Cohere releases open source model that tops speech recognition benchmarks
Canadian AI company Cohere has released "Transcribe," a new open-source model for automatic speech recognition. The company says it claims the top spot on the Hugging Face Open ASR Leaderboard with an average word error rate of just 5.42 percent, beating out competitors like OpenAI's Whisper Large v3, ElevenLabs Scribe v2, and Qwen3-ASR-1.7B. Cohere says Transcribe also delivers the best throughput among similarly sized models.
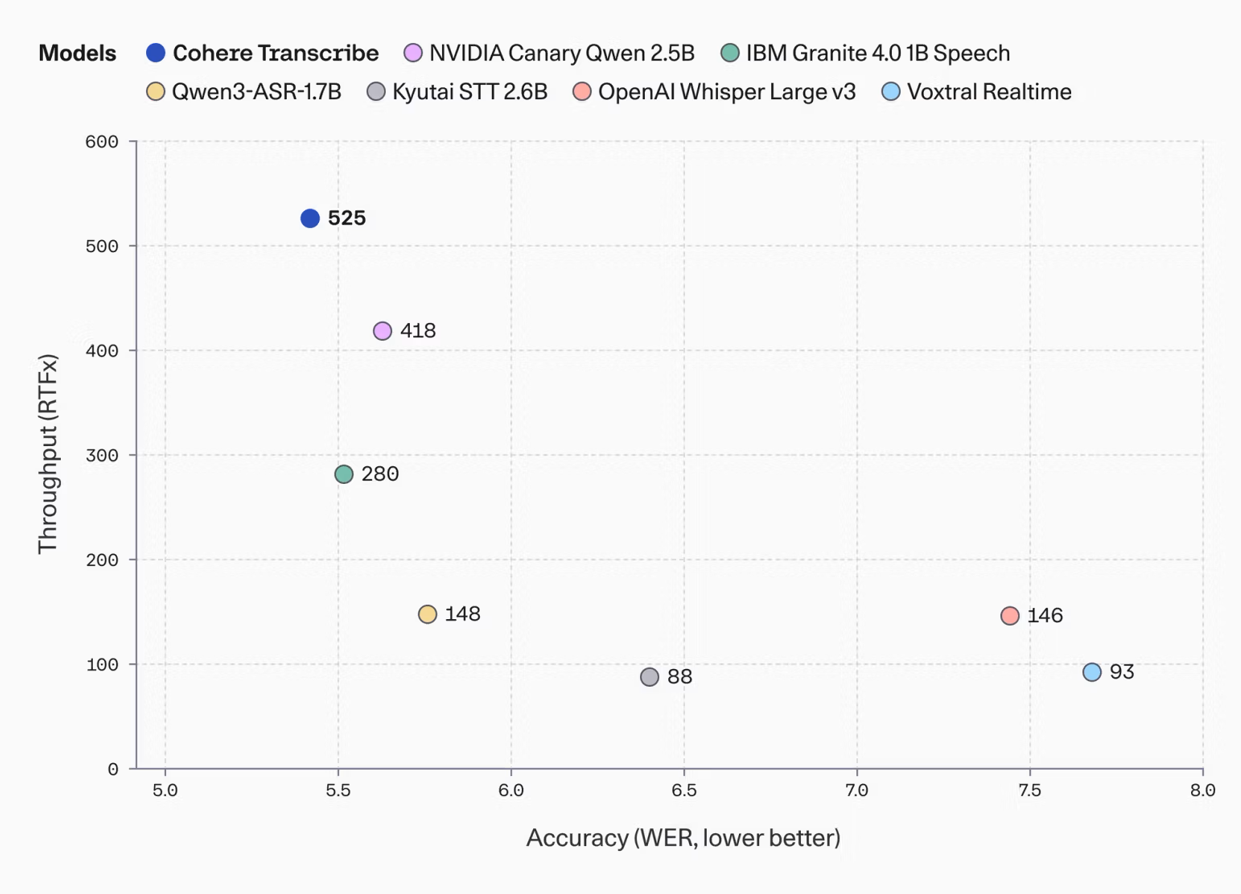
Cohere Transcribe compared with seven other speech recognition models. Models closer to the upper left corner perform best, meaning faster throughput and lower word error rates. | Image: CohereThe 2 billion parameter model supports 14 languages, including English, German, French, and Japanese. It's available for download under the Apache 2.0 license on Hugging Face and can also be accessed through Cohere's API and the Model Vault platform. Cohere plans to integrate Transcribe into its AI agent platform North in the future.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now