Microsoft’s MAI-DxO boosts AI diagnostic accuracy and cuts costs by nearly 70 percent
Microsoft has introduced a new AI system that could dramatically improve how complex medical cases are diagnosed, offering four times the diagnostic accuracy of experienced physicians while reducing costs. The technology was evaluated using a new benchmark designed to closely simulate the real, step-by-step diagnostic process.
Researchers at Microsoft AI unveiled the system in their paper "Sequential Diagnosis with Language Models", claiming the model significantly outperforms human doctors in both accuracy and cost-effectiveness for challenging cases.
To produce more realistic results, the team created the Sequential Diagnosis Benchmark (SDBench). Traditional medical AI tests, the authors argue, often overstate model performance by presenting all information at once, rather than mimicking the sequential nature of clinical decision-making.
SDBench draws on 304 complex case reports from the New England Journal of Medicine (NEJM). At the start, a human or AI diagnostician receives only a brief case summary and must actively request more information by asking targeted questions or ordering tests. A "gatekeeper" model only reveals the requested details and, according to the paper, can even generate realistic synthetic test results for procedures not described in the original case, preventing accidental hints.
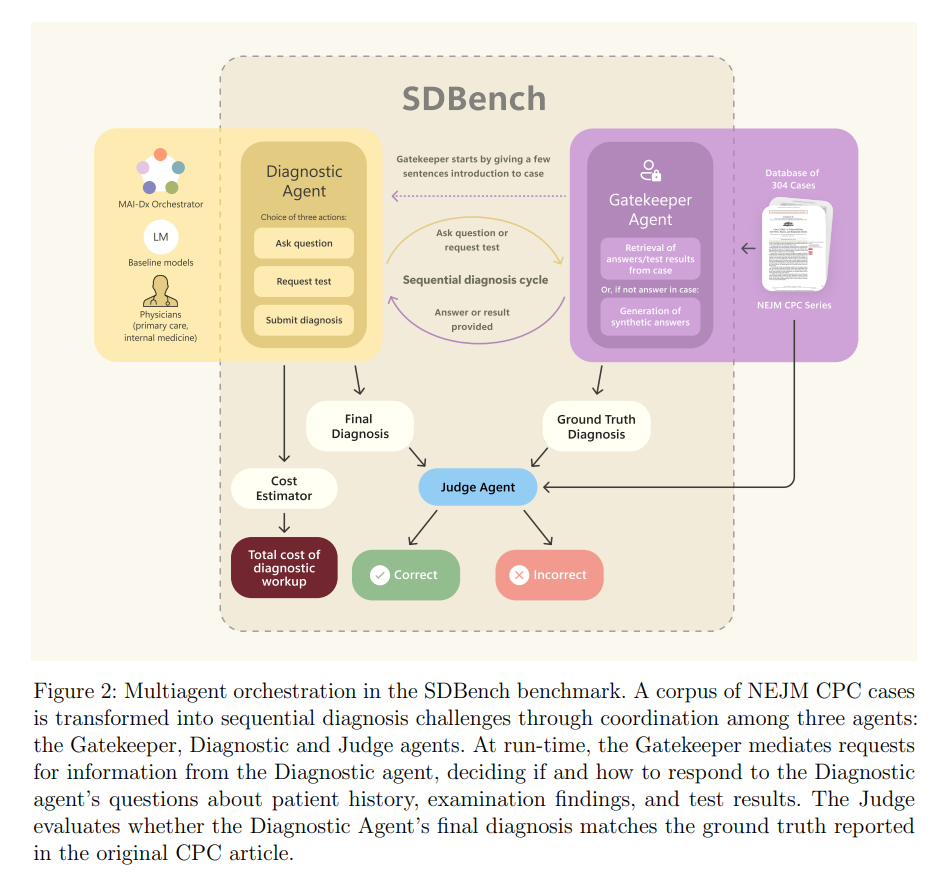
Costs are calculated as the sum of all tests and doctor visits. Each round of patient questioning is priced at $300 for a doctor consultation. Specific test costs are determined by mapping requests to standardized CPT codes and matching them against a 2023 price list from a major US health system.

In testing, a group of 21 experienced physicians from the US and UK achieved a diagnostic accuracy of 19.9 percent at an average cost of $2,963 per case. By comparison, Microsoft's "MAI Diagnostic Orchestrator" (MAI-DxO), combined with OpenAI's o3 model, reached 79.9 percent accuracy at a lower average cost of $2,397.
The major advance with MAI-DxO is the reduction in cost. On its own, the o3 model achieved the highest accuracy among standard models at 78.6 percent, but at an average cost of $7,850 per case. With MAI-DxO orchestrating the process, accuracy rose slightly while costs dropped by nearly 70 percent.
