Meta's new AI model predicts how your brain reacts to images, sounds, and speech
Key Points
- Meta's TRIBE v2 AI model, trained on fMRI data, predicts how the human brain responds to images, sounds, and speech, often matching typical brain reactions more accurately than a single real measurement from an individual.
- In controlled tests, the model successfully replicates well-known neuroscientific findings on a computer, such as correctly identifying specialized brain regions for processing faces, places, or language, which could drastically cut costly laboratory time in brain research.
- Despite its promise, the model has limitations: it treats the brain as a passive receiver, covers only three sensory channels, and operates within the slow temporal resolution of fMRI. Meta has made the code, weights, and an interactive demo freely available.
A new AI model from Meta predicts how the human brain reacts to images, sounds, and speech. In tests, it often matched the typical brain response better than any single person's scan.
Brain research requires new recordings for every new experiment, making neuroscience studies slow and expensive. AI researchers at Meta's FAIR lab want to skip this bottleneck entirely with an AI model that predicts brain activity instead of measuring it.
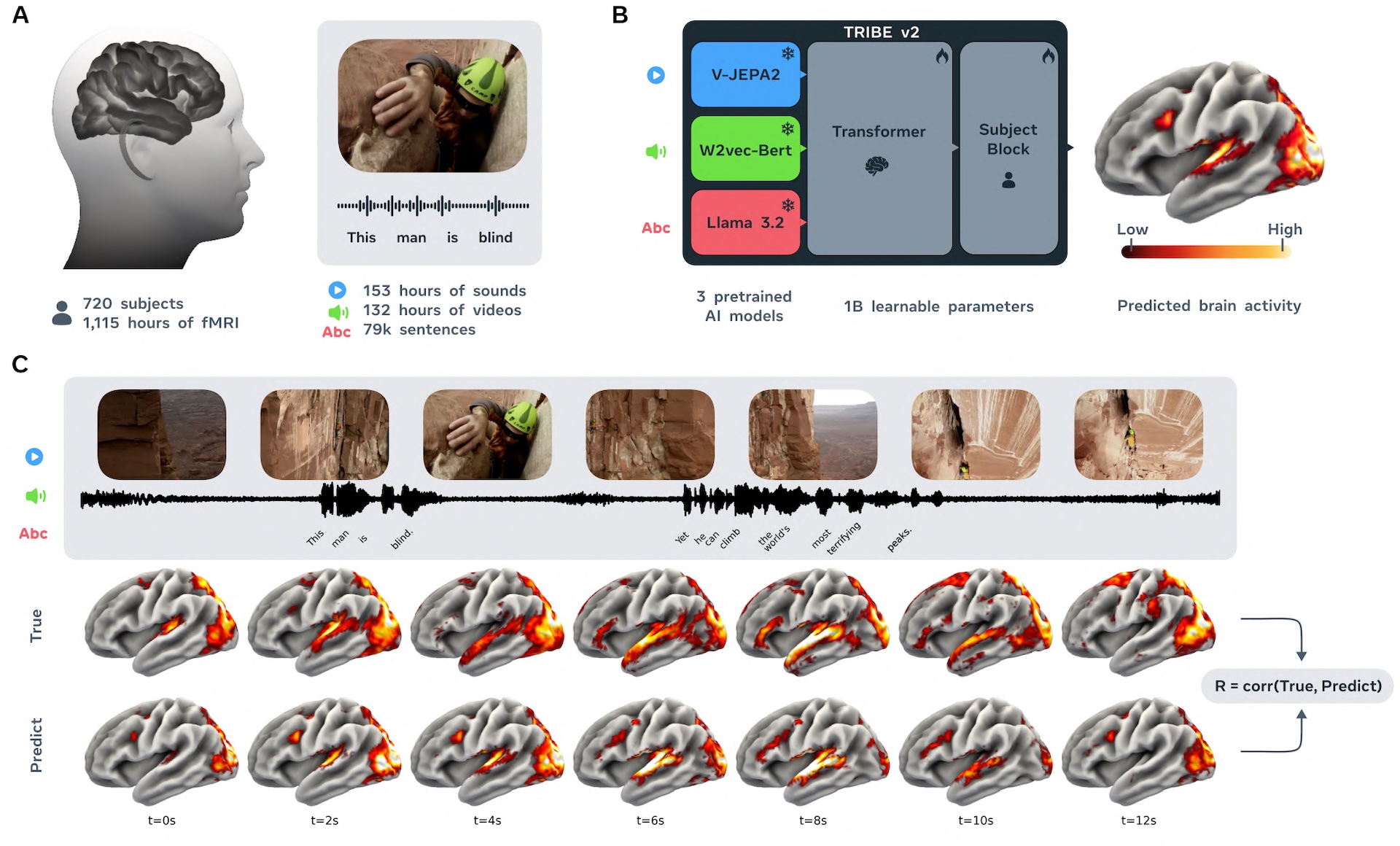
The model is called TRIBE v2, and it was trained on more than 1,000 hours of fMRI data from 720 subjects, according to the accompanying paper. Functional magnetic resonance imaging (fMRI) measures brain activity indirectly by tracking changes in blood flow and oxygen levels. Using this data, TRIBE v2 aims to predict how a brain responds to any visual, auditory, or language-based stimulus.
