Alibaba's free Qwen3.5 signals that China's open-weight model race is far from slowing down

Key Points
- Alibaba has released Qwen3.5 as an open-weight model, marking the first entry in its new model series.
- The model handles text, images, and up to two hours of video, packs 397 billion parameters with only 17 billion active per query, and runs up to 19 times faster than its predecessor Qwen3-Max, according to Alibaba.
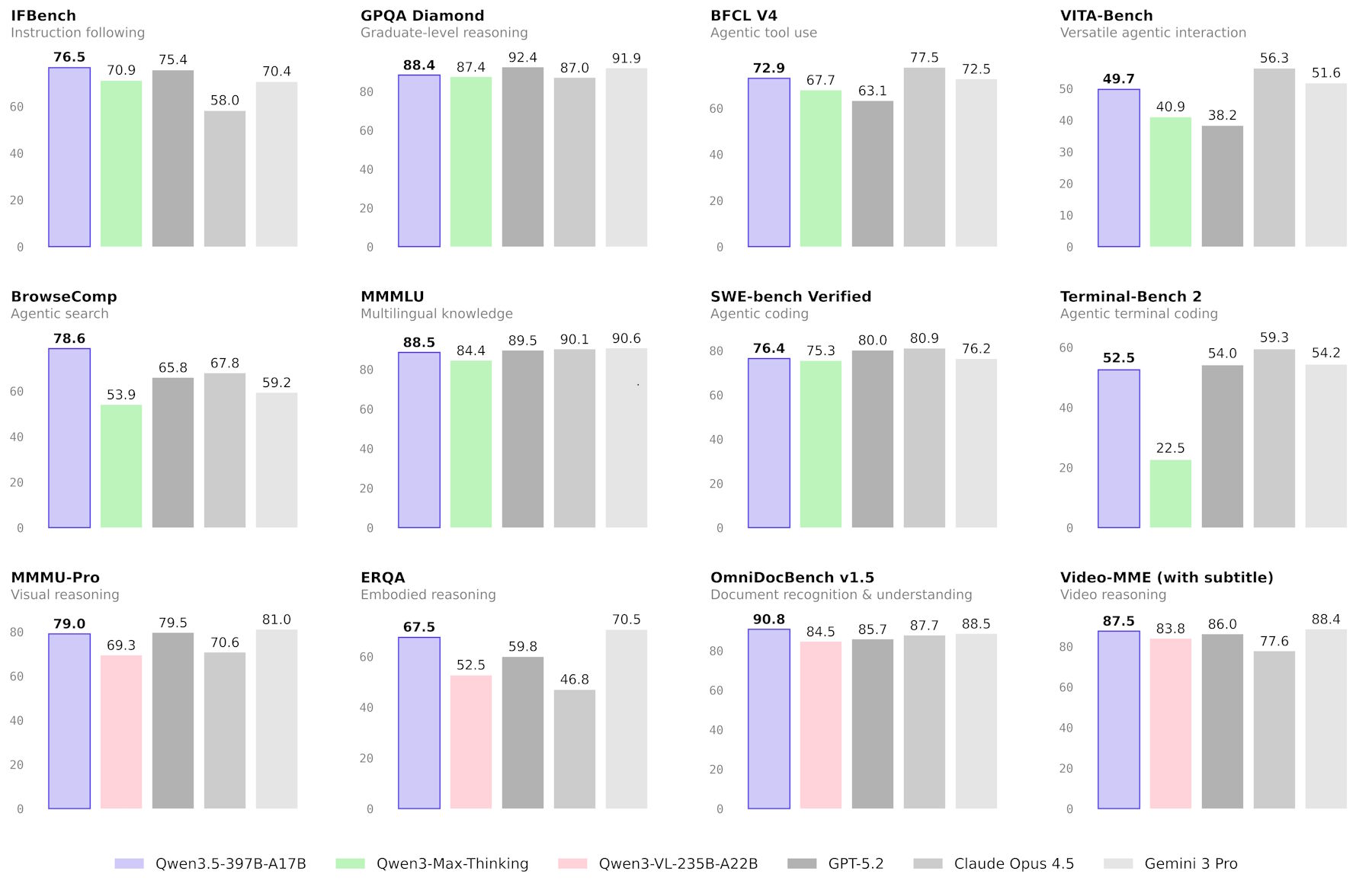
- While Qwen3.5 achieves top benchmark scores in instruction following, multilingualism, and certain visual tasks, it still falls short of GPT-5.2 and Claude 4.5 Opus in reasoning and coding performance.
