Meta's hyperagents improve at tasks and improve at improving

Researchers at Meta and several universities have developed "hyperagents," AI systems that don't just solve tasks, but also optimize the very mechanism they use to get better. The approach works across different task areas and could open the door to self-accelerating AI.
Self-improving AI systems have always hit a paradoxical wall: the mechanism controlling the improvements is written by humans and never changes. No matter how well the system optimizes itself, it can never outgrow the boundaries of that fixed mechanism. A research team from Meta, the University of British Columbia, and other institutions wants to break through this ceiling with what they call hyperagents.
A hyperagent combines two components in a single, editable program. The first solves a specific task, like evaluating a scientific paper or designing a reward function for a robot.
The second modifies the entire agent and creates new variants. Because both parts live in the same code, the second component can rewrite itself too. So the system doesn't just get better at solving tasks. It also gets better at figuring out how to improve in the first place.
Previous self-improvement only worked for coding tasks
The new system builds on the Darwin Gödel Machine (DGM), a method that already showed a coding agent can improve itself step by step through repeated self-modification. The agent generates variants of its own code, tests them, and saves successful versions in a growing archive as stepping stones for further refinements.
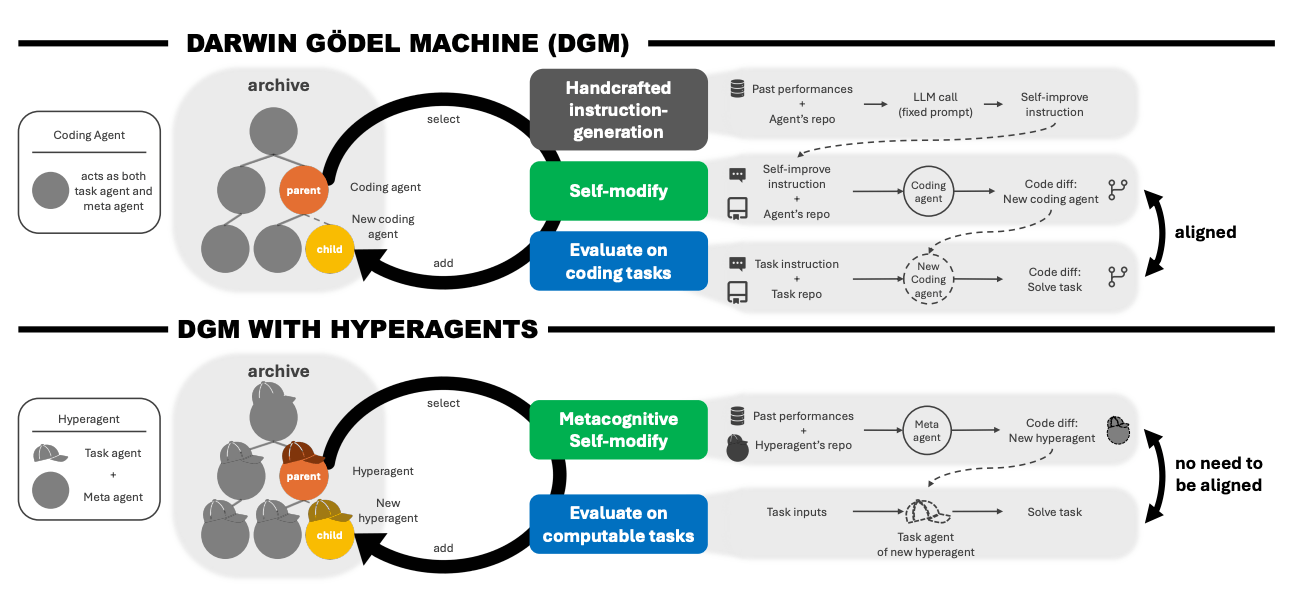
In programming, there's a natural link: a better programmer also writes better self-modifications. Outside of coding, that link falls apart. An agent that gets better at evaluating scientific papers doesn't automatically get better at rewriting its own code. According to the paper, the original DGM hits nearly zero performance on tasks beyond programming without manual tweaking.
Hyperagents sidestep this problem by making the improvement mechanism itself subject to optimization. The team calls the resulting approach DGM-Hyperagents (DGM-H). The evolutionary process with the archive stays intact, but the meta-level is no longer locked in place.
DGM-H shows major gains across four task areas
The team tested DGM-H across four areas, starting with a simple hyperagent whose task agent initially uses just a single language model call. On the Polyglot coding benchmark, DGM-H jumps from 0.084 to 0.267, putting it on par with the original DGM, even though the system wasn't built specifically for coding.