Three Meta models handle the preprocessing
TRIBE v2 takes three types of input: video, audio, and text. Each channel runs through a pre-trained Meta AI model first: Llama 3.2 for text, Wav2Vec-Bert-2.0 for audio, and Video-JEPA-2 for video. These models turn raw data into embeddings that capture what's visible in an image, audible in a sound, or readable in a sentence.
A transformer then processes all three representations together, picking up patterns that hold across different stimuli, tasks, and people. A final person-specific layer translates the output into a brain map with 70,000 voxels, the 3D pixels that make up an fMRI scan.
Predictions carry less noise than actual brain scans
Individual fMRI images are inherently noisy. Heartbeat, head movement, and device artifacts all distort the signal. To figure out how a brain typically responds to a given stimulus, researchers have to average many scans together.
TRIBE v2 gets around this by directly predicting an adjusted average response. In testing, this prediction correlated more strongly with the actual group average than most individual subjects' scans did. The effect was strongest in the Human Connectome Project dataset, which was captured with a 7 Tesla scanner, offering much higher signal quality than the standard 3 Tesla machines. On this dataset, TRIBE v2 hit a correlation with the group response twice as high as the median individual subject.
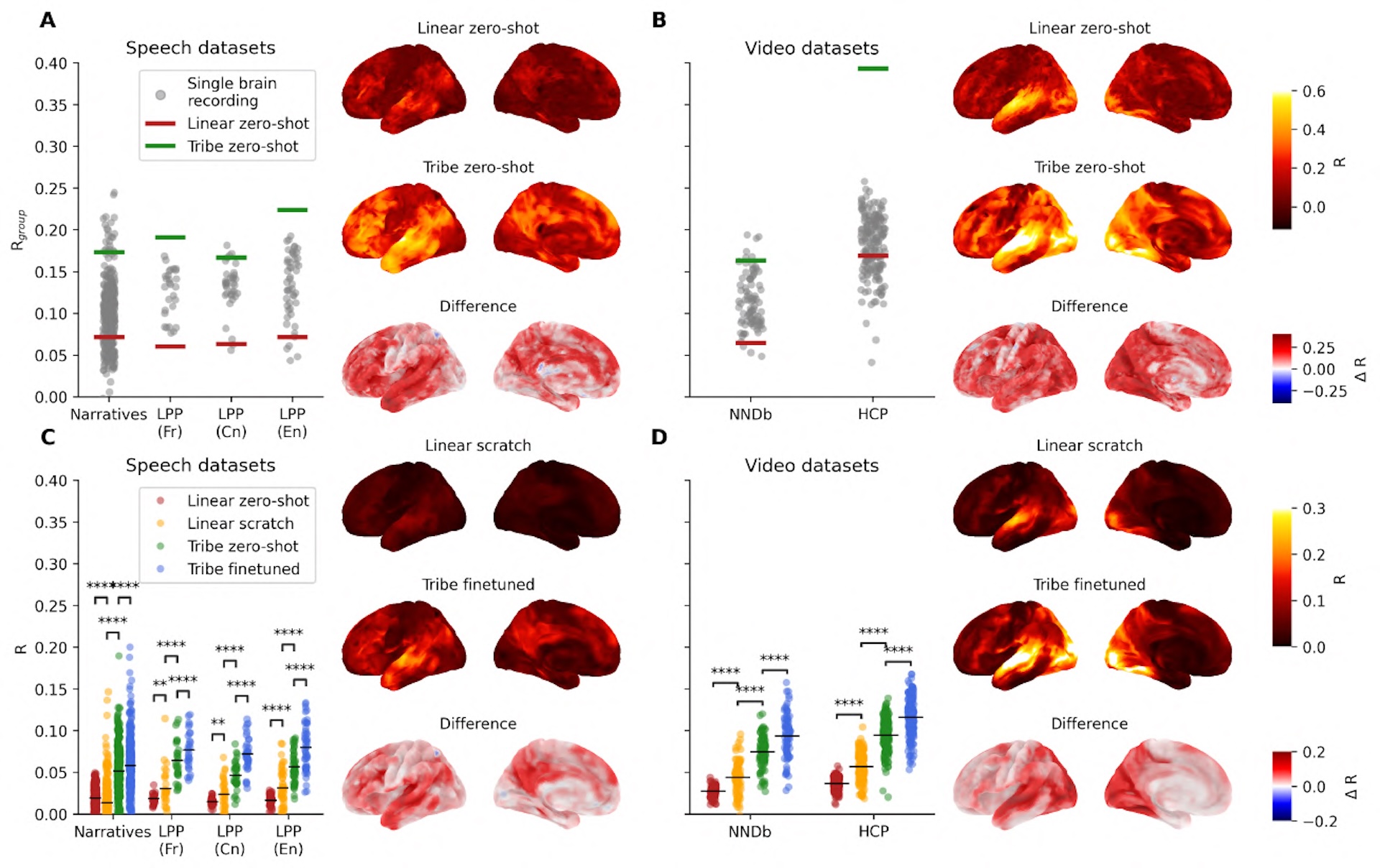
Compared to optimized linear models—the previous go-to method for this kind of prediction—TRIBE v2 showed significant improvements across every dataset, according to the paper. The earlier version, TRIBE v1, was trained on just four subjects and predicted only 1,000 voxels instead of 70,000, yet it still won the Algonauts 2025 competition, beating out 263 other teams.
TRIBE v2's prediction accuracy scales steadily with the amount of training data and hasn't plateaued yet. That suggests the model will keep improving as fMRI databases grow, a pattern that echoes the scaling laws of large language models, where more data reliably leads to better performance.
Decades of lab work replicated on a computer
