Naver's "Seoul World Model" uses actual Street View data to stop AI from hallucinating entire cities

Key Points
- Naver, the South Korean internet company, has introduced the Seoul World Model (SWM), a video world model that generates location-based videos using real city geometry derived from 1.2 million of its own Street View images.
- The model learns to separate permanent structures like buildings from transient objects by analyzing recordings taken at different times, while using simulated videos to fill in missing camera angles and Street View images further along a route as visual anchors to maintain consistency over longer distances.
- In benchmarks, SWM outperformed six current video world models in both visual quality and temporal consistency, and generalized successfully to unfamiliar cities such as Busan and Ann Arbor without any additional training.
South Korean internet giant Naver built a video world model grounded in actual city geometry from over a million of its own Street View images. The model generalizes to other cities without any fine-tuning.
Previous video world models produce visually convincing but entirely fictional environments. Everything beyond the starting image—invisible streets, distant buildings—is hallucinated. Researchers from Naver and Naver Cloud are taking a fundamentally different approach: their Seoul World Model (SWM) anchors video generation in the real geometry and appearance of an actual city.
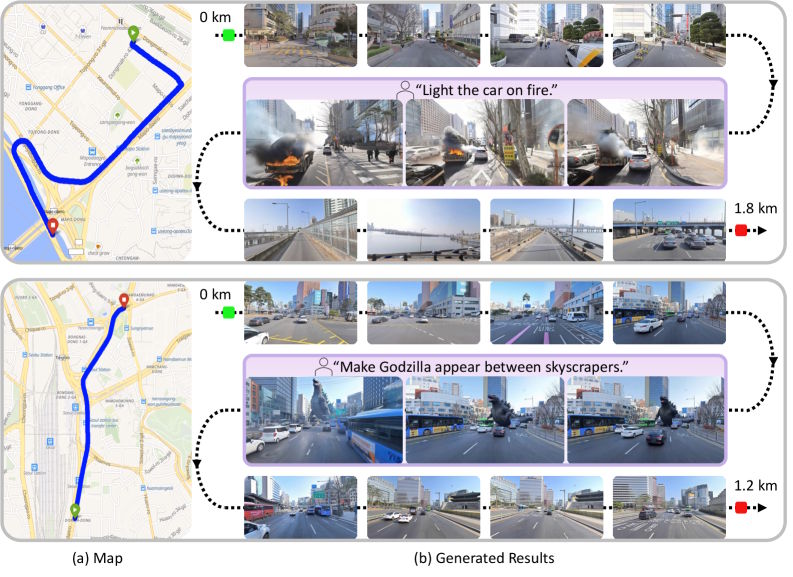
According to the research paper, this is the first world model tied to a real physical location. Naver is often called the "Google of South Korea" and operates the country's dominant search engine along with Naver Map, its own mapping service with street panoramas similar to Google Maps. The model draws directly from this pool.
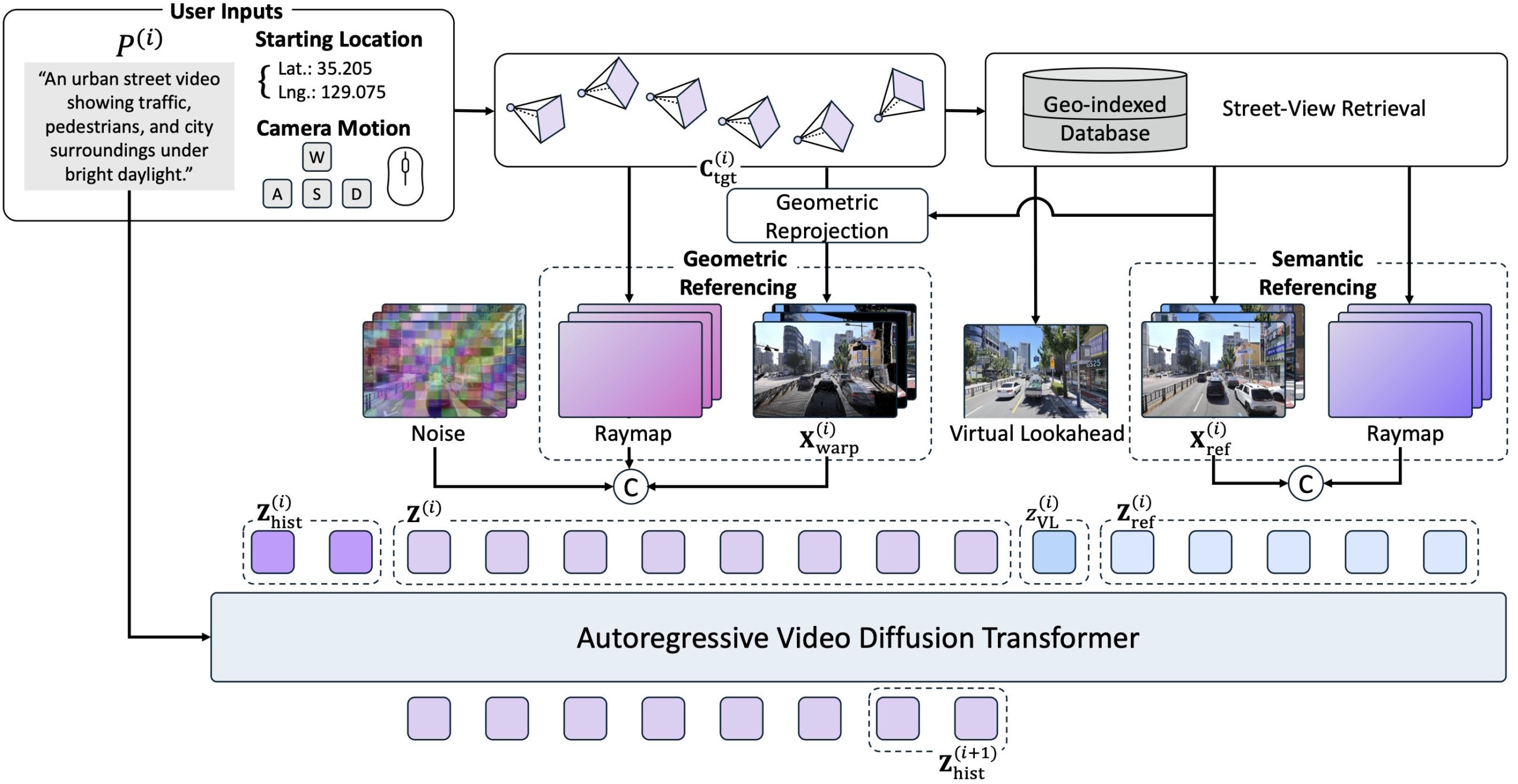
Users enter geographic coordinates, a desired camera movement, and a text prompt. The model then searches a database of 1.2 million panoramic images from Naver Map, retrieves the nearest Street View images, and uses them as guides for step-by-step video generation.
Real street data creates three distinct challenges
Working with real images introduces problems that don't exist with purely synthetic world models. The biggest one: Street View images are snapshots. Cars and pedestrians captured at the time of shooting have nothing to do with the dynamic scene the model needs to generate. Without a fix, the model would simply copy these random objects from the reference images into the generated video.

