Chinese AI model MiniMax M2.7 reportedly helped develop itself

Chinese AI company MiniMax has released M2.7, a model that reportedly played an active role in its own development. Through autonomous optimization loops, it improved its own training process and posted competitive benchmark results.
During development, M2.7 reportedly updated its own knowledge stores, built dozens of complex capabilities within its agent infrastructure, and improved its reward-based training on its own. It then took those results and used them to refine its own learning process.
MiniMax describes M2.7 as "our first model deeply participating in its own evolution" and lays out a vision where future AI self-evolution will "gradually transition towards full autonomy, coordinating data construction, model training, inference architecture, evaluation, and other stages without human involvement."
MiniMax isn't the only company exploring this approach. OpenAI recently introduced its GPT-5.3 Codex coding model with similar claims about AI-assisted development. According to OpenAI, the Codex team used early versions of the model to find bugs during training, manage deployment, and evaluate test results. The team said they were surprised by how much Codex accelerated its own development process.
Over 100 autonomous optimization rounds show what self-improving AI can do
To push the limits of this self-optimization, MiniMax had an internal version of M2.7 set up a research agent system that works with various project groups inside the company. According to MiniMax, the agent handles tasks like literature research, experiment tracking, debugging, metric analysis, and code fixes as part of the in-house RL team's daily workflow. Human researchers only step in when critical decisions need to be made. The model covers 30 to 50 percent of the entire workflow.
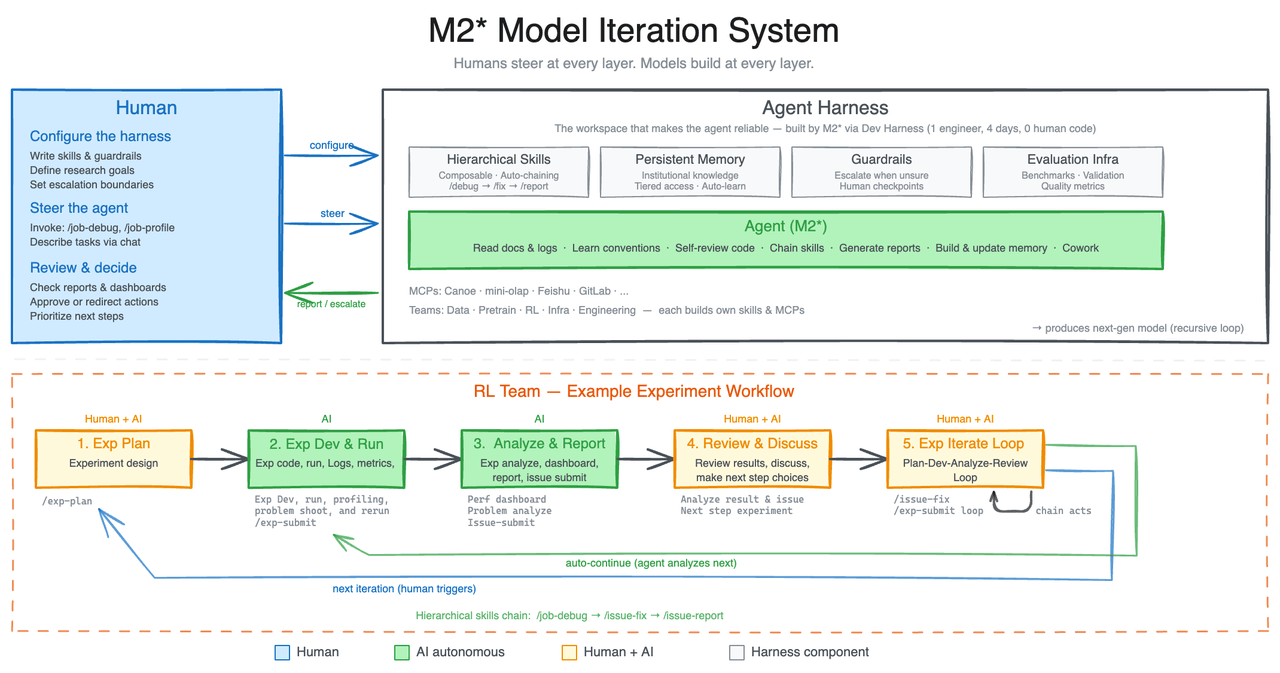
In one experiment, M2.7 optimized a model's coding performance in an internal development environment completely on its own over more than 100 rounds. Each round, it analyzed failures, planned changes, tweaked the code, tested the results, and decided whether to keep or toss the changes. According to MiniMax, this led to a 30 percent performance boost on internal evaluation sets.
