Researchers build massive AI training dataset using only openly licensed sources

The Common Pile is the first large-scale text dataset built entirely from openly licensed sources, offering an alternative to web data restricted by copyright.
The 8 TB Common Pile v0.1 was assembled by researchers from the University of Toronto, Hugging Face, EleutherAI, and the Allen Institute for AI (Ai2), among others. It brings together content from 30 different sources.
The dataset brings together scientific papers and abstracts from Arxiv, medical texts from PubMed Central, and millions of other research articles. Legal materials are included as well, such as US patents, government documents, court rulings from the Caselaw Access Project, and debate transcripts from the British Parliament. There are also books from Project Gutenberg and the Library of Congress, plus a wide range of free educational resources.
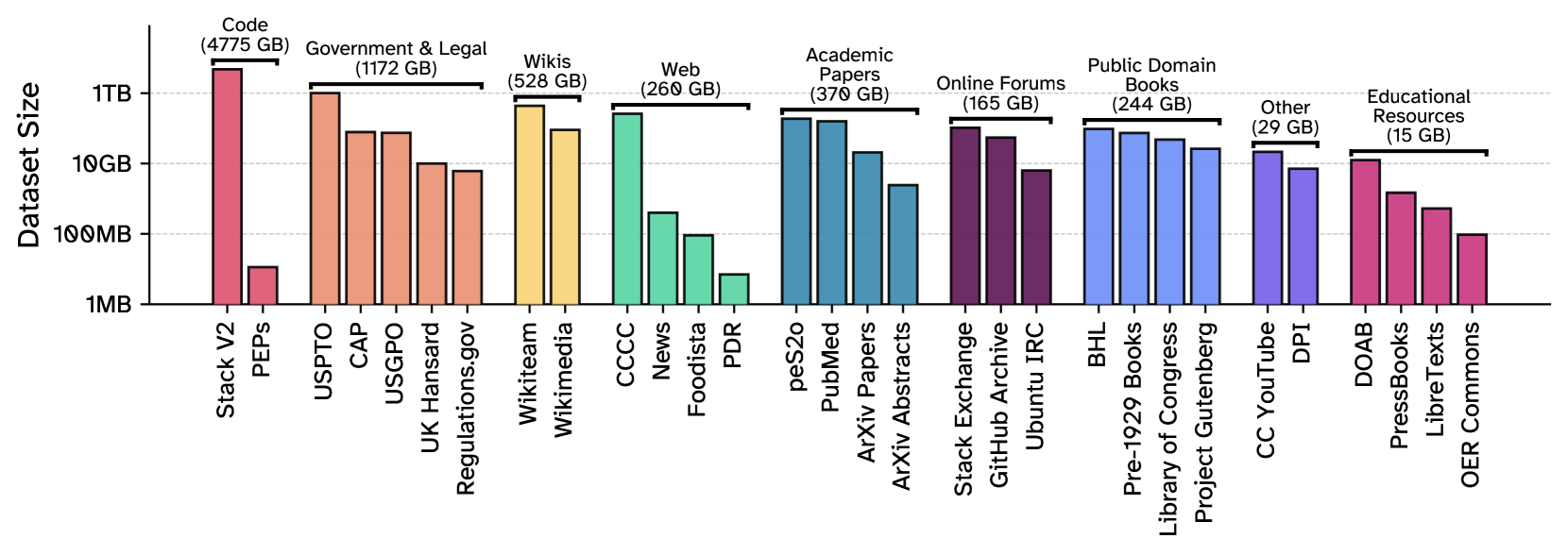
The Common Pile also draws from StackExchange forums, chat logs from the Ubuntu IRC, GitHub discussions, and transcribed YouTube videos from over 2,000 channels. A smaller slice of the dataset covers curated task formats, like question-answer pairs and classification problems.
Strict licensing, but no guarantees
Everything in the Common Pile had to meet the Open Definition 2.1 from the Open Knowledge Foundation. Only content with genuinely open licenses—such as CC BY, CC BY-SA, CC0, or permissive software licenses like MIT or BSD—made the cut. Anything with "non-commercial" (CC NC) or "no derivative works" (CC ND) restrictions was left out.
The team skipped sources with unclear licensing, including YouTube Commons and OpenAlex. They also avoided AI-generated text from models trained on unlicensed data, aiming to keep the dataset on solid ground legally.
Still, the researchers admit there's no way to guarantee perfection. Incorrect licensing (sometimes called "license laundering") or later changes to license terms could let problematic content slip through.
Cleaning out duplicates, ads, and low-quality content
Before training, the data went through heavy filtering. An automatic speech recognition system weeded out anything that wasn't in English. For web content, a text quality classifier removed low-quality writing.
Documents with unusual statistical patterns—flagged by a reference model—were filtered out, especially to catch mistakes from optical character recognition (OCR). Private info like emails, phone numbers, and IP addresses was replaced with generic placeholders. Toxic content was filtered out with a separate classifier.
Source code got special treatment. The team only included files from 15 programming languages like Python, C++, Java, and Rust, pulling them from the Stack V2 dataset. They made sure each code sample was well documented and good for learning purposes.