The researchers tested TRIBE v2 with everyday stimuli like movies and podcasts, where multiple sensory inputs hit the brain at once, as well as with isolated stimuli typical of classical neuroscience. In those controlled setups, a single image might flash on screen for one second to measure a specific brain region's response. The team used test protocols from the Individual Brain Charting dataset, a collection of well-established neuroscience experiments, and had the model predict which brain areas should light up.
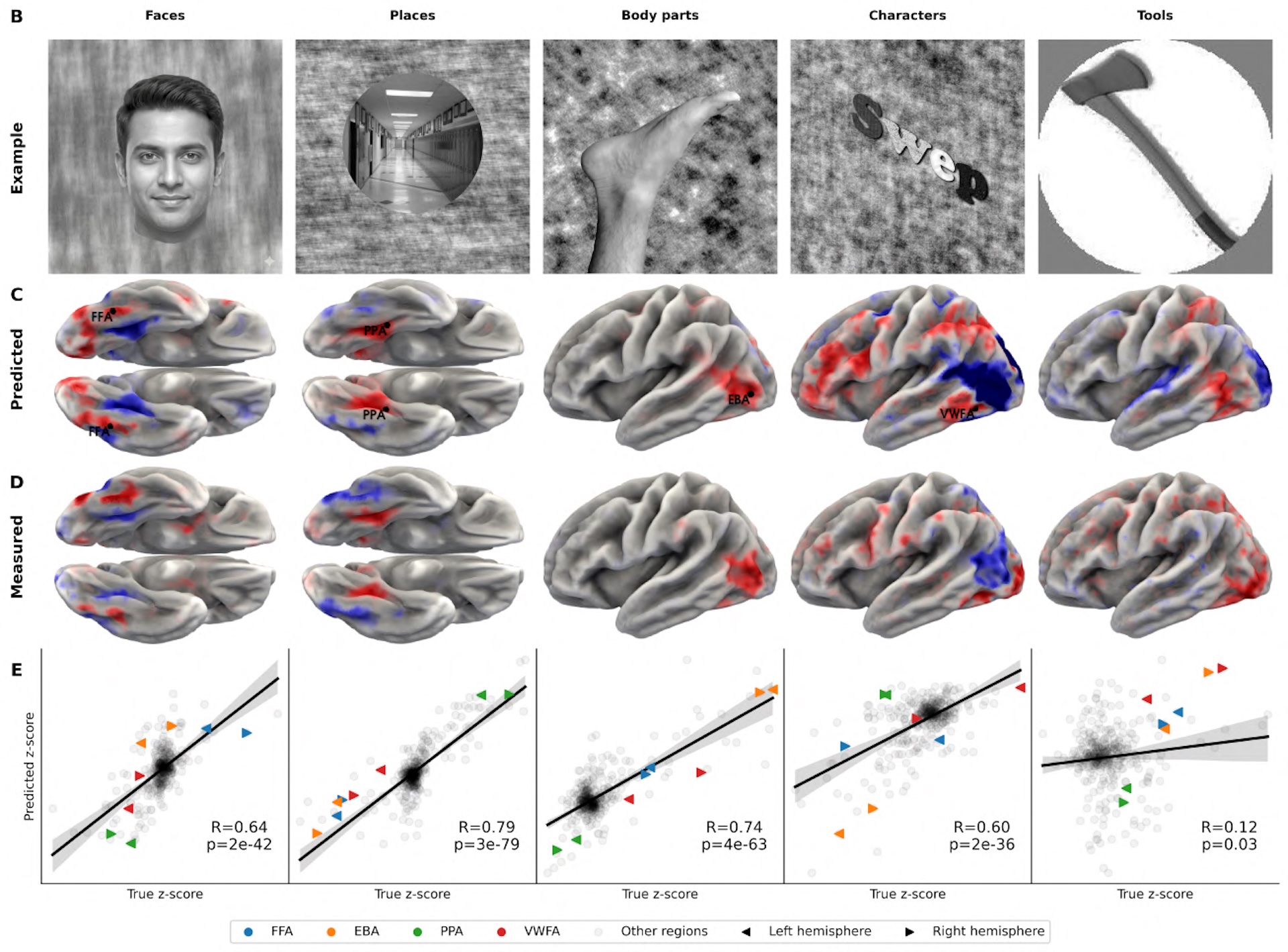
In visual experiments with images of faces, places, bodies, and characters, TRIBE v2 correctly pinpointed the known specialized brain regions every time. In language experiments, it localized the language network, distinguished between emotional and physical pain processing, and showed the expected stronger left-hemisphere activation for complete sentences versus word lists.
These results line up with findings from decades of empirical research on real subjects. For neuroscience, the implication seems clear: future experiments could be roughed out on a computer before anyone books expensive lab time.
