let anyone contribute computing power securely, with training sessions open to public participation.
The company says open-source AI development reduces risks of centralized control. However, they acknowledge that competing with major AI labs needs coordinated effort. They're seeking support through collaboration and computing resources.
While Intellect-1 represents progress in making AI development more accessible, its 10 billion parameters make it relatively small by today's standards. Even without benchmark results, it's unlikely to match larger commercial AI models, or even smaller open-source models.
The main question is whether Prime Intellect can take this approach beyond proof-of-concept into something that can meaningfully advance AI development.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.