Comma: Open language models trained on the Common Pile
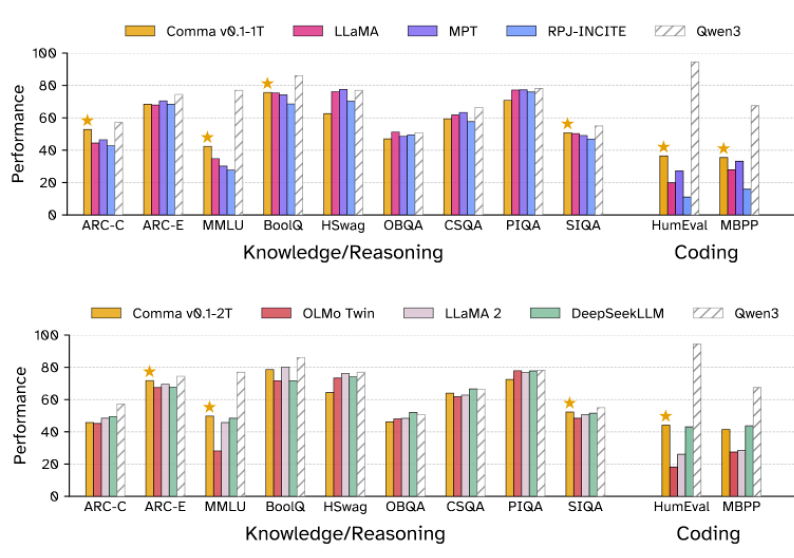
To see how the data performed in practice, the team trained two language models, each with seven billion parameters. Comma v0.1-1T was trained on one trillion tokens, while Comma v0.1-2T used twice as many. Both models build on Meta's Llama architecture, using a tokenizer trained specifically on the Common Pile.
The models were tested on a range of benchmarks: MMLU for general knowledge, ARC and CommonsenseQA for inference, and coding tasks like HumanEval and MBPP.
On many of these tests, Comma v0.1-1T outperformed similarly sized models like Llama-1-7B, StableLM-7B, and OpenLLaMA-7B, which were trained on unlicensed data. The biggest gains showed up in scientific and programming benchmarks.
Results were less impressive on tasks like HellaSwag or PIQA, which depend more on everyday language and informal writing. Content like personal stories, blogs, or non-English texts are still missing or underrepresented in the Common Pile.
The researchers also pitted the two-trillion-token Comma model against Llama-2-7B, OLMo-7B-Twin, and DeepSeekLLM. They noted that these comparison models were somewhat older, with none released after 2024, except for Qwen3-8B, which they considered the current state-of-the-art for open-source models. The team emphasized that they couldn't make a reliable comparison with models that had such drastically larger training budgets, pointing out the 36x or 18x difference.
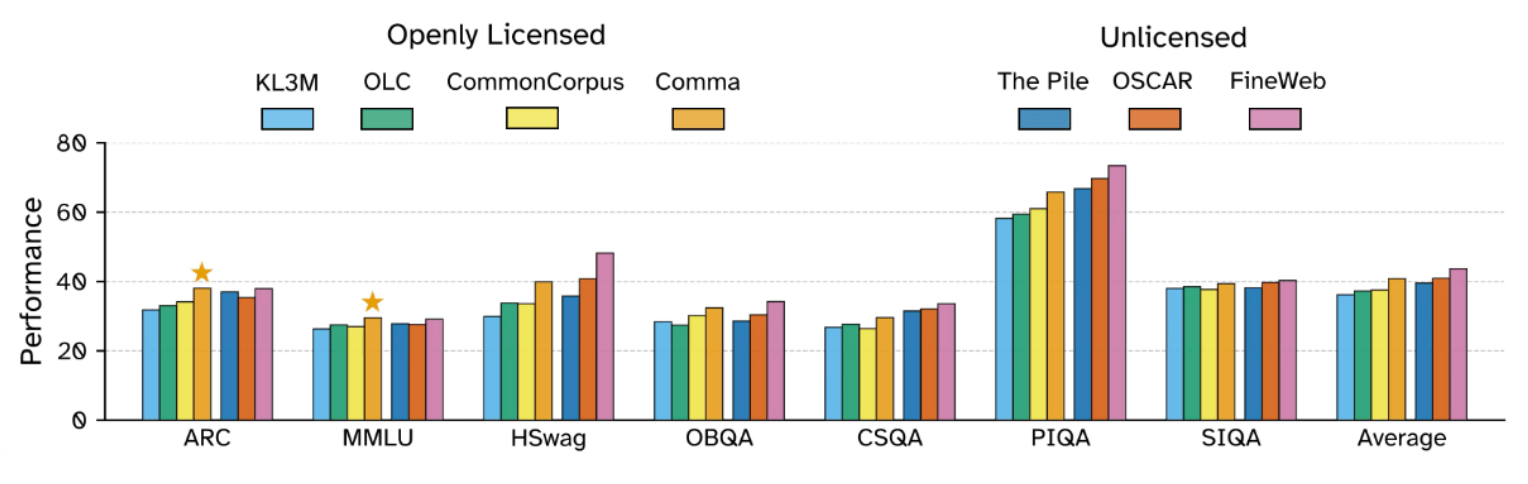
Against earlier open datasets like KL3M, OLC, and Common Corpus, the Common Pile consistently delivered better results. Comma also edged out most benchmarks against The Pile, an 800 GB meta-dataset compiled by EleutherAI in 2020. The Pile is widely used in AI research, but is controversial since much of its content is copyrighted and was included without explicit permission.
On most tests, the filtered web dataset FineWeb came out on top. But FineWeb is also built from sources that aren't exclusively openly licensed.
A first step toward legally compliant language models
The Common Pile v0.1 demonstrates that it's possible to build decent language models using only openly licensed data, potentially leading to a more transparent and legally sound AI ecosystem. However, the researchers are clear that this is just a first step. To compete with the biggest commercial models, they'll need to expand the open dataset substantially.
Along with the dataset, the team has released the data creation code, the Comma training dataset, and the tokenizer for public use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.