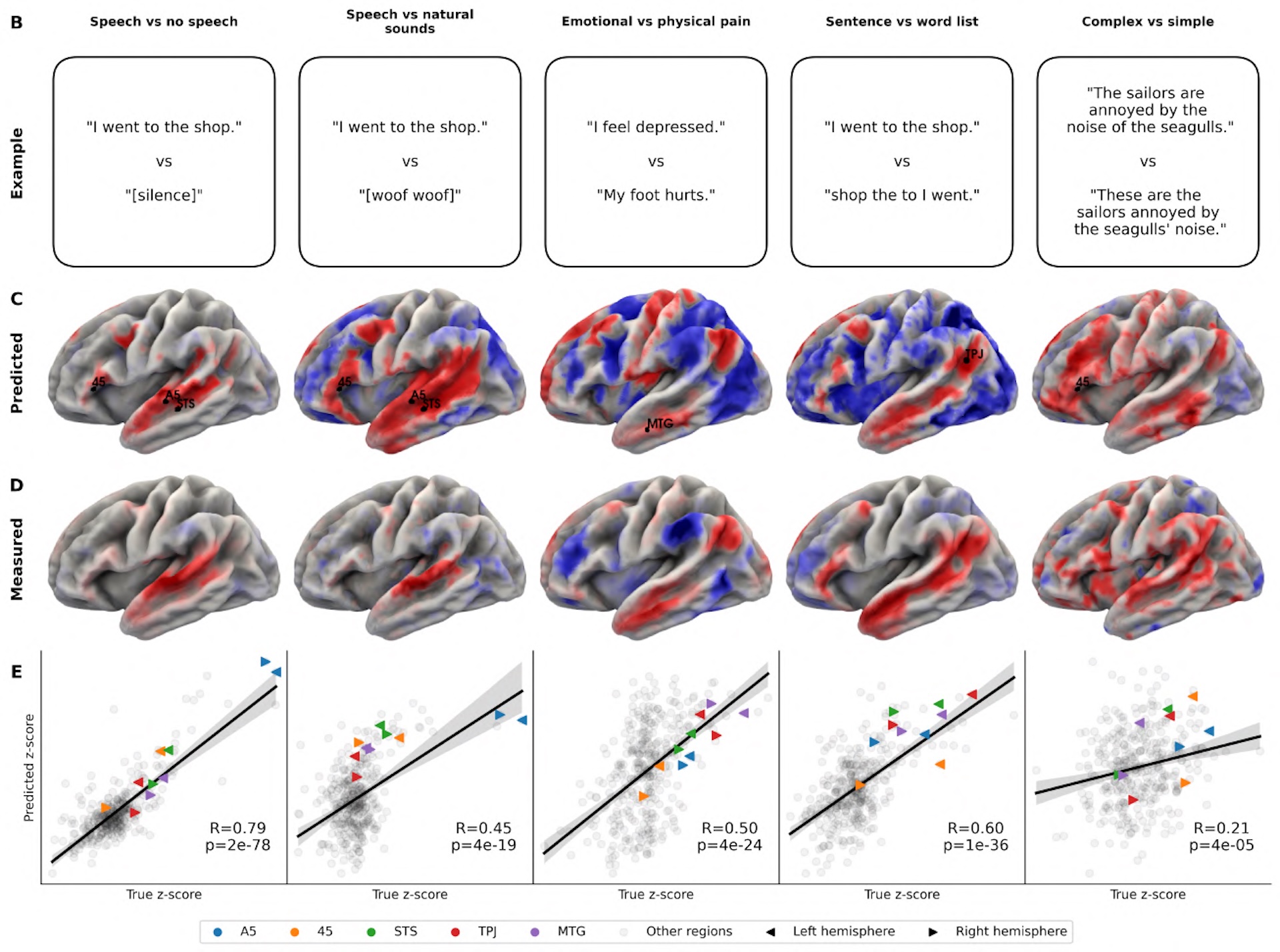
Mapping which sensory channel activates which brain region
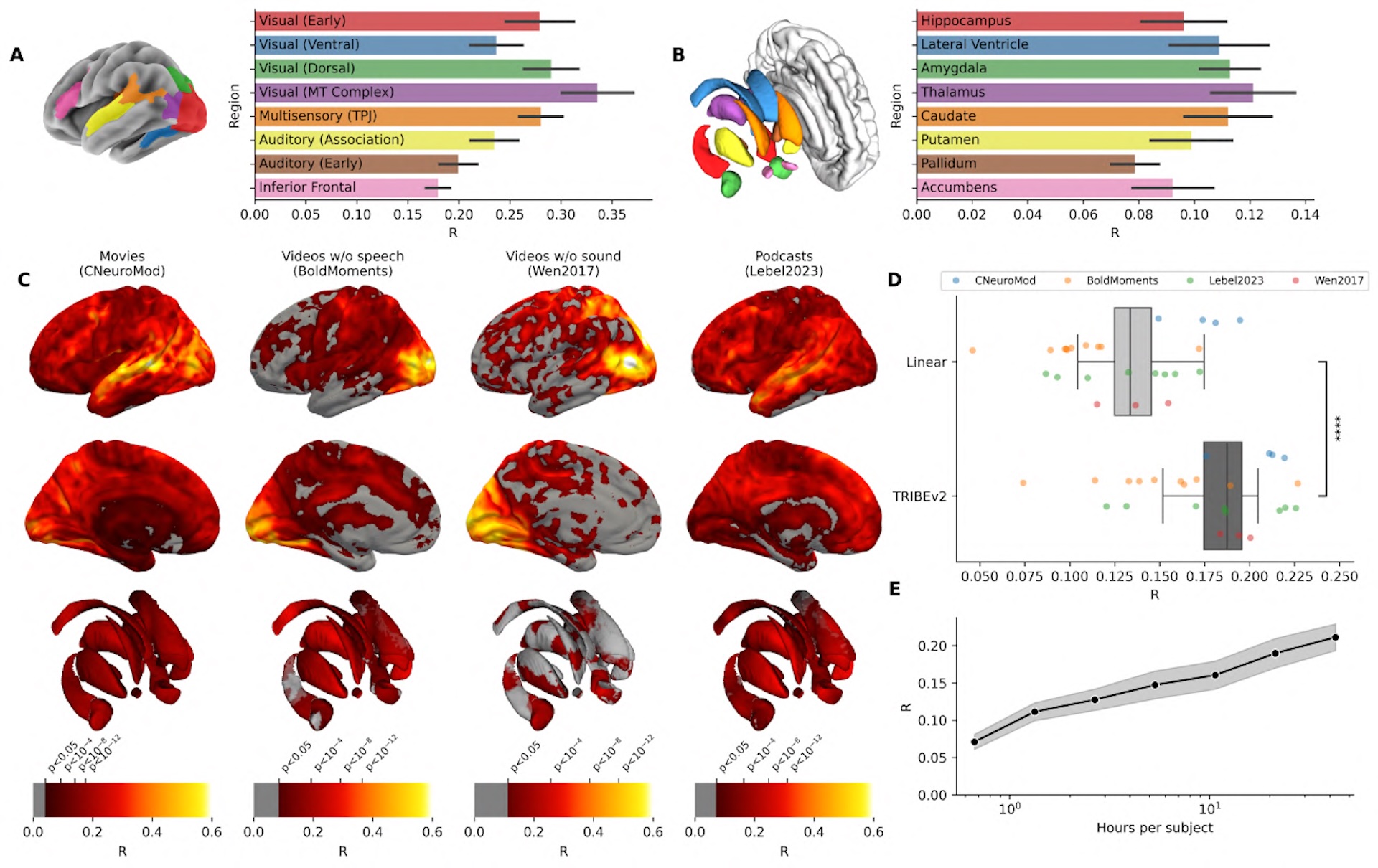
By selectively turning off individual input channels, TRIBE v2 reveals how much each sense drives activity in specific brain regions. The results match existing neuroscience: audio best predicts activity near the auditory cortex, video maps to the visual cortex, and text lights up language areas and parts of the frontal lobe.
In regions where the brain combines input from multiple senses, feeding all three channels delivers the biggest gains. At the junction of the temporal, parietal, and occipital lobes, prediction accuracy jumps by up to 50 percent compared to any single channel alone.
A statistical breakdown of the model's final layer also turned up five patterns that map onto known functional brain networks: the primary auditory cortex, the language network, motion recognition, the default mode network, and the visual system. The default mode network kicks in during daydreaming and self-reflection, among other things.
A passive observer with a limited toolkit
TRIBE v2's limitations are still significant. fMRI only measures brain activity indirectly through blood flow, with a delay of several seconds. The fast-moving dynamics of neural signals in the millisecond range stay hidden. The model also only covers three sensory channels—smell, touch, and balance are all missing.
More fundamentally, TRIBE v2 treats the brain as a passive receiver of sensory input. It doesn't model how the brain actively makes decisions or drives actions. It also can't capture developmental changes or clinical conditions, which the researchers say remains a priority for future versions.
Meta sees three use cases for the model: planning neuroscience experiments, building more brain-like AI architectures, and eventually diagnosing brain diseases. Code, model weights, and an interactive demo are all publicly available.
FAIR, Meta's AI research lab, has been working at the intersection of brains and AI for years. Last year, the team showed that an AI model could reconstruct typed sentences from non-invasive brain scans alone with up to 80 percent accuracy.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now