The "curse of knowledge" means smarter AI models don't understand where human learners struggle

Large language models can ace exam questions that stump human students, but they have no idea why those questions are hard in the first place. A new study exposes a fundamental blind spot in how AI perceives difficulty.
A research team from several US universities tested whether LLMs can assess exam question difficulty from a human perspective. They evaluated more than 20 language models, including GPT-5, GPT-4o, various Llama and Qwen variants, and specialized reasoning models like Deepseek-R1.
The models were asked to estimate how difficult exam questions would be for humans. For comparison, the researchers used actual difficulty ratings from field tests with students across four domains: USMLE (medicine), Cambridge (English), SAT Reading/Writing, and SAT Math.
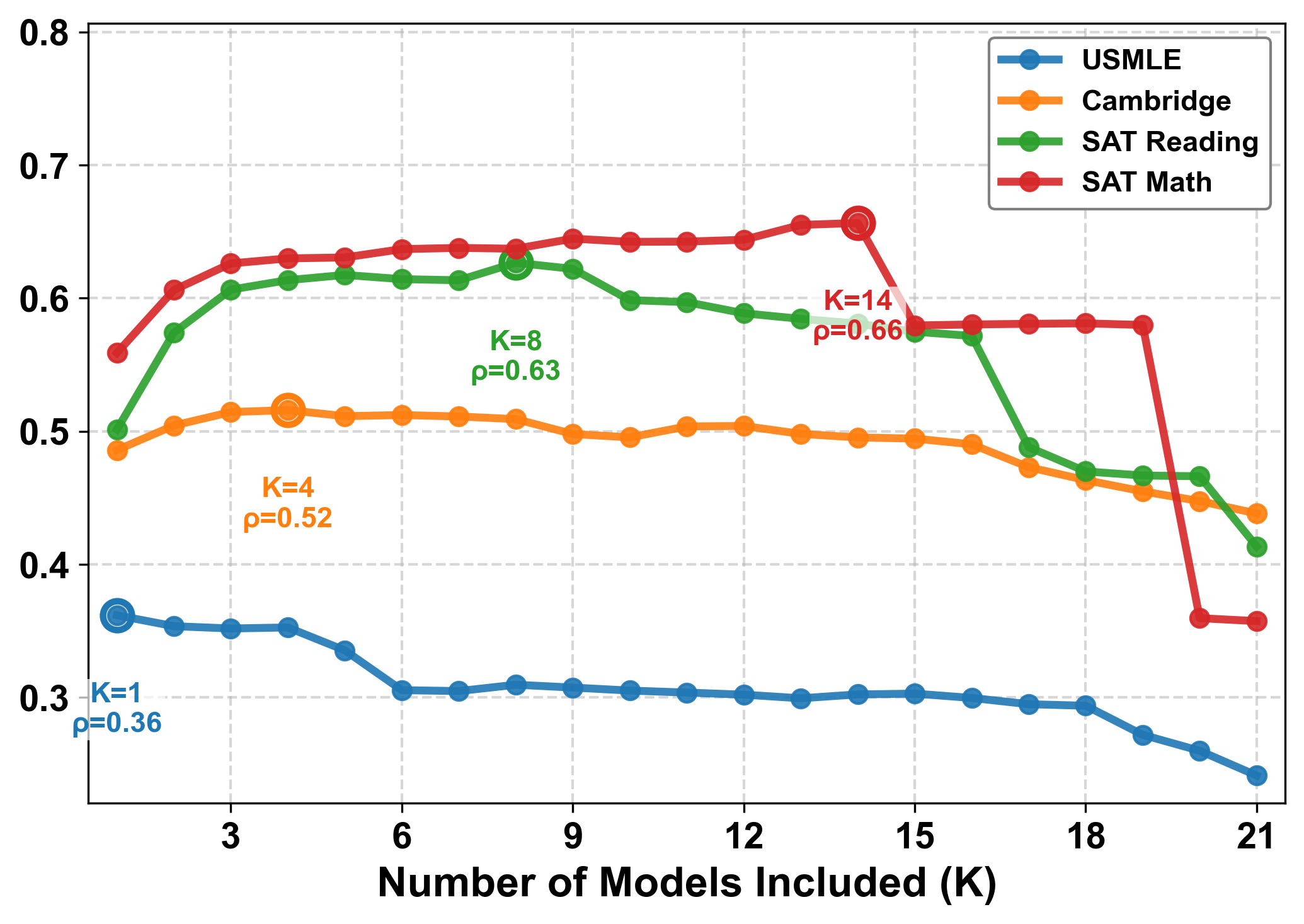
The verdict: AI assessments barely matched human perception. The researchers measured this using Spearman correlation, a statistical measure showing how similarly humans and machines rank questions from "easy" to "difficult." A score of 1 means perfect agreement; 0 means no correlation. On average, the models scored below 0.50. Newer or larger models didn't automatically perform better: GPT-5 scored just 0.34, while the older GPT-4.1 did significantly better at 0.44.
Being too smart to understand struggle
The researchers call the core problem the "curse of knowledge": the models are simply too capable to replicate the struggles of weaker learners. Questions that trip up medical students pose no challenge for these systems, so they can't tell where humans stumble. On the US medical licensing exam, most models breezed through precisely the tasks that human test-takers failed most often.
The researchers also tried prompting models to role-play as weak, average, or strong students. It didn't work. Accuracy barely budged, typically shifting by less than one percentage point. The models can't dial down their own abilities. They keep finding the right answers and fail to reproduce the mistakes weaker learners typically make.
