GPT-5 dominated 210 Werewolf games with superior manipulation and strategic thinking

French startup Foaster.ai built a new benchmark to test how well AI models handle social interactions. After 210 games of "Werewolf," GPT-5 came out on top by mastering manipulation and strategic thinking.
"Werewolf" was picked because it pushes models beyond facts and math, requiring logical reasoning, bluffing, targeted deception, and adaptability to unpredictable situations, skills that most standard AI benchmarks don't capture. The benchmark measures how well language models can adapt to dynamic, interactive environments. While factual knowledge and mathematical reasoning play a role, the main focus is on social intelligence.
Each game followed a set structure: six AI models played different roles—two werewolves and four villagers with special abilities like seer and witch. A mayor was elected before play began. The models moved through three discussion-based day rounds and hidden night phases, where they could analyze, attack, or defend. Every pair of models played ten games per role, and Elo rankings were used for evaluation.

GPT-5's deception stays consistent
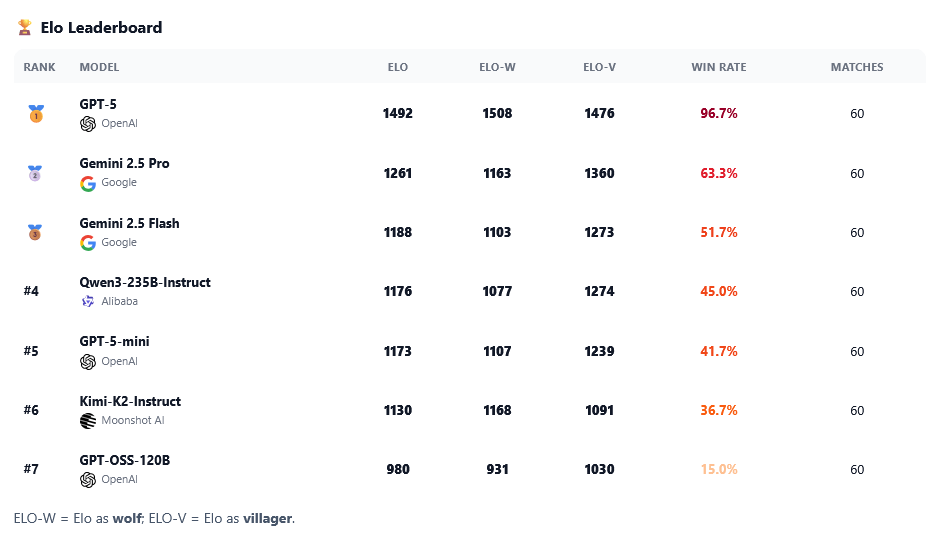
GPT-5 scored 1,492 Elo points, winning 96.7 percent of games. As a werewolf, it kept a steady manipulation rate of 93 percent over both the first and second days. No other model managed to maintain this level of deceptive performance throughout the game.
Other models fell apart as games progressed. Google's Gemini 2.5 Pro dropped from 60 to 44 percent deception, while Kimi-K2 crashed from 53 to 30 percent. The researchers say this decline is due to the growing information density as the game progresses, which makes deception harder.
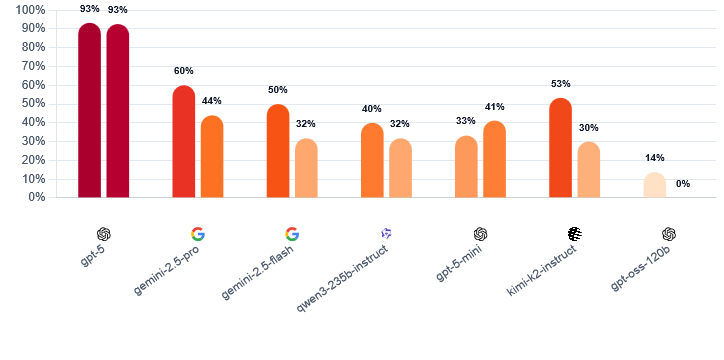
Yet Gemini 2.5 Pro excelled as a villager, using disciplined reasoning and strong self-defense. Overall, it took second place with 1,261 Elo points and 63.3 percent wins. Gemini 2.5 Flash followed at 1,188 Elo, then Qwen3-235B-Instruct from Alibaba at 1,176 Elo, GPT-5-mini at 1,173 Elo, and Kimi-K2-Instruct at 1,130 Elo. GPT-oss-120B finished last with 980 Elo and only 15 percent wins.
Foaster.ai observed that each model developed a distinct play style. GPT-5 played as a "calm and imperturbable architect," bringing order through controlled authority. GPT-oss-120B stayed hesitant and defensive. Kimi-K2 took wild risks, once falsely claiming to be the witch and getting the real witch eliminated.
The researchers also noticed moments of spontaneous creativity. In one case, a werewolf sacrificed its own teammate to appear more trustworthy eventually. These kinds of strategic moves emerged from the models' in-game behavior, not from explicit programming.
Bigger doesn't mean better at social games
The study found that stronger models made better arguments, acted more strategically, and showed greater social intelligence. Still, improvements were not linear. Weaker models often played inconsistently, while more advanced ones developed clearer strategies.
The reasoning-label alone didn't ensure strong strategic play. OpenAI’s o3 model argued clearly, adjusted well to new information, and followed the rules, but the smaller o4-mini model remained rigid and struggled with the game’s changing dynamics, even when it made good individual arguments, according to the researchers.
Foaster.ai aims to use the Werewolf benchmark to push research on social intelligence in AI. The team sees potential use cases in multi-agent systems, negotiation, and collaborative decision-making. An expanded benchmark is already in the works.
Earlier studies found that emotional prompts can boost LLM performance, and older OpenAI models beat humans at empathy tests. The new benchmark adds more evidence that AI models are increasingly capable as social actors—with all the opportunities and risks that brings.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.