Alibaba has released Qwen3.5-397B-A17B, the first model in its new model series. It handles text, images, and video in a single architecture and is freely available as an open-weight model.
The model packs 397 billion total parameters, but only 17 billion fire for any given query. Like other large AI models, it uses a mixture-of-experts architecture that activates only the relevant parts of the network depending on the task.
The ratio of total to active parameters is unusually high in Qwen3.5, just as it was with Qwen3-Next, suggesting a particularly fine-grained split across many specialized experts. Alibaba also built in a new attention architecture called Gated Delta Networks, designed to cut compute costs even further.
The Qwen team says Qwen3.5 processes requests 19 times faster than its much larger predecessor Qwen3-Max and 3.5 to 7 times faster than its direct predecessor Qwen3-235B with a 256,000-token context window. Performance stays at a comparable level.

Qwen3.5 improves in agent tasks and image understanding
Qwen3.5 sets new records on some benchmarks but falls short of GPT-5.2, Claude 4.5 Opus, and Gemini-3 Pro on others. The biggest gains show up in agentic tasks: on TAU2, which measures how well a model performs as an autonomous agent, Qwen3.5 scores 86.7 - just behind GPT-5.2 (87.1) and Claude 4.5 Opus (91.6). For complex instruction following, it posts the best scores in the field on IFBench (76.5) and MultiChallenge (67.6). In practice, the model can build a slide deck from a combination of an image and prompts.
Alibaba says Qwen3.5 hits top marks in several math-visual benchmarks, including MathVision (88.6) and ZEROBench (12). It also leads in most document comprehension and text recognition tests. On the broader image understanding benchmark MMMU, however, it trails Gemini 3 Pro (87.2) and GPT-5.2 (86.7) with a score of 85.
