DeepSeek's latest R1 model matches OpenAI's o1 in reasoning benchmarks

Chinese AI startup DeepSeek has released two new AI models that they say match OpenAI's o1 in performance. Along with their main models, DeepSeek-R1 and DeepSeek-R1-Zero, they've also launched six smaller open-source versions, with some performing as well as OpenAI's o1-mini.
What sets DeepSeek-R1-Zero apart is how it learns. Instead of studying human examples like most LLMs, it developed its reasoning skills entirely through reinforcement learning (RL). The model taught itself to check its work, think through problems, and break down complex tasks into steps.
According to the research team, the model learned to spend extra time on difficult problems and rethink its approach before providing an answer. This behavior reminded them of DeepMind's AlphaZero system - which likely inspired the model's name.
Building reasoning skills without human examples
Instead of using neural reward models, which they felt are prone to "reward hacking" and would require more computing power, the team built a straightforward reward system based on clear rules. They created two checking systems: one that verifies accuracy by comparing math solutions and testing programming code, and another that checks if answers follow the right format, including proper tags like "think" and "/think".
At the heart of their efficient training process is a new algorithm called "Group Relative Policy Optimization" (GRPO). Instead of evaluating each answer individually with a complex reward model, GRPO compares groups of answers to determine how to improve the model's performance.
While DeepSeek-R1-Zero showed promise, it had two main issues: its answers were hard to read, and it would sometimes mix different languages together. To address these problems, the team developed DeepSeek-R1, which starts with a small set of initial training data (what they call "cold start" data) before going through several rounds of reinforcement learning.
Matching OpenAI's o1 performance
DeepSeek-R1 performs as well as OpenAI-o1-1217 across various reasoning benchmarks. It scored 79.8% on AIME 2024 and reached 97.3% on MATH-500. The model particularly excels at coding tasks - outperforming 96.3% of human participants on Codeforces. It also shows strong results in knowledge tests like MMLU and GPQA Diamond, though OpenAI-o1-1217 maintains a slight edge in these areas.
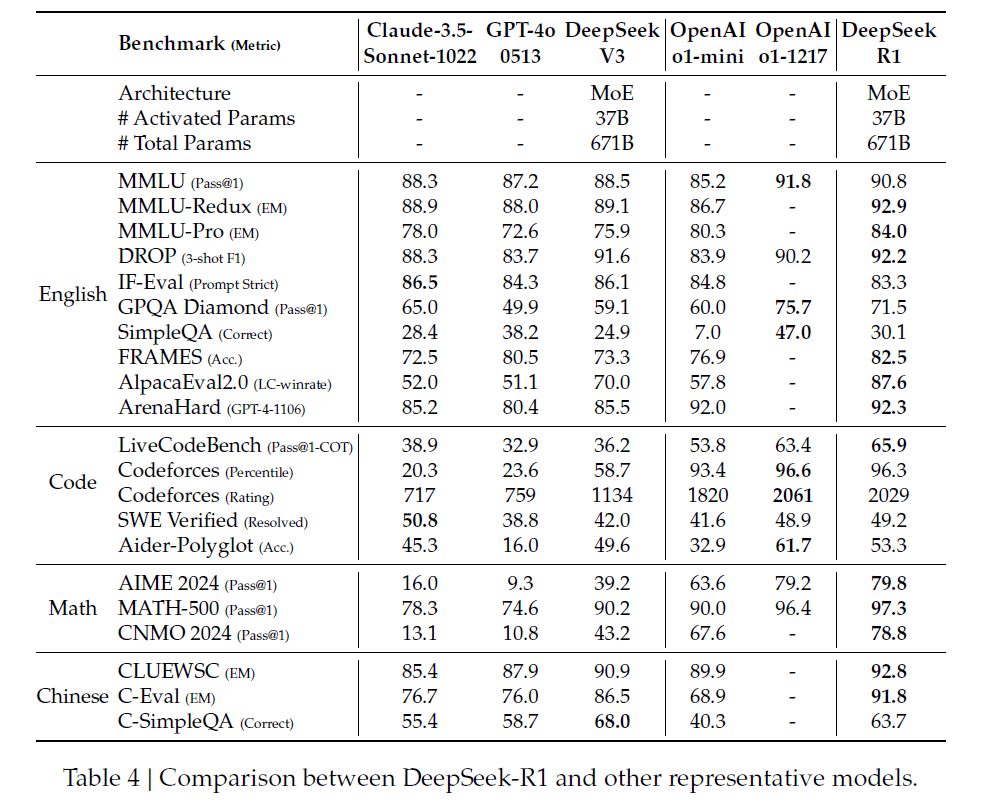
DeepSeek didn't stop with their main 671 billion parameter model. They also created six smaller versions, ranging from 1.5 to 70 billion parameters. To transfer the reasoning abilities to these smaller models, they used DeepSeek-R1 to generate 800,000 training examples and refined existing models like Qwen and Llama.
