OpenAI beats Deepseek by a surprisingly wide margin in Google's latest reasoning benchmark

BIG-Bench, developed in 2021 as a universal benchmark for testing large language models, has reached its limits as current models achieve over 90% accuracy. In response, Google DeepMind has introduced BIG-Bench Extra Hard (BBEH), which reveals substantial weaknesses even in the most advanced AI models.
BBEH builds on its predecessor BIG-Bench Hard (BBH) by replacing each of the original 23 tasks with significantly more challenging versions. These new tasks require a broader range of reasoning abilities and are, on average, six times longer than BBH tasks. This increased complexity is reflected in the AI models' responses, which are typically seven times longer than those for BBH.
The new benchmark tests additional reasoning capabilities, including managing and reasoning within very long context dependencies, learning new concepts, distinguishing between relevant and irrelevant information, and finding errors in predefined reasoning chains.
Two examples highlight the benchmark's complexity. In the "Spatial Reasoning" task, an agent moves through a geometric structure and observes objects at different positions. Models must track object locations and draw conclusions about their relationships.
The "Object Properties" test presents a collection of objects with various characteristics (color, size, origin, smell, and material) that undergo changes. Models must track all object properties through each update, including tricky scenarios like losing an unspecified object with certain traits.
o3 mini beats R1 by an unexpected margin
Google DeepMind tested both general-purpose models like Gemini 2.0 Flash and GPT-4o, as well as specialized reasoning models such as o3-mini (high) and DeepSeek R1. The results exposed significant limitations: the best general-purpose model (Gemini 2.0 Flash) achieved only 9.8% average accuracy, while the best reasoning model (o3-mini high) only reached 44.8% average accuracy. GPT-4.5 has not yet been tested.
The analysis revealed expected differences between general and specialized reasoning models. Specialized models performed particularly well on formal problems involving counting, planning, arithmetic, and data structures. However, their advantage diminished or disappeared on tasks requiring common sense, humor, sarcasm, and causal understanding.
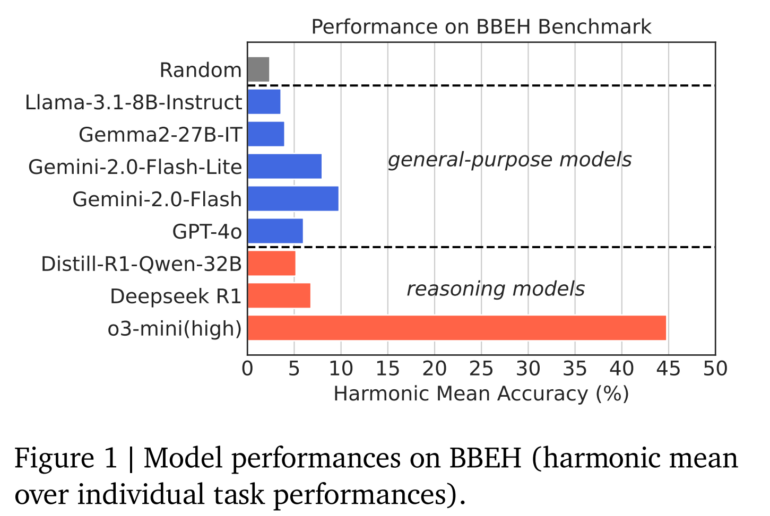
Notably, OpenAI's o3-mini (high) significantly outperformed the much-discussed DeepSeek R1. The Chinese model struggled with several benchmarks, including complete failure on the "Object Properties" test. The researchers attribute this mainly to the model losing track when it is unable to solve the problem in its effective output token length. R1 achieved only 6.8% average accuracy, falling three percentage points behind Gemini 2.0 Flash.
Performance insights and future implications
The research revealed that specialized reasoning models gain larger advantages over general models as context length and thinking complexity increase. Similarly, larger general models like Gemini 2.0 Flash show advantages over smaller ones such as Flash-Lite when dealing with longer contexts.
While modern LLMs have made significant progress, BBEH demonstrates they remain far from achieving general reasoning ability. The researchers emphasize that substantial work is still needed to close these gaps and develop more versatile AI systems.
The benchmark is publicly available at: https://github.com/google-deepmind/bbeh
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.