New benchmark shows AI models still hallucinate far too often

A new benchmark from researchers in Switzerland and Germany shows that even top models like Claude Opus 4.5 with web search enabled still produce incorrect information in nearly a third of all cases.
Nvidia CEO Jensen Huang says LLMs don't hallucinate anymore, but science disagrees. Researchers from Switzerland's EPFL, the ELLIS Institute Tübingen, and the Max Planck Institute for Intelligent Systems have developed "Halluhard," a benchmark that measures hallucinations in realistic multi-turn conversations. The results tell a different story: hallucinations are still a major problem, even with web search enabled.
The benchmark covers 950 initial questions across four sensitive knowledge domains: legal cases, research questions, medical guidelines, and programming. For each initial question, a separate user model generated two follow-up questions, creating realistic three-turn conversations.
According to the study, even the best configuration tested, Claude Opus 4.5 with web search, still hallucinated in about 30 percent of cases. Without web search, that rate jumped to around 60 percent. GPT-5.2 Thinking with web search came in at 38.2 percent.
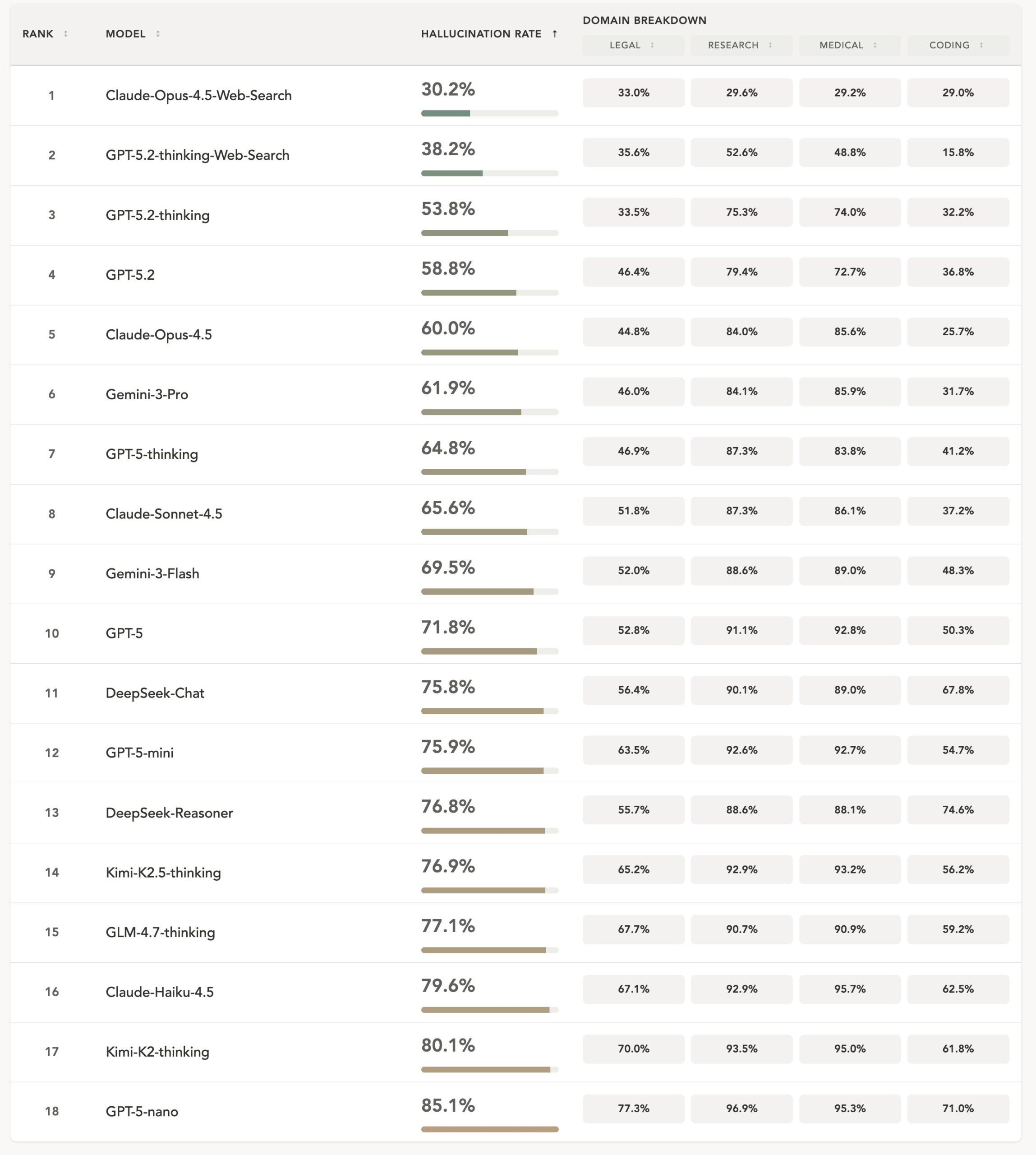
Chinese reasoning models like Kimi-K2-Thinking and GLM-4.7-Thinking fared the worst compared to their direct reasoning counterparts. What stands out is that these are open models that normally hold their own against top models in other benchmarks, raising the suspicion that they were specifically optimized for benchmark scores rather than real-world reliability.