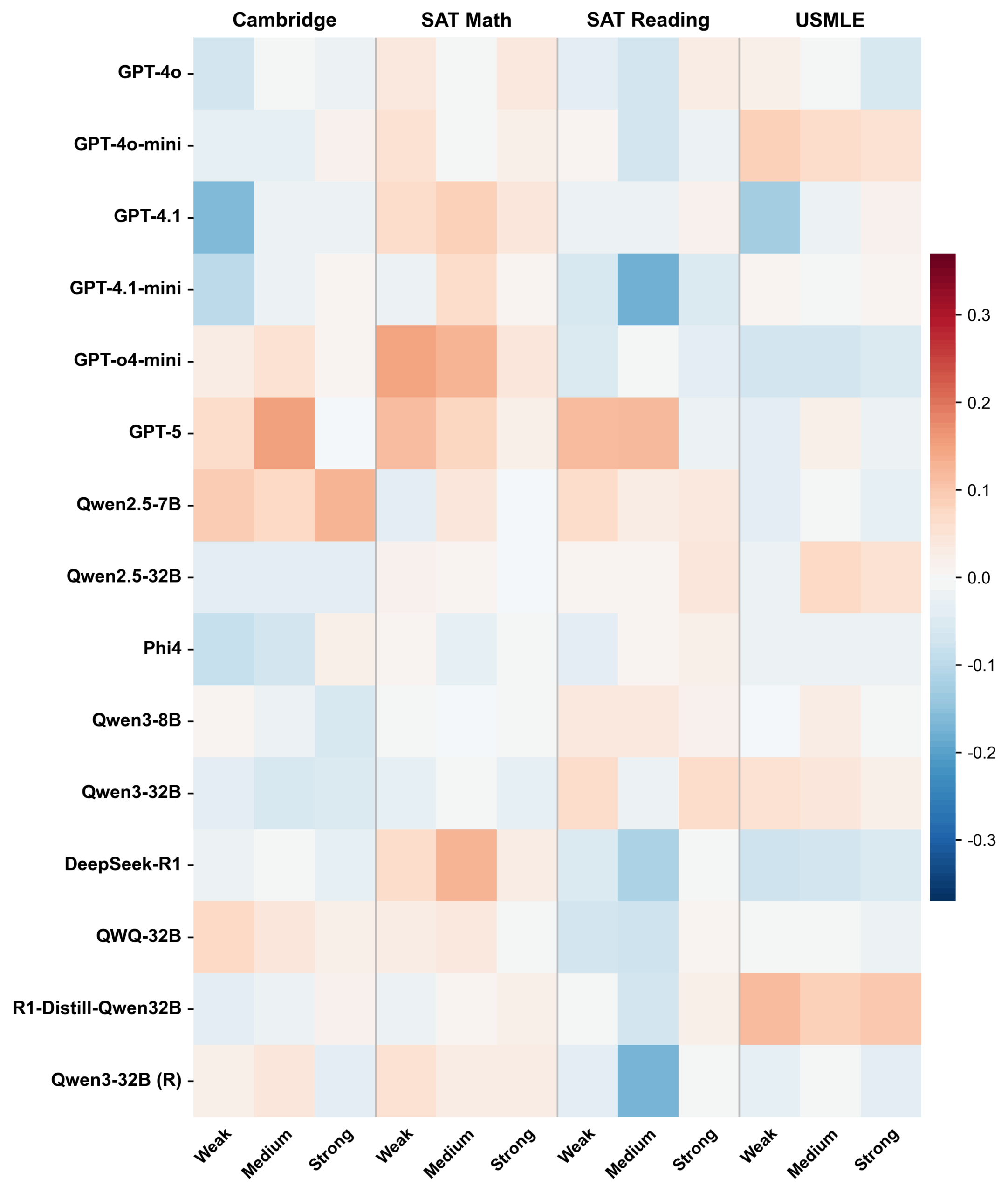
The study also uncovered a lack of self-awareness. If a model rates a question as hard, it should get it wrong more often. But the results were barely above chance. Even GPT-5 can't reliably predict which tasks it will fail. Difficulty estimates and actual performance are completely disconnected. The models simply lack the self-reflection to recognize their own limitations, the authors argue.
Instead of approximating human perception, the models develop their own shared assessment. They agree more with each other than with human data—a "machine consensus" that systematically diverges from reality. The models consistently underestimate difficulty, clustering their predictions in a narrow low range while actual difficulty values spread much wider. Previous studies have also shown that AI models tend to form consensus, whether they're right or wrong.
What this means for AI in education
Accurately assessing task difficulty is fundamental to educational testing. It shapes curriculum design, automated test creation, and adaptive learning systems. Until now, this has required extensive field testing with real students. The hope was that language models could take over.
The study puts a damper on that idea. Solving problems isn't the same as understanding why humans struggle with them. Making AI work in education will require approaches beyond simple prompting, the researchers suggest. One option: training models on student error data to bridge the gap between machine capability and human learning.
OpenAI's own usage data confirms AI's growing role in education. In a ranking of the most popular use cases in Germany, "writing and editing" topped the list, with "tutoring and education" close behind.
Former OpenAI researcher Andrej Karpathy recently called for a radical overhaul of the education system. His argument: schools should assume any work done outside the classroom involved AI assistance, since detection tools don't work reliably. Karpathy pushed for a "flipped classroom" model where exams happen at school and knowledge acquisition with AI help happens at home. The goal is dual competence: students should know how to work with AI, but also function without it.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.