Other models still lead in classic reasoning and coding: GPT-5.2 scores 87.7 on LiveCodeBench compared to 83.6 for Qwen3.5. On math competition tasks like AIME26, the model lands at 91.3, behind GPT-5.2 (96.7) and Claude 4.5 Opus (93.3).
More training data and heavier reinforcement learning drive the gains
The team credits the jump over the previous Qwen3 series to a massively expanded reinforcement learning phase during training. Instead of optimizing the model for individual benchmarks, they systematically ramped up the variety and difficulty of training environments. The biggest payoff showed up in agent skills.
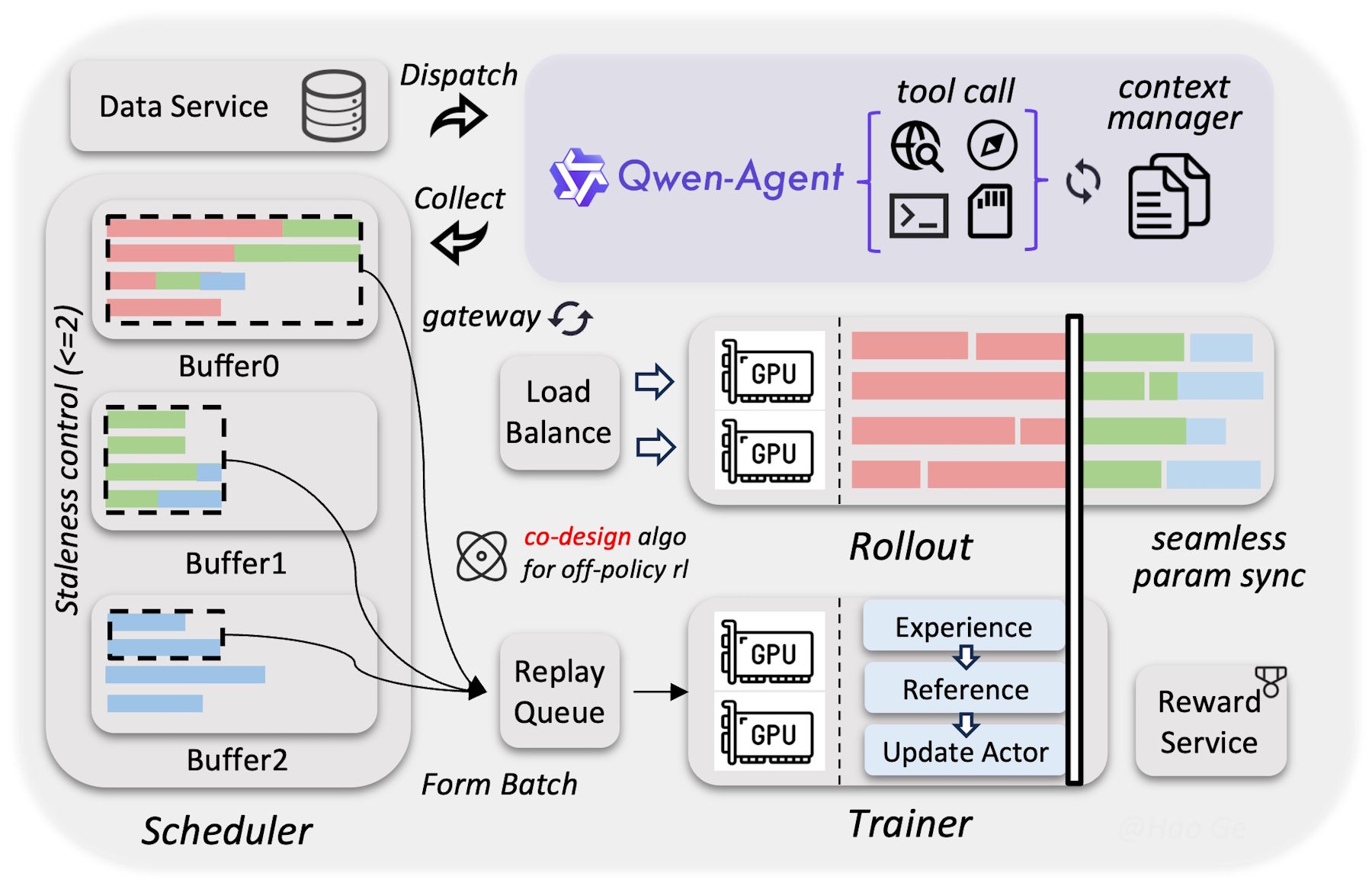
Alibaba also says that the model was trained on considerably more data than its predecessor, with stricter filtering at the same time. Despite its more efficient architecture, Qwen3.5 matches the performance of Qwen3-Max-Base, which has over one trillion parameters.
Language support grew from 119 to 201 languages and dialects. A bigger vocabulary of 250,000 tokens (up from 150,000) should speed up processing for most languages by 10 to 60 percent.
Qwen3.5 goes from solving mazes to running desktop workflows
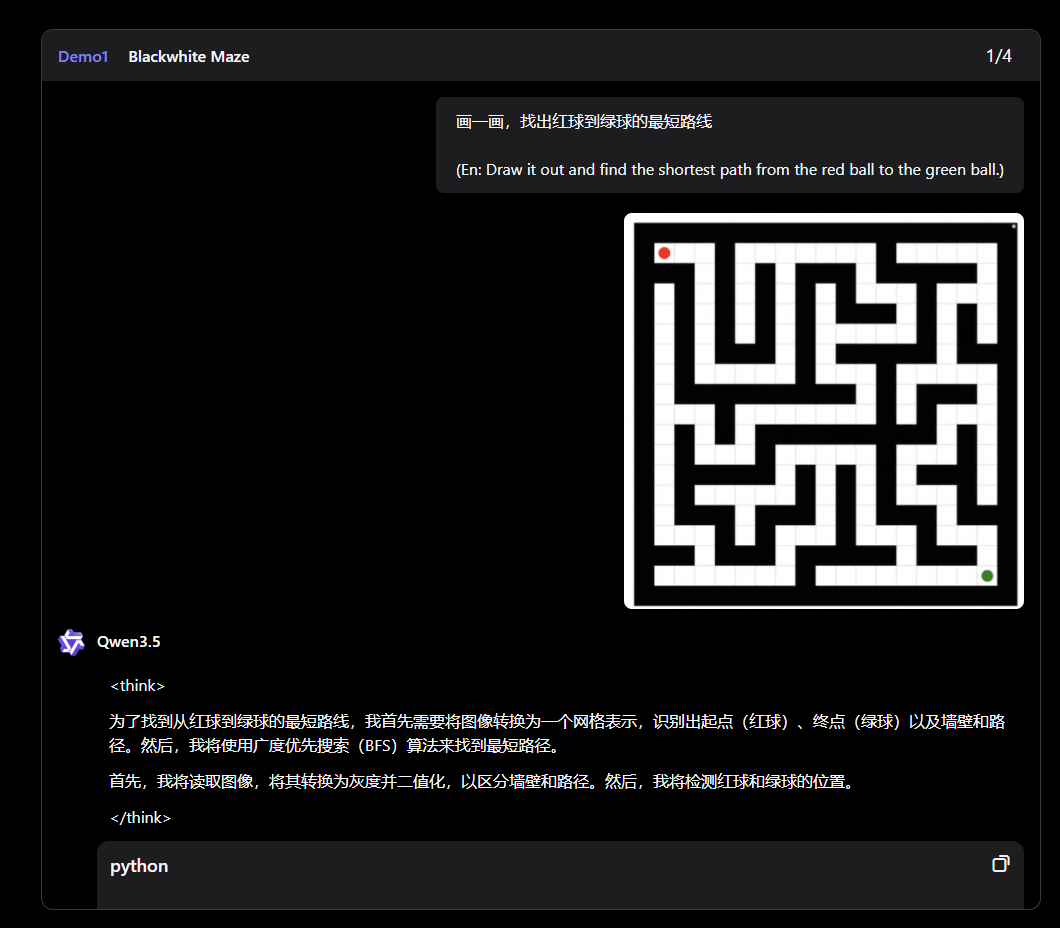
As a natively multimodal model, Qwen3.5 can handle up to two hours of video, according to Alibaba. In the published demos, the company shows the model writing Python code on its own to solve a maze and visually map out the shortest path. In another example, it watches traffic videos and explains driving decisions based on traffic light phases.
As a GUI agent, Qwen3.5 can operate smartphone and computer interfaces on its own - filling out Excel spreadsheets or running multi-step desktop workflows, for example. For developers, Alibaba offers integrations with tools like Qwen Code, which turns natural language instructions into working code.
Looking ahead, the Qwen team says the next step is moving from model scaling to system integration. Future agents should have persistent memory, improve themselves over time, and factor in cost constraints. Instead of task-based assistants, Alibaba wants to build autonomous systems that tackle complex jobs independently over the course of several days.
