Google’s Gemini 2.5 now supports "conversational image segmentation"

Google has introduced a new feature for its Gemini 2.5 AI model that allows users to analyze and highlight image content directly through natural language prompts.
This "conversational image segmentation" goes beyond traditional image segmentation, which typically identifies objects using fixed categories like "dog," "car," or "chair." Now, Gemini can understand more complex language and apply it to specific parts of an image. The model handles relational queries such as "the person with the umbrella," logic-based instructions like "all people who are not sitting," and even abstract concepts such as "clutter" or "damage" that don't have a clear visual outline. Gemini can also identify image elements that require reading on-screen text - for example, "the pistachio baklava" in a display case - thanks to built-in text recognition. The feature supports multilingual prompts and can provide object labels in other languages, such as French, if needed.
Practical applications
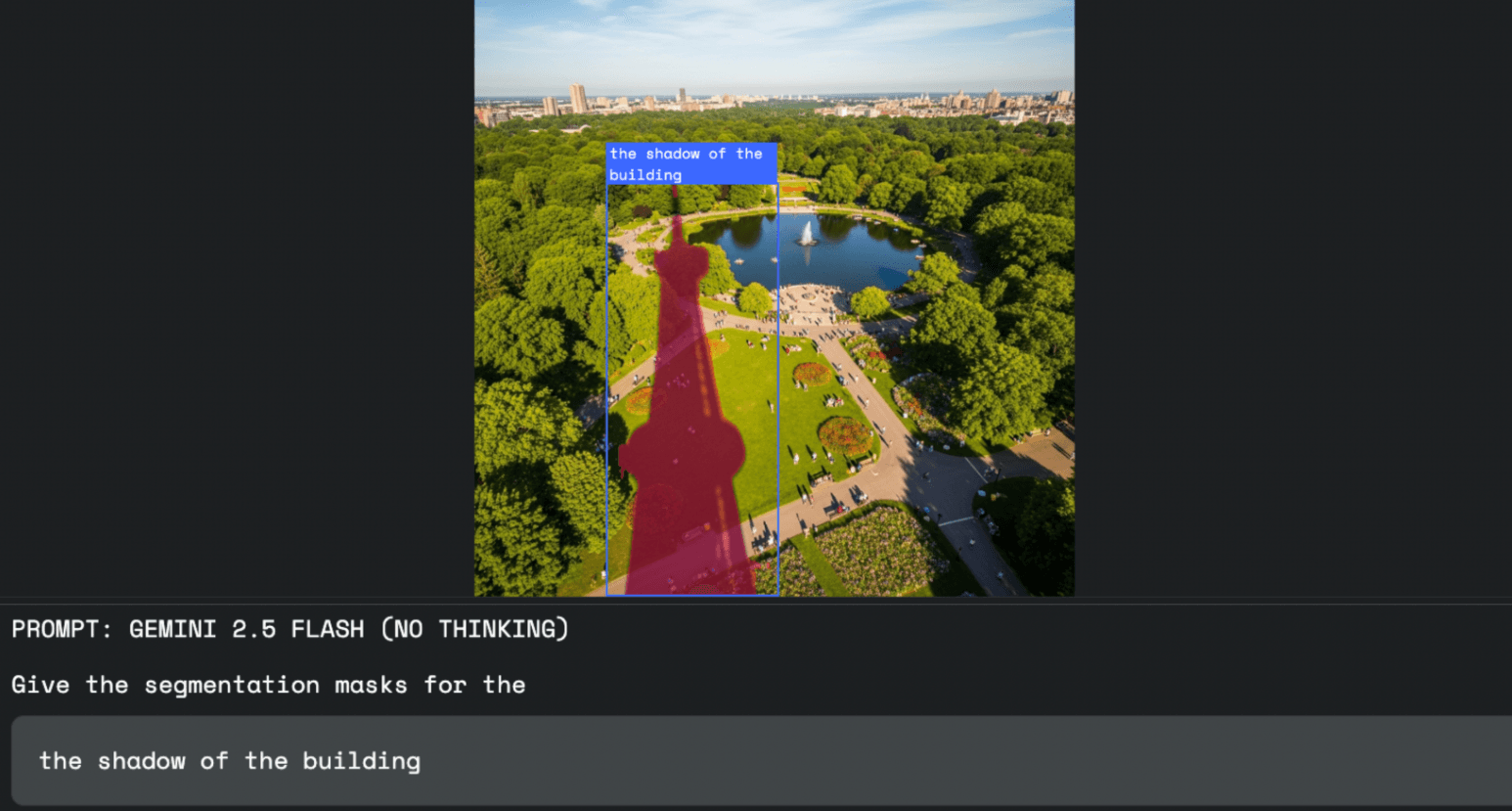
According to Google, this technology can be used in a range of fields. In image editing, for example, designers no longer need to use a mouse or selection tools; they can simply say what they want to select, such as "select the building's shadow."
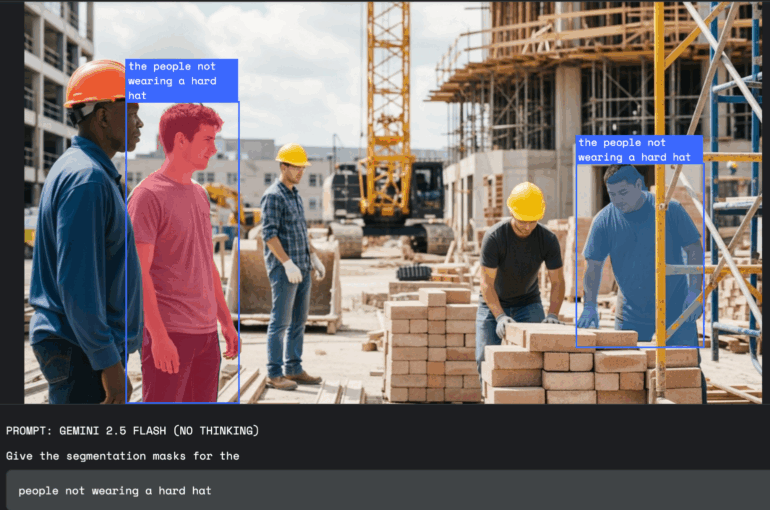
For workplace safety, Gemini can scan photos or videos for violations, like "all people on the construction site without a helmet."
The feature is also useful in insurance: an adjuster could issue a command like "highlight all houses with storm damage" to automatically tag damaged buildings in aerial images, saving time compared to checking each property manually.
No special models required
Developers can access the feature through the Gemini API. All requests are handled directly by the Gemini model, which is equipped with this capability.
Results are returned in JSON format, including the coordinates of the selected image area (box_2d), a pixel mask (mask), and the descriptive label (label).
For best results, Google recommends using the gemini-2.5-flash model and setting the "thinkingBudget" parameter to zero to trigger an immediate response.
Initial tests are possible via Google AI Studio or Python Colab.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.