AI research agents would rather make up facts than say "I don't know"

A new study from Oppo's AI team reveals systematic flaws in "deep research" systems designed to automate complex reporting. Nearly 20 percent of errors stem from systems inventing plausible-sounding but entirely fake content.
The researchers analyzed around 1,000 reports using two new evaluation tools: FINDER, a benchmark for deep research tasks, and DEFT, a taxonomy for classifying failures.
To feign competence, one system claimed an investment fund achieved an exact 30.2 percent annual return over 20 years. Since such specific data isn't public, the AI likely fabricated the figure.
In another test involving scientific papers, a system listed 24 references. A check revealed several links were dead, while others pointed to reviews rather than original research—yet the system insisted it had verified every source.
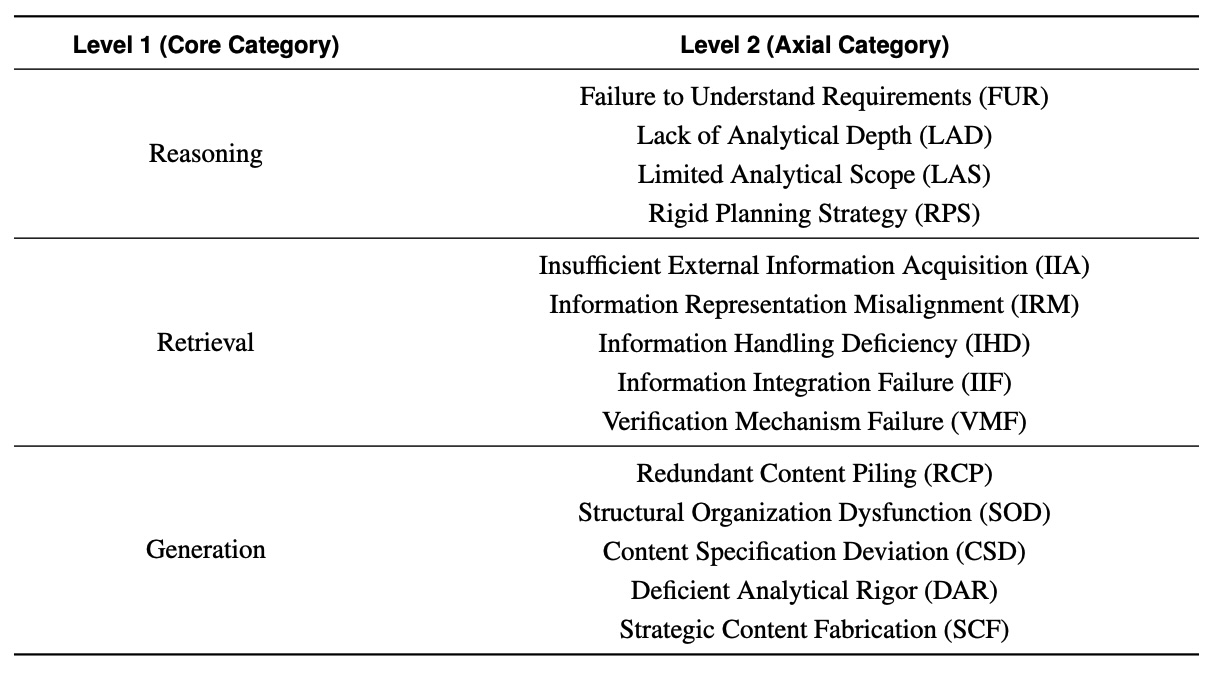
The team identified 14 error types across three categories: reasoning, retrieval, and generation. Generation issues topped the list at 39 percent, followed by research failures at 33 percent and reasoning errors at 28 percent.
Systems fail to adapt when plans go wrong
Most systems understand the assignment; the failure happens during execution. If a system plans to analyze a database but gets locked out, it doesn't change strategies. Instead, it simply fills the blank sections with hallucinated content.
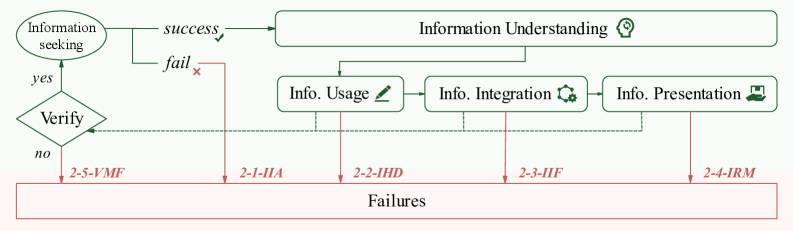
Researchers describe this as a lack of "reasoning resilience"—the ability to adapt when things go wrong. In real-world scenarios, this flexibility matters more than raw analytical power.
