Human-aligned AI models prove more robust and reliable

A team from Google Deepmind, Anthropic, and German researchers has introduced a method that helps AI models better mirror how people judge what they see. Their Nature study finds that AI models aligned with human perception are more robust, generalize better, and make fewer errors.
Deep neural networks can match humans at some visual tasks, but break down in unfamiliar situations. According to the study, the problem is structural: People organize visual concepts in a hierarchy, from fine details up to broader categories. AI models, on the other hand, focus on local similarities and often miss abstract connections.
This difference shows up in important ways. People might group a dog and a fish together as "living," even though they look nothing alike. AIs don’t make these leaps. When it comes to confidence, humans are usually only as certain as they are accurate, but AIs can be very confident even when they’re wrong.

AligNet: Narrowing the gap between AI and human perception
To close this gap, Lukas Muttenthaler and his team built AligNet. The core of their approach is a "surrogate teacher model," a version of the SigLIP multimodal model fine-tuned on human judgments from the THINGS dataset.
This teacher model generates “pseudo-human” similarity scores for millions of synthetic ImageNet images. These labels then help fine-tune a range of vision models, including Vision Transformers (ViT) and self-supervised systems like DINOv2. AligNet-aligned models ended up matching human judgments much more often, especially on abstract comparison tasks.
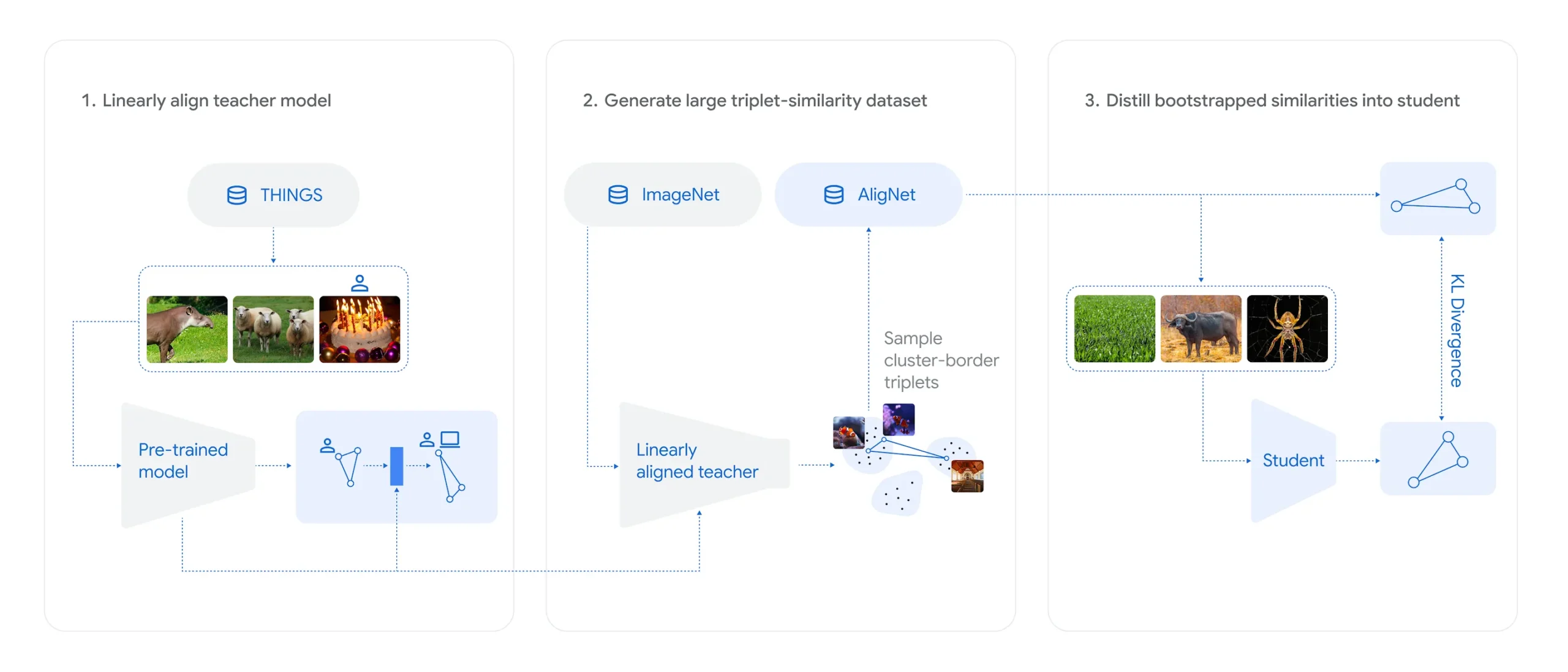
On the new "Levels" dataset, which covers different abstraction levels and includes ratings from 473 people, an AligNet-tuned ViT-B model even outperformed the average agreement among humans.
How human-like structure boosts model robustness
Aligning with human perception didn’t just make the models more "human" - it made them technically better. In generalization and robustness tests, AligNet models sometimes more than doubled their accuracy over baseline versions.
They also held up better on challenging tests like the BREEDS benchmark, which forces models to handle shifts between training and test data. On adversarial ImageNet-A, accuracy jumped by up to 9.5 percentage points. The models also estimated their own uncertainty more realistically, with confidence scores tracking closely to human response times.
The models also reorganized their internal representations. After alignment, they grouped objects by meaning, not just by looks - lizards, for example, moved closer to other animals, not just to plants of the same color.
According to Muttenthaler and colleagues, this approach could point the way toward AI systems that are easier to interpret and trust. Bringing human-like similarity structures into foundation models could make them more stable when faced with new situations. However, the researchers caution that perfect human-likeness isn't the goal - after all, human judgments are influenced by cultural and personal biases.
All training data and models from the AligNet project are openly available.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.