The results look promising - their 32B and 70B models match or exceed OpenAI-o1-mini on most tests. Interestingly, even their tiny 1.5B model outperforms some larger models on math tests, though this likely says more about the limitations of benchmarks than the model's overall capabilities.
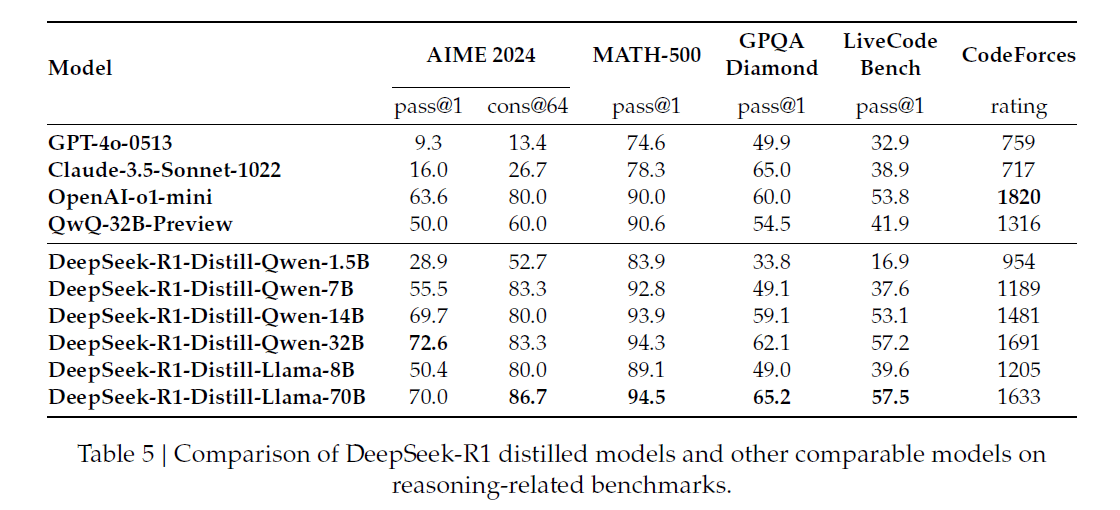
DeepSeek says the smaller models perform so well because they successfully captured the reasoning patterns of the larger model. Direct reinforcement learning on smaller models didn't work nearly as well. The team has made all these distilled models available as open source.
Looking ahead
DeepSeek plans to enhance R1's general capabilities, especially in areas like function calling, multi-turn conversations, and complex role-playing. The company acknowledges that the model still lags behind others, including their own DeepSeek-V3, in these areas.
They're also working to fix issues with language mixing and prompt sensitivity. For example, they found that performance drops significantly when using few-shot prompts. Interestingly, many of these limitations match those reported by OpenAI when they launched o1.
They're also working to enhance the model's coding abilities through additional reinforcement learning. According to their paper, the team is developing more efficient methods to implement this training.
Availability
DeepSeek-R1 uses the MIT license, which allows free use of the model weights and outputs, including for fine-tuning and distillation. All model variants and their documentation can be found on GitHub and HuggingFace.
The model is also available through DeepSeek's API - users can access it with the parameter "model=deepseek-reasoner". Pricing is set at $0.14 per million input tokens for cache hits, $0.55 for cache misses, and $2.19 per million output tokens.
While the benchmark results are impressive, real-world testing in the coming days will show whether DeepSeek-R1 can truly match OpenAI's o1 in practice. Looking ahead, DeepSeek could close the gap with OpenAI's recently introduced o3 model in its next release - but that depends on whether they can maintain their current development pace and whether their training methods can deliver the same kind of improvements that OpenAI achieved with o3 in just three months.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.