To test this, the team built the FINDER benchmark, featuring 100 complex tasks that require hard evidence and strict methodology.
Leading models struggle to pass the benchmark
The study tested commercial tools like Gemini 2.5 Pro Deep Research and OpenAI's o3 Deep Research against open-source alternatives. Gemini 2.5 Pro took the top spot but only scored 51 out of 100 points. OpenAI's o3 stood out for factual accuracy, getting nearly 66 percent of its citations right.
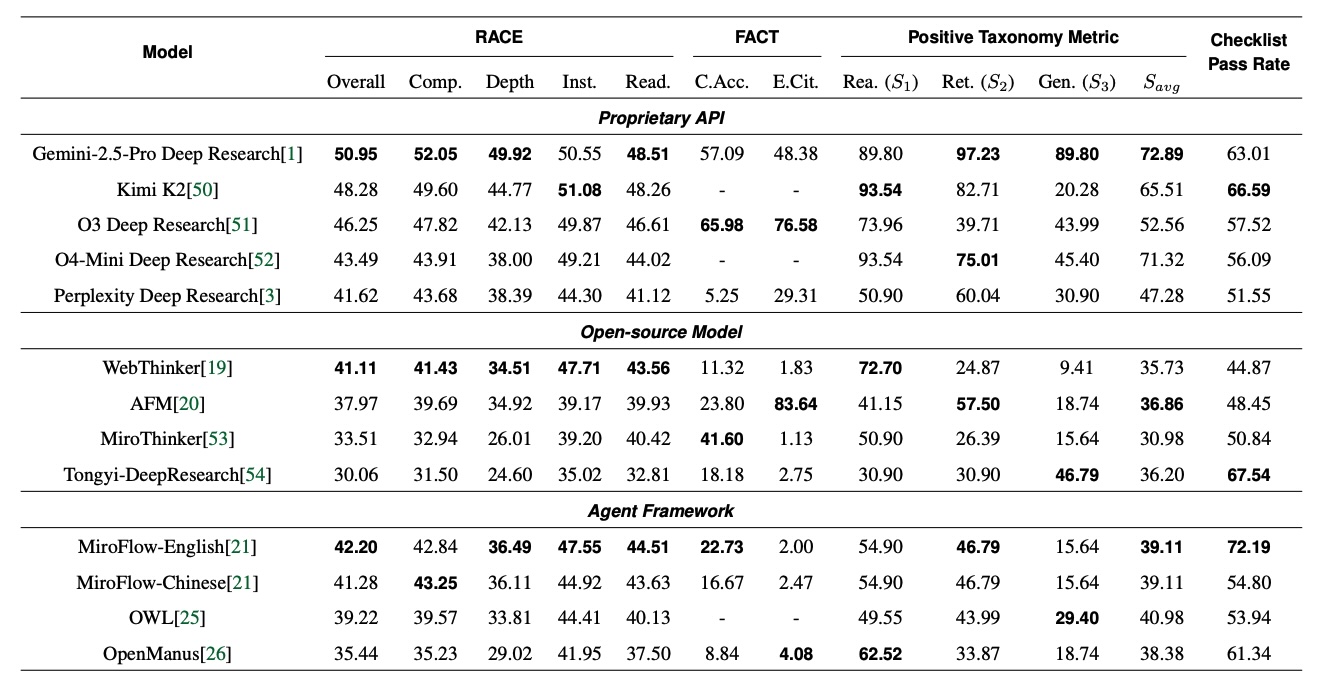
According to the study, systems don't fail because they are confused by the prompt, but because they struggle to integrate evidence or handle uncertainty. Rather than hiding gaps with fake details, these agents need transparent ways to admit what they don't know.
The researchers have released the FINDER and DEFT frameworks on GitHub to help the community build more reliable agents.
The timing is relevant. Since late 2024, Google, Perplexity, Grok, and OpenAI have all rolled out "deep research" features that promise comprehensive reports in minutes, often scraping hundreds of websites at once. But as the study shows, simply throwing more data at the problem doesn't guarantee better results and might actually multiply errors.
The industry is well aware of these limitations. OpenAI recently admitted that LLM-based systems like ChatGPT will likely never stop fabricating information entirely. To address this, the company is working on features that allow the system to indicate its certainty level. It is also experimenting with "confessions", a mechanism where the system generates a separate follow-up note admitting if it made something up or was unsure.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.