Bigger models hallucinate less, but reasoning only helps so much
Larger models tend to hallucinate less often. Within the GPT-5 family, the average hallucination rate dropped from 85.1 percent for GPT-5-nano to 71.8 percent for GPT-5, and further to 53.8 percent for GPT-5.2 Thinking. Claude showed a similar pattern: 79.5 percent for Haiku, 65.6 percent for Sonnet, and 60 percent for Opus.
Reasoning, essentially "thinking longer" before answering, does reduce hallucinations, but throwing more compute at reasoning doesn't necessarily help. Models with more reasoning produced longer, more detailed answers with more claims, which in turn created more room for error.
Notably, DeepSeek Reasoner showed no improvement over DeepSeek Chat despite its reasoning capabilities. The researchers point to a persistent gap between proprietary and open-source models.
Web search cuts hallucinations but doesn't eliminate them
The researchers distinguish between two types of hallucinations. Reference grounding checks whether a cited source actually exists. Content grounding checks whether that source actually supports the claimed information.
This distinction reveals a subtle but common failure: a model can cite a legitimate source and still fabricate details the source doesn't support. As an example, the researchers point to a claim about the SimpleQA benchmark where the reference was correct but the content was partially made up.

Data from the research question domain shows that web search primarily reduces reference errors. For Claude Opus 4.5, the reference error rate dropped from 38.6 to 7 percent with web search. Content grounding errors, however, fell much less, from 83.9 to 29.5 percent. GPT-5.2 Thinking showed a similar pattern: reference errors dropped to 6.4 percent with web search, but content grounding errors stayed at 51.6 percent.
Longer conversations make hallucinations worse
One key finding is what happens over multiple conversation turns: hallucination rates increased in later rounds. The researchers explain this by noting that models receive the entire previous conversation as context, building on their own earlier mistakes. Between 3 and 20 percent of incorrect references from the first turn reappeared in later rounds. Previous studies have already shown that long chats and cluttered context windows degrade AI model performance.
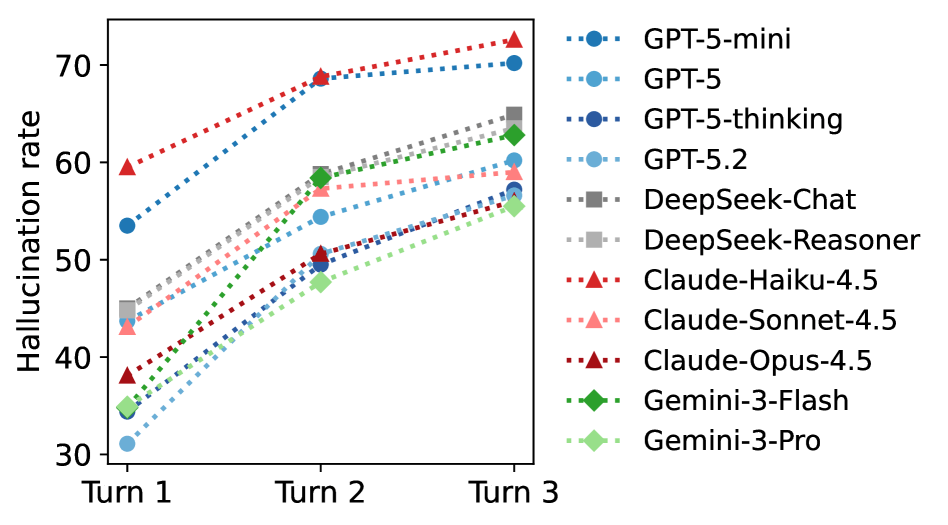
Coding tasks showed the opposite trend: hallucination rates actually decreased in later rounds. The researchers suspect this happens because tasks naturally get narrower as the conversation progresses, moving from broad requirements like "build X" to specific questions like "fix this function." Narrower tasks leave less room for creative but incorrect answers.