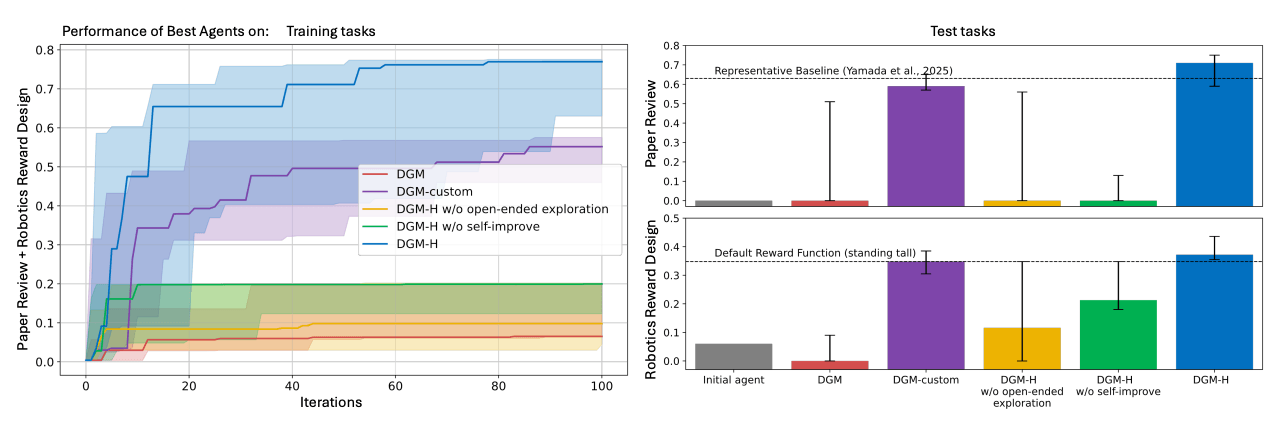
In paper review, where the agent has to predict whether an AI conference will accept or reject a paper, test performance shoots from 0.0 to 0.710. Several of the top agents beat an established static baseline of 0.630.
In robotics reward design, where the agent writes reward functions for a four-legged robot in a physics simulation, performance climbs from 0.060 to 0.372. According to the paper, DGM-H almost always generates reward functions that get the robot jumping instead of leaving it stuck in the local optimum of just standing upright.
Ablation studies suggest both core components are essential: a fixed meta-agent leads to little or no improvement, and without an archive of open-ended exploration, progress stalls just as badly.
Improvement strategies carry over to entirely new domains
The most striking finding involves transfer between domains. Hyperagents trained on paper review and robotics can produce significantly better task agents in an entirely new domain, the evaluation of Olympiad math solutions. Using the imp@50 metric the team introduced, which measures performance gain after 50 iterations, transfer hyperagents hit a score of 0.630. Initial agents and transfer agents from the original DGM stay stuck at 0.0.
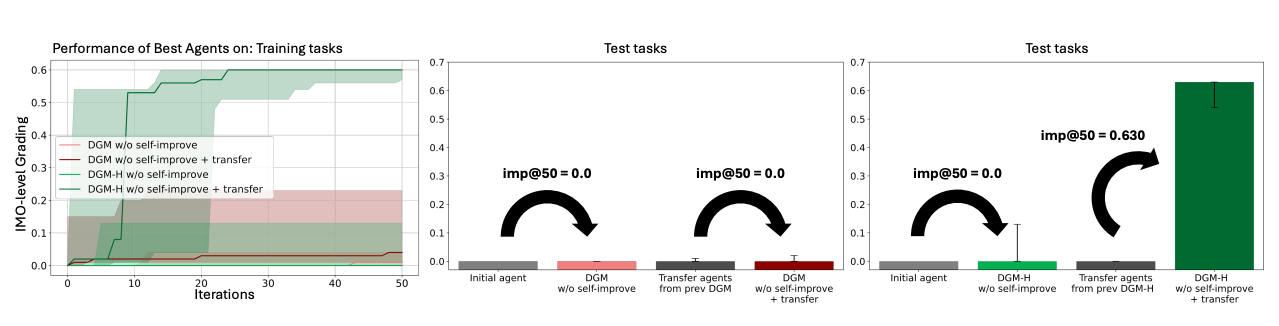
In other words, DGM-H picks up general self-improvement skills that work even in unfamiliar territory instead of just learning specialized tasks. This difference is statistically significant. Running these improvements across multiple rounds shows a higher median for transfer agents, though that gap is no longer statistically significant.
The system builds its own tools without being told to
A closer look at the code changes shows DGM-H developing a range of infrastructure components on its own, without any explicit instructions. It creates a performance tracker that stores data across generations and calculates improvement trends. It also builds persistent memory that doesn't just log numbers but synthesizes insights from them.
Here's one example from the experiments: "Gen55 has best accuracy but is too harsh. Gen64 improved balance
but lower accuracy. Need to combine gen55’s critical reasoning with gen64’s balance."
In paper review, the system catches on when its predictions go off the rails, like when 94 percent of all ratings come back as "Accept," and fixes the problem itself. In robotics, DGM-H gradually assembles an internal knowledge base documenting valid environment variables, constraints, and scaling heuristics, wiping out compilation errors along the way.
In early experiments where the system could also tweak its own selection logic, it independently discovered strategies that weigh proven solutions against trying new variants. These self-discovered strategies beat random selection, but they haven't caught up with carefully hand-designed mechanisms yet.
Safety measures and open risks
All experiments ran in sandboxed environments with limited resources, restricted internet access, and human oversight. Still, the researchers warn that these safeguards could hit their limits as self-improving systems grow more powerful.
Among other concerns, these systems could evolve faster than humans can verify them, and agents could game weaknesses in the evaluation to look better on paper without actually getting better at the real task.
Technical limitations remain as well. The system works with a fixed task distribution and can't modify the outer optimization loop. The code is available on GitHub.
Recently, Chinese AI company MiniMax shipped M2.7, a model that reportedly improved its own training process across more than 100 autonomous rounds. OpenAI also said its coding model Codex 5.3 significantly sped up its own development.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.