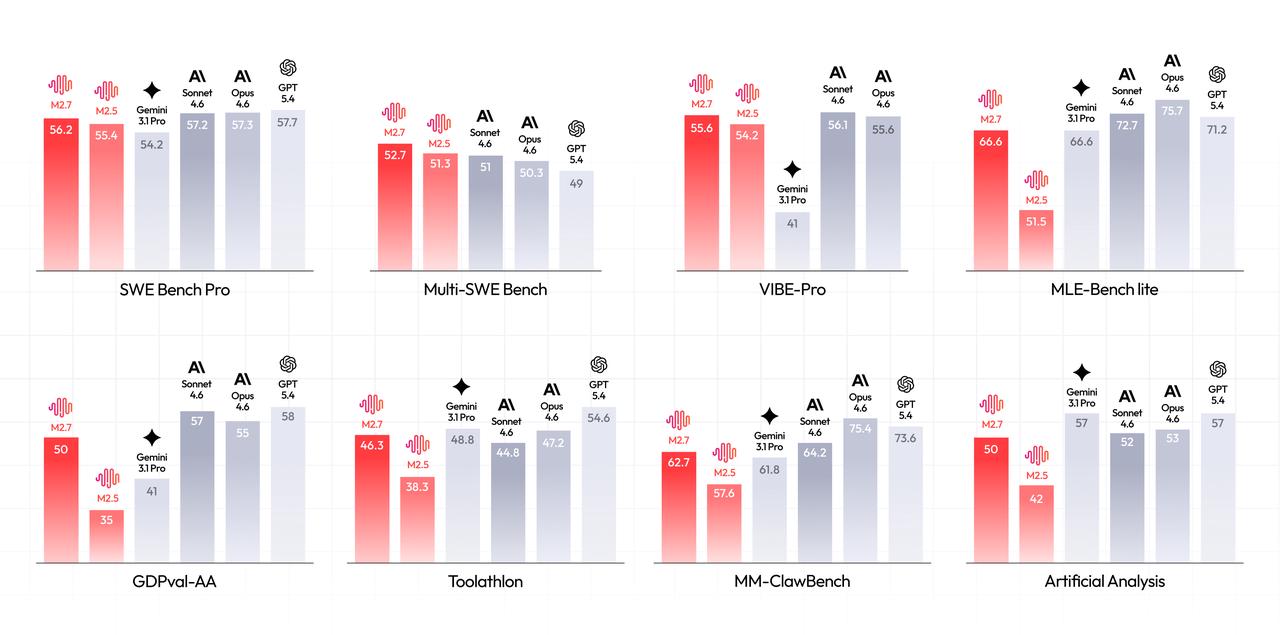
In 22 machine learning competitions from OpenAI's MLE Bench Lite, M2.7 hit an average medal rate of 66.6 percent across three 24-hour runs. That puts the model behind Opus 4.6 (75.7 percent) and GPT-5.4 (71.2 percent), but right on par with Gemini 3.1, according to the company.
That said, benchmark results serve as useful indicators but don't necessarily reflect real-world performance. How a model scores on standardized tests can differ significantly from how it handles everyday tasks, and results depend heavily on testing conditions, prompt formatting, and model optimization. These numbers are best treated as rough reference points rather than definitive measures of capability.
M2.7 keeps pace with top Western models in coding and office tasks
According to MiniMax, M2.7 delivers results on par with leading Western models in software engineering benchmarks. On SWE-Pro, it scored 56.22 percent, comparable to GPT-5.3-Codex. On VIBE-Pro, a benchmark for complete project delivery, it hit 55.6 percent. In real-world scenarios, M2.7 reportedly cut recovery time for production system failures to under three minutes on multiple occasions.
For professional office work, M2.7 achieved an ELO score of 1,495 on the GDPval-AA benchmark, the highest score among open-weight models, according to MiniMax. The model reportedly handles multi-level edits in Word, Excel, and PowerPoint with high accuracy and maintains 97 percent rule fidelity across more than 40 complex instruction sets.
As a practical example, MiniMax describes a financial analysis for TSMC where M2.7 independently read annual reports, built a sales forecast model, and turned the results into a presentation and research report. Financial experts said the output could already work as a first draft.
Open-source demo brings AI interaction into a graphical environment
Beyond productivity scenarios, MiniMax also improved the model's character consistency and emotional intelligence. To show this off, the company released OpenRoom, an open-source project that moves AI interaction into a graphical web environment where characters proactively engage with their surroundings. M2.7 is available through MiniMax Agent and the API platform; unlike previous model versions, weights aren't available yet.
Jürgen Schmidhuber laid the theoretical groundwork for self-improving AI back in 2003 with the concept of the "Godel Machine," which only modifies its own code when there's formal proof of benefit. Projects like Sakana AI's "Darwin-Gödel Machine" and the "Huxley-Gödel Machine" from Schmidhuber's KAUST lab take a more pragmatic approach, having AI agents iteratively modify their own code and pick the best-performing variants through an evolutionary process.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.