Researchers say they may have found a ladder to climb the "data wall"

Researchers at MIT have introduced a new framework called SEAL that lets large language models (LLMs) generate their own synthetic training data and improve themselves without outside help.
SEAL works in two stages. First, the model learns to create effective "self-edits" using reward learning. These self-edits are written as natural language instructions that define new training data and set optimization parameters. In the second stage, the system applies these instructions and updates its own weights through machine learning.

A key part of SEAL is its ReST^EM algorithm, which acts like a filter: it only keeps and reinforces self-edits that actually improve performance. The algorithm collects different edits, tests which ones work, and then trains the model using only the successful variants. SEAL also uses Low-Rank Adapters (LoRA), a technique that enables quick, lightweight updates without retraining the entire model.
The researchers put SEAL to the test in two scenarios. In the first, they used Qwen2.5-7B on a text comprehension task. The model generated logical inferences from text and then trained on its own outputs.

SEAL reached an accuracy of 47 percent, beating the comparison method's 33.5 percent. The quality of its self-generated data even surpassed that of OpenAI's GPT-4.1, despite the underlying model being much smaller.
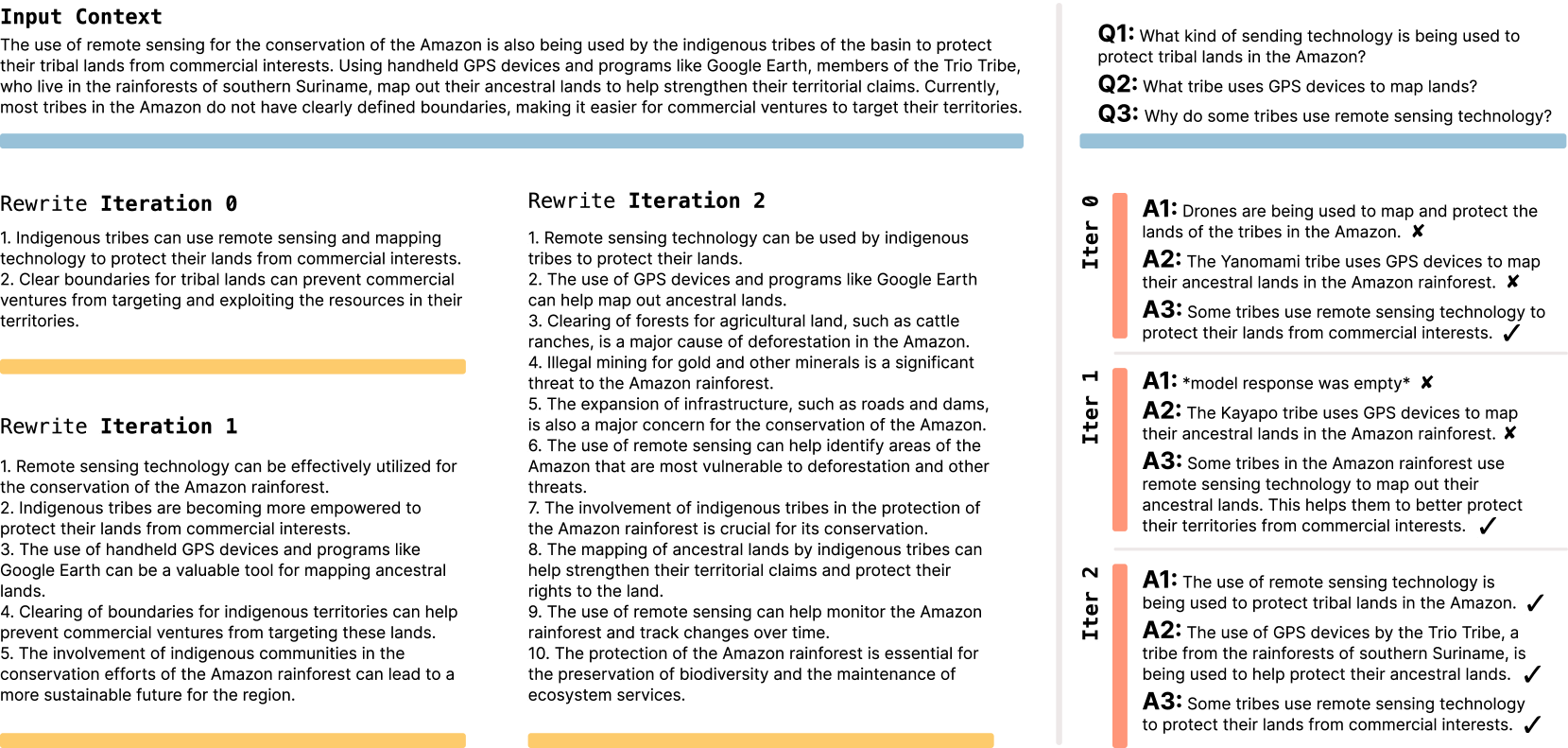
In a second test, the team looked at Few-Shot Prompting using Llama 3.2-1B on a reasoning task. Here, the model picked different data processing techniques and training parameters from a preset toolkit. With SEAL, the model achieved a 72.5 percent success rate, compared to just 20 percent without any prior training.
"Catastrophic forgetting" remains a challenge
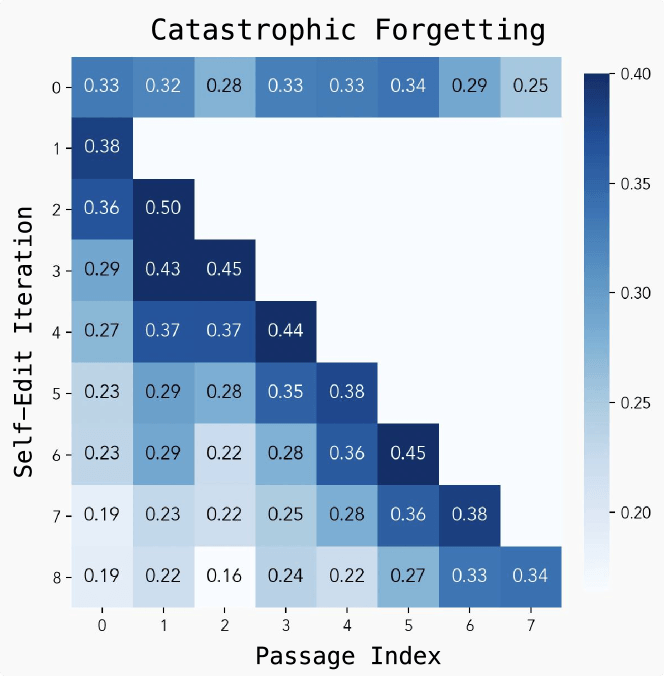
Despite the strong results, the researchers found several limits. The main issue is "catastrophic forgetting": when the model takes on new tasks, it starts to lose performance on previous ones. Training is also resource-intensive, since each evaluation of a self-edit takes 30 to 45 seconds.
Tackling the data wall
The MIT team sees SEAL as a step toward overcoming the so-called "data wall"—the point where all available human-written training data has been used up. Separately, researchers have also warned about the risk of "model collapse," where models degrade in quality when trained too heavily on low-quality AI-generated data. SEAL could enable ongoing learning and autonomous AI systems that keep adapting to new goals and information.
If models can teach themselves by absorbing new material—like scientific papers—and generating their own explanations and inferences, they could keep improving on rare or underrepresented topics. This kind of self-driven learning loop may help push language models past current limits.
The source code for SEAL is available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.