The researchers solve this with "cross-temporal pairing:" during training, they deliberately combine reference images and target sequences from different recording times. This teaches the model to distinguish between permanent structures like building facades and transient objects like parked cars. In ablation studies, this mechanism turned out to be the single most effective component.
Moreover, Street View cameras are mounted on vehicles and only capture an image every 5 to 20 meters. That means there are no continuous videos and no images from a pedestrian perspective or from the air. To fill this gap, the researchers generated 12,700 synthetic videos in the Unreal Engine simulator CARLA, with camera paths covering pedestrian, vehicle, and free-flight perspectives. They also developed a pipeline that interpolates temporally coherent training videos from the spatially scattered individual images.

Finally, small errors accumulate over long distances because the model generates video section by section. Previous methods use the very first image as a fixed anchor, but that becomes useless once the camera has traveled hundreds of meters.
SWM replaces this static anchor with a "virtual lookahead sink:" for each new section, the model retrieves a Street View image slightly further ahead on the route and inserts it as a virtual destination. This gives the model an error-free landmark that moves along with the camera.
Depth maps and original images work together
The retrieved Street View images feed into the generation process through two complementary paths. First, the model projects a spatially close reference image into the target perspective using its depth information, providing the spatial layout of the scene.
Second, the reference images aren't fed directly into the Transformer as raw pixels. Instead, they're first encoded into latent representations and integrated as semantic references. This lets the model pick up additional appearance details from the environment. According to the researchers, quality drops significantly if either of these two paths is removed.
SWM is built on Nvidia's Cosmos-Predict2.5-2B, a diffusion transformer with two billion parameters. The researchers trained the model on 24 Nvidia H100 GPUs using 440,000 Seoul Street View images, the synthetic CARLA data, and publicly available Waymