General Agentic Memory tackles context rot and outperforms RAG in memory benchmarks

A research team from China and Hong Kong has developed a new memory architecture for AI agents designed to minimize information loss during long interactions.
Memory remains one of the biggest weaknesses for current AI agents. When conversations or tasks drag on, models hit their context window limits or lose track of details—a phenomenon also known as "context rot."
In a new paper, the scientists introduce "General Agentic Memory" (GAM) as a solution. The system combines data compression with a deep research mechanism, applying the principle of "just-in-time compilation" to AI memory, a software development process where code is optimized only at the moment of execution.
While previous approaches rely on static summaries created in advance, the researchers argue this inevitably causes information loss. Details that seem unimportant when stored might be crucial later, but by then, they have already been compressed away.
A dual-agent architecture
GAM uses a dual architecture consisting of two specialized components: a "Memorizer" and a "Researcher." The Memorizer runs in the background during interactions. While it creates simple summaries, it also archives the full conversation history in a database called the "page store." It segments the conversation into pages and tags them with context to make retrieval easier.
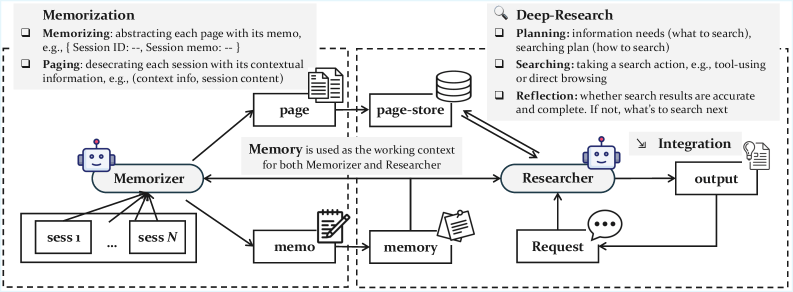
The Researcher activates only when the agent receives a specific request. Instead of simply looking up memory, it conducts "deep research"—analyzing the query, planning a search strategy, and using tools to dig through the page store. It uses three methods: vector search for thematic similarities, BM25 search for exact keywords, or direct access via page IDs. The process is iterative. The agent verifies its search results and reflects on whether the information is sufficient. If necessary, it starts new queries before generating an answer.
Outperforming RAG and long-context models
The team tested GAM against conventional methods like Retrieval-Augmented Generation (RAG) and models with massive context windows like GPT-4o-mini and Qwen2.5-14B.
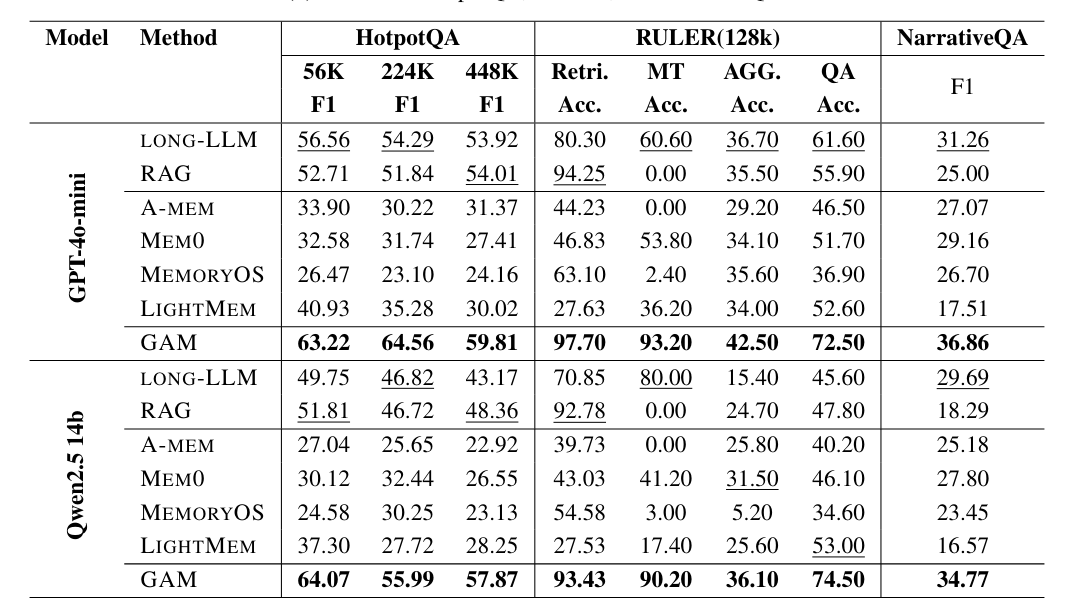
According to the paper, GAM beat the competition in every benchmark. The gap was widest in tasks requiring information linking over long periods. In the RULER benchmark, which tracks variables over many steps, GAM hit over 90 percent accuracy while conventional RAG approaches and other storage systems largely failed.
The researchers believe GAM succeeds because its iterative search finds hidden details that compressed summaries miss. The system also scales well with compute: allowing the Researcher more steps and reflection time further improves answer quality.
The project's code and data are available on GitHub.
New approaches to context management
Other labs are also tackling the memory problem. Anthropic recently shifted focus to "context engineering," actively curating the entire context state through compact summaries or structured notes rather than just optimizing prompts.
Similarly, Deepseek introduced a new OCR system that processes text documents as highly compressed images. This approach saves significant compute and tokens, potentially serving as efficient long-term storage for chatbots by saving older conversation segments as image files.
Meanwhile, researchers in Shanghai have proposed a "Semantic Operating System" designed to act as a lifelong memory for AI. This system would manage context like a human brain, selectively adapting and forgetting knowledge to turn transient information into permanent, structured memories.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.