Niche knowledge is where models fail most
In a controlled experiment with 350 short questions, the researchers tested when models hallucinate and when they refuse to answer. When asked about completely fabricated entities, models tended to abstain. But with niche knowledge, like rarely cited research papers or artworks from local galleries, they hallucinated far more often.
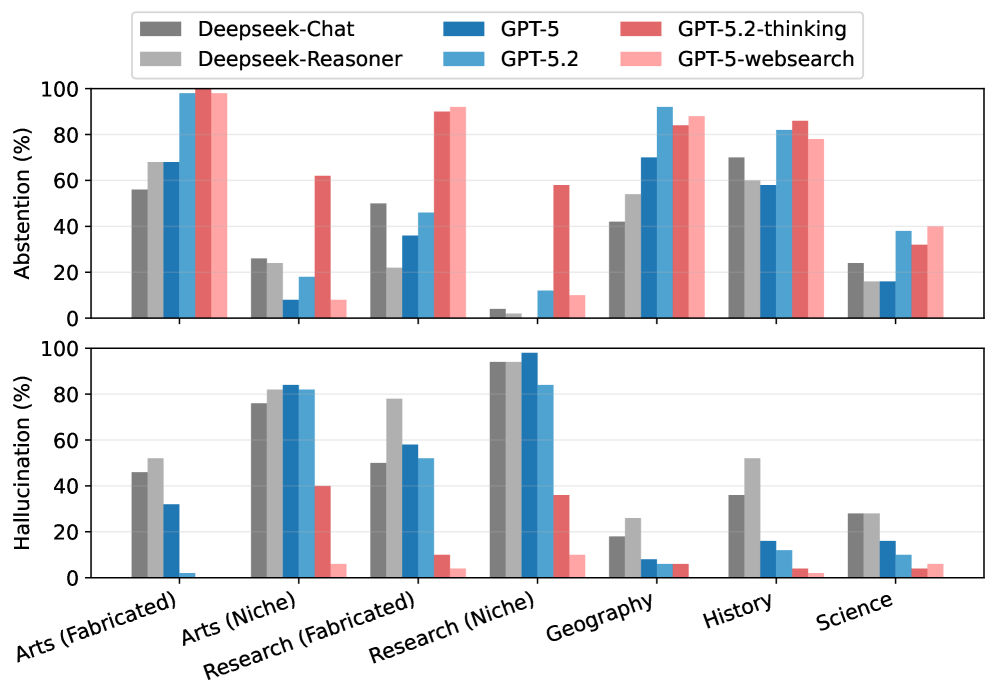
The researchers explain this by noting that niche information only appears in fragments during training. Those fragments are enough to trigger a response, but not a correct one. With completely unknown topics, there's at least a chance a model will admit it doesn't know.
Current benchmarks can't keep up with model progress
The researchers argue a new benchmark is needed because existing tests barely differentiate between models anymore. On SimpleQA, GPT-4o with Search Preview already hits 90 percent accuracy, and GPT-5 Thinking with web search reaches 95.1 percent. With an estimated benchmark error rate of around 3 percent, that's essentially the ceiling.
Halluhard is designed to stay challenging for future model generations by combining multi-turn conversations, sensitive knowledge domains, and niche knowledge. The benchmark and code are available on GitHub, and the results are also published on a project page.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.