When language models hallucinate, they leave "spilled energy" in their own math
Key Points
- Technically, large language models always hallucinate, but factually wrong hallucinations leave detectable traces within the models' own internal computations.
- Researchers at Sapienza University of Rome have developed a training-free method called "Spilled Energy" that analyzes energy differences in the final computation layer of an LLM to identify incorrect outputs.
- While the approach cannot prevent hallucinations from occurring, it outperforms previous detection methods by flagging them more reliably during the text generation process itself.
When large language models hallucinate, they leave measurable traces in their own computations. Researchers at the Sapienza University of Rome have developed a training-free method that picks up on these traces and generalizes better than previous approaches.
Figuring out automatically whether an LLM is hallucinating in a given response has always been a hard problem. Strictly speaking, large language models always hallucinate: they generate text based on statistical probabilities, not knowledge or facts. Every output is essentially a controlled hallucination that usually goes unnoticed because the result happens to line up with reality.
Hallucination only becomes a problem when a model produces factually wrong, made-up, or contradictory content. In a paper published at ICLR 2026, a research team from the Sapienza University of Rome takes an unusual approach to catching exactly these bad hallucinations: they look at the final computational layer of an LLM—the softmax layer—from a new angle.
This layer converts the model's raw values into probabilities for the next word. The team treats it as an energy-based model, a physics-inspired probability framework where low-energy values mean high probabilities.
Autoregressive language models predict one word at a time. At each step, the model calculates how likely every possible next word is. Mathematically, certain energy values between successive prediction steps should be identical, since they describe the same quantity from two different perspectives.
In practice, though, they don't match, the researchers write. They call this gap "spilled energy." According to the paper, it correlates strongly with errors—when an LLM hallucinates, spilled energy runs significantly higher than for correct answers.
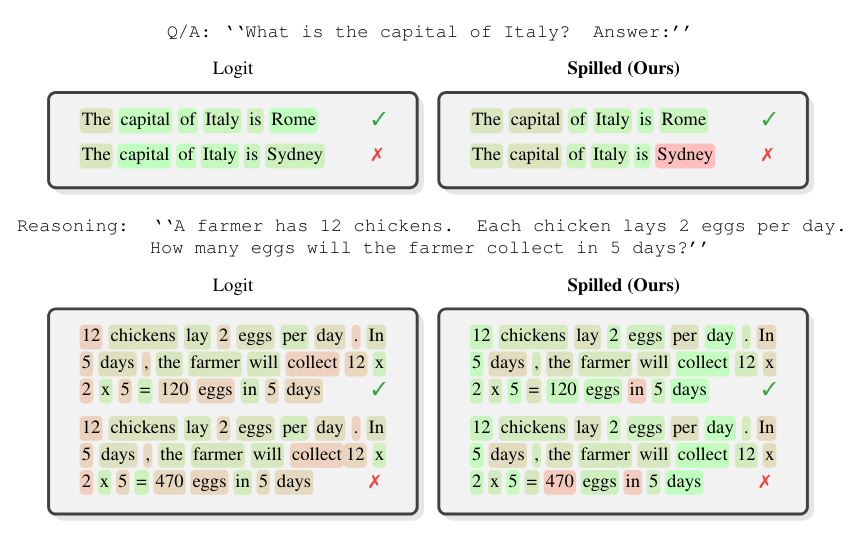
Previous approaches relied on training small classifier models on an LLM's internal states to spot whether an answer is correct. According to the researchers, it's critical to limit the measurement to the exact answer tokens. When asked about the capital of Italy, for instance, only the word "Rome" or "Sydney" matters, not the surrounding sentence. This localization boosts detection performance by up to 24 percent.
Spilled energy outperforms trained classifiers across nine benchmarks
The team tested their method on nine established benchmarks, including TriviaQA, HotpotQA, IMDB, and Math, along with synthetic computation tasks using 13-digit numbers. They evaluated LLaMA-3 8B, Mistral-7B, Gemma (1B and 4B), and Qwen3-8B, each in both pre-trained and instruction-tuned variants.
