Open ASR Leaderboard tests more than 60 speech recognition models for accuracy and speed

A research group from Hugging Face, Nvidia, the University of Cambridge, and Mistral AI has released the Open ASR Leaderboard, an evaluation platform for automatic speech recognition systems.
The leaderboard is meant to provide a clear comparison of open source and commercial models. According to the project's study, more than 60 models from 18 companies have been tested so far. The evaluation covers three main categories: English transcription, multilingual recognition (German, French, Italian, Spanish, and Portuguese), and long audio files over 30 seconds. The last category highlights how some systems perform differently on long versus short recordings.
Two main benchmarks are used:
- Word Error Rate (WER) measures the number of incorrect words. Lower is better.
- Inverse Real-Time Factor (RTFx) measures speed. For example, an RTFx of 100 means one minute of audio is transcribed in 0.6 seconds.
To keep comparisons fair, transcripts are normalized before scoring. The process removes punctuation and capitalization, spells out numbers, and drops filler words like "uh" and "mhm." This matches the normalization standard used by OpenAI's Whisper.
Accuracy vs. speed
The leaderboard shows clear differences between model types in English transcription. Systems built on large language models deliver the most accurate results. Nvidia's Canary Qwen 2.5B leads with a WER of 5.63 percent.
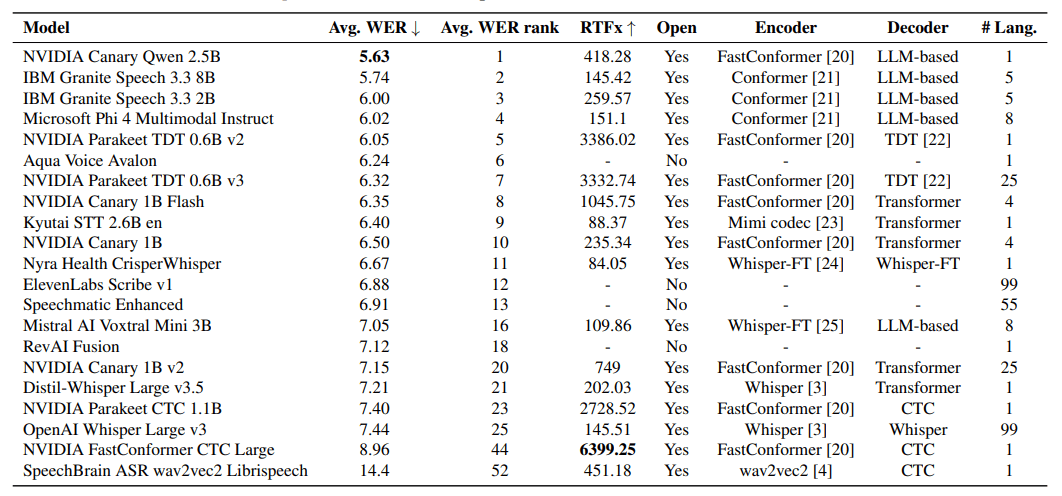
However, these accurate models are slower to process audio. Simpler systems, like Nvidia's Parakeet CTC 1.1B, transcribe audio 2,728 times faster than real time, but only rank 23rd in accuracy.
Multilingual models lose some specialization
Tests across several languages show a trade-off between versatility and accuracy. Models narrowly trained on one language outperform broader multilingual models for that language, but struggle with others. Whisper models trained only on English beat the multilingual Whisper Large v3 at English, but can't reliably transcribe other languages.
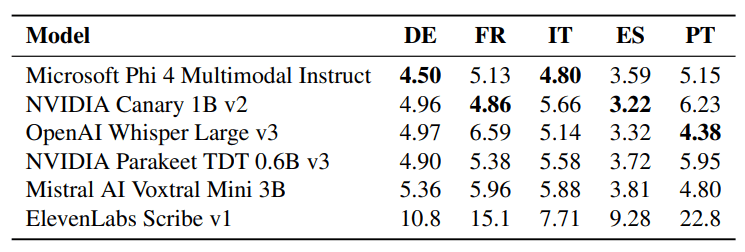
In multilingual tests, Microsoft's Phi-4 multimodal instruct leads in German and Italian. Nvidia's Parakeet TDT v3 covers 25 languages, while v2 supports just one, but the wider model performs worse on English than the specialized version.
Open source outperforms commercial models on short audio
Open source models take the top spots for short audio. The highest-ranking commercial system, Aqua Voice Avalon, is sixth. Speed comparisons for paid services aren't fully reliable, since upload times and other factors can distort results.
For longer audio, commercial providers do better. Elevenlabs Scribe v1 (4.33 percent WER) and RevAI Fusion (5.04 percent) top the list, likely due to targeted optimization for long-form content and stronger infrastructure.
The entire leaderboard and codebase are available on GitHub. Developers can submit new models by providing scripts that run on the official test set. The datasets are hosted on the Hugging Face Hub and can be explored directly online.
The team plans to add more languages, applications, and metrics in future updates, including new combinations of system components that haven't been widely tested. As large language models become more common, the expectation is that even more speech recognition systems will adopt this technology.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.