New Artificial Analysis benchmark shows OpenAI, Anthropic, and Google locked in a three-way tie at the top
Artificial Analysis just released version 4.0 of its Intelligence Index, ranking AI models across multiple benchmarks. OpenAI's GPT-5.2 at its highest reasoning setting takes the top spot, with Anthropic's Claude Opus 4.5 and Google's Gemini 3 Pro close behind.
The index scores models across four equally weighted categories: Agents, Programming, Scientific Reasoning, and General. Results are less saturated this time, with top models peaking at 50 points compared to 73 in the previous version.
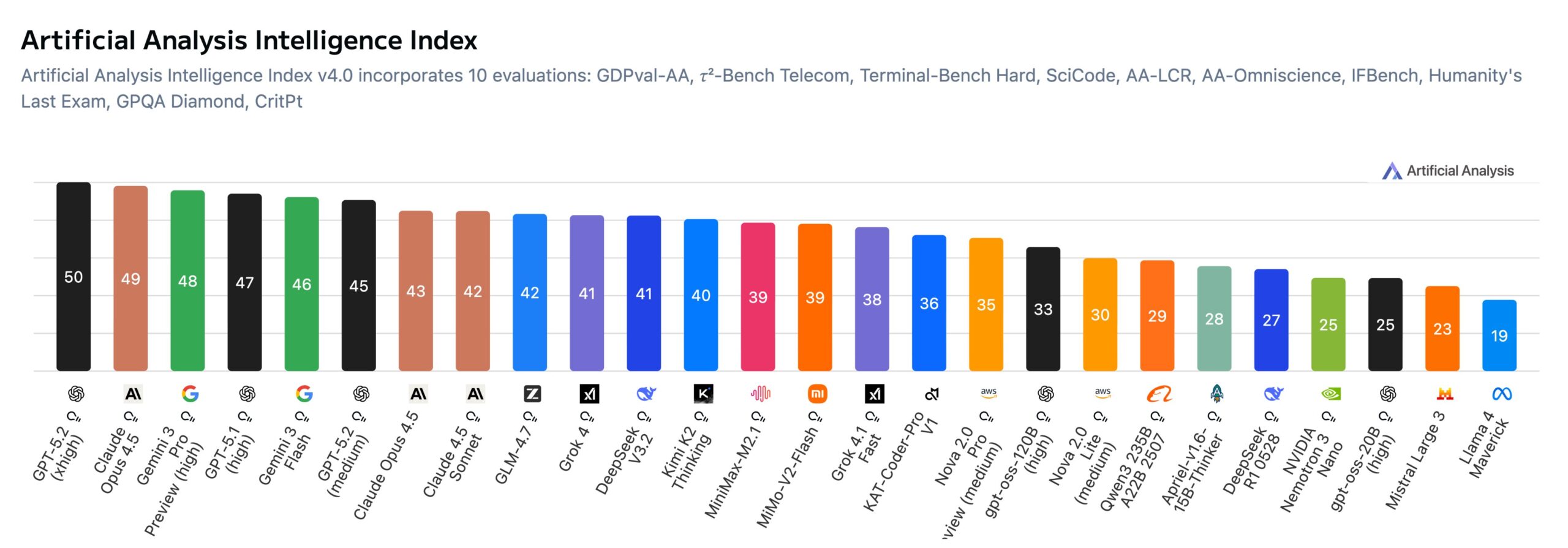
The updated index swaps three older tests (AIME 2025, LiveCodeBench, and MMLU-Pro) for a fresh set: AA-Omniscience checks model knowledge across 40 topics while flagging hallucinations, GDPval-AA tests models on practical tasks across 44 professions, and CritPt tackles physics research problems. Artificial Analysis says it ran all tests independently using a standardized approach, with full details available on its website.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.