The researchers measure detection accuracy using the AuROC metric, which shows how well a method can separate correct from incorrect answers. A score of 50 percent is chance, and 100 percent would be perfect detection. Spilled Energy beat both simple output confidence scores and trained error detectors.
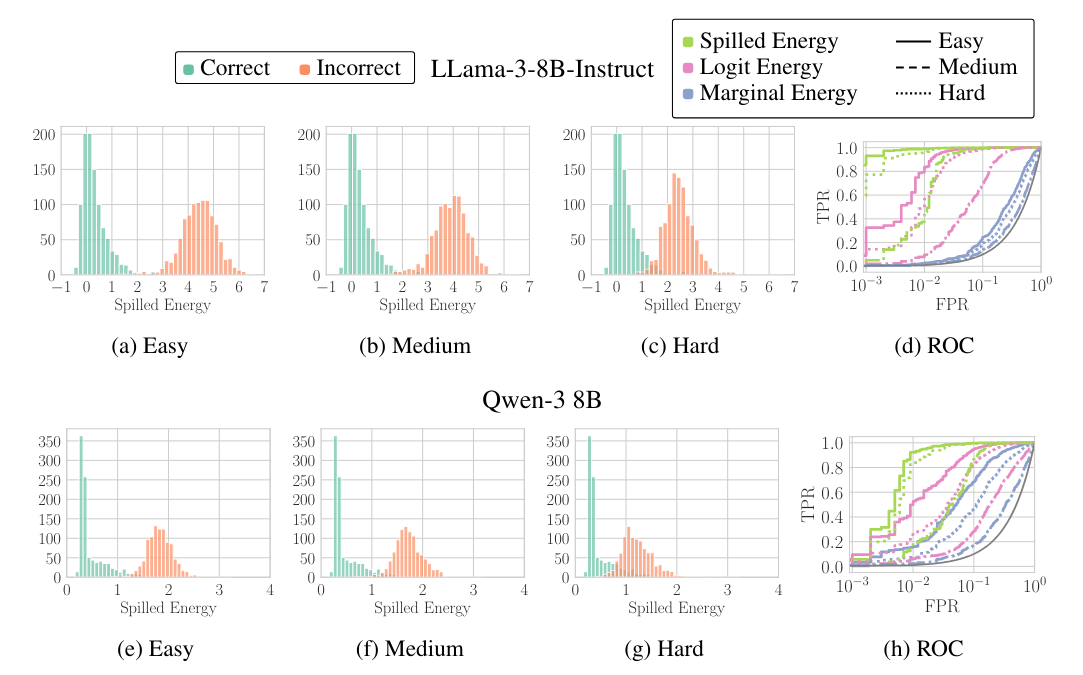
On Mistral-Instruct, Spilled Energy hit an average of 77.49 percent, compared to 65.56 percent for trained classifiers and 63.44 percent for plain logit confidence. Simply asking the model whether its own answer is correct scored around 55 percent, barely above chance.
The advantage was especially obvious when generalizing across task types: trained classifiers dropped close to random when applied to new datasets. Spilled Energy delivered stable results with zero training.
Instruction tuning, fine-tuning a model to follow human instructions, actually hurt confidence-based hallucination detection, likely because fine-tuned models tend to be overconfident. Spilled Energy, on the other hand, benefited from the same process. With LLaMA-3, the detection rate climbed from 68.69 to 73.16 percent, and with Mistral from 73.94 to 77.49 percent. Tests with Gemma confirmed that the approach works across different model sizes, for both 1B and 4B parameters.
Punctuation and sentence beginnings can still trigger false alarms
The researchers acknowledge some limitations. Spilled Energy occasionally fires false alarms on non-semantic tokens like punctuation marks or words at the start of sentences. At those points, probability mass naturally spreads across many plausible next words, which inflates the energy values. Correctly identifying the actual answer tokens is therefore critical.
Spilled Energy can't prevent hallucinations, but according to the researchers, it provides a mathematically grounded tool for catching them during text generation. The code is available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now