Availability
The open-weight model Qwen3.5-397B-A17B is up for download on Hugging Face and ships under the Apache 2.0 license, which allows commercial use and modification. Developers can try it right in the browser through the Qwen Chat interface in Auto, Thinking, or Fast mode.
The hosted version, Qwen3.5-Plus, with a one-million-token context window is available via API through Alibaba Cloud Model Studio and supports web search, code interpreter, and adaptive reasoning. Qwen3.5 can also be plugged into tools like Qwen Code for use as a coding agent.
The model runs $0.40 per million input tokens and $2.40 per million output tokens through the API. That's a fraction of what OpenAI or Anthropic charge for benchmark-comparable models, pretty standard at this point for Chinese AI labs. Still, Chinese AI companies haven't cracked the US enterprise market yet, but they're reportedly picking up traction among cost-conscious AI startups.
Chinese AI labs keep up the pace
Qwen3.5 drops in the middle of a heating race among Chinese AI labs. Zhipu AI recently shipped GLM-5, an open-source model with 744 billion parameters gunning for Claude Opus 4.5 and GPT-5.2 in coding and agent tasks. Moonshot AI unveiled Kimi K2.5, a model that coordinates up to 100 sub-agents running in parallel. MiniMax launched M2.5, promising "intelligence too cheap to meter." And Baidu grabbed the top spot among all Chinese models on the LMArena ranking with Ernie 5.0 and its 2.4 trillion parameters.
What all these models have in common: benchmark performance on par with Western models, open availability, and—for anyone who wants API access—rock-bottom pricing compared to their Western counterparts. Deepseek's next large model with a trillion parameters is still delayed, but word is it could ship this week.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now