Virtual medical team boosts performance
According to the paper, MAI-DxO succeeds by simulating a virtual panel of doctors, all roles played by a single language model. "Dr. Hypothesis" maintains a list of likely diagnoses, "Dr. Test-Chooser" picks the most informative tests, and "Dr. Challenger" acts as a devil's advocate to prevent cognitive bias. "Dr. Stewardship" monitors costs, while "Dr. Checklist" ensures quality control.
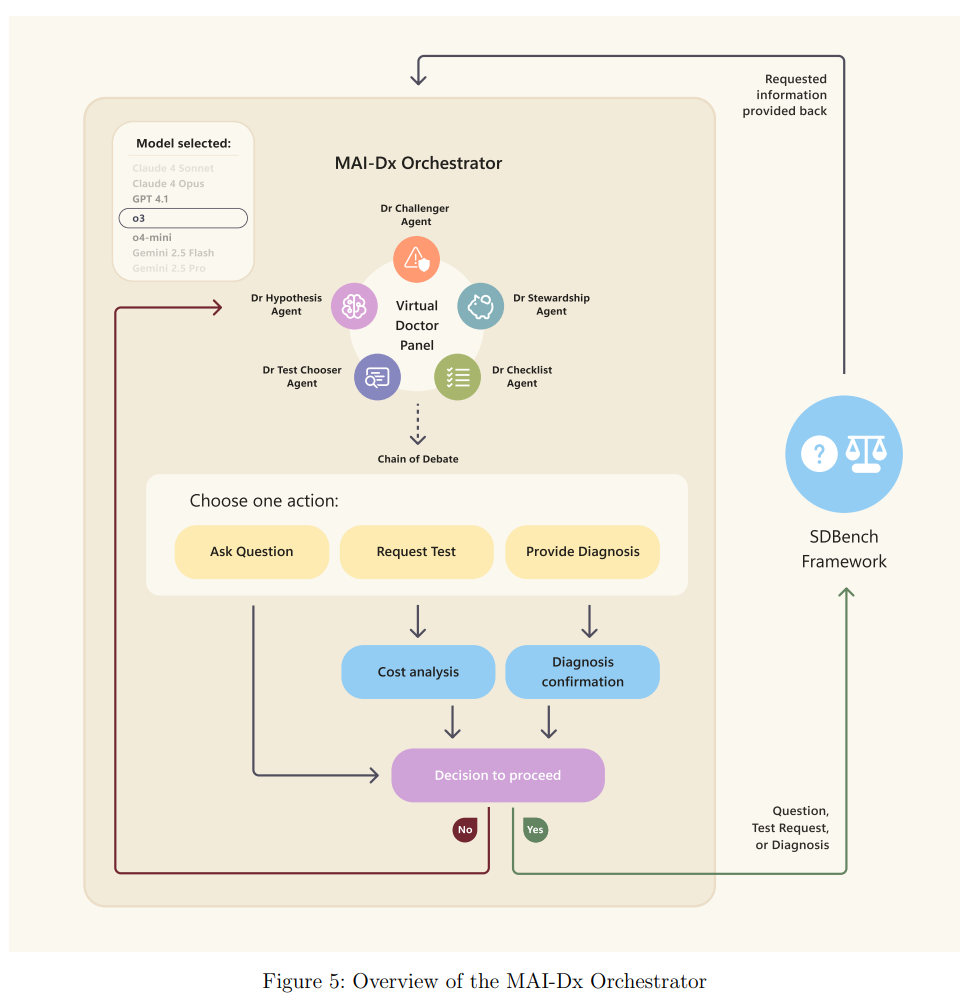
The structured approach is designed to prevent the system from anchoring on an early hypothesis. In one example, a standard language model incorrectly suspected antibiotic toxicity, ordered $3,431 in tests, and made a wrong diagnosis. MAI-DxO, by asking targeted questions about toxin exposure, correctly identified hand sanitizer ingestion as the cause for just $795.
Limitations and open questions
The authors acknowledge several limitations. SDBench is based exclusively on complex, teaching-oriented NEJM cases, so it does not reflect the distribution of diseases seen in everyday practice and excludes healthy patients or benign conditions. It remains unclear if the system's performance gains would translate to common, routine illnesses.
The cost calculations are only rough estimates, based on US prices and not accounting for real-world factors like geography, insurance, test invasiveness, wait times, or equipment availability.
The comparison with human physicians is also limited. The participating doctors were general practitioners, who would typically refer such complex cases to specialists, and they were not allowed to use external resources like search engines or medical literature. The authors note that the system's "superhuman" performance is partly due to its ability to combine the broad knowledge of a generalist with the deep expertise of multiple specialists - a combination that would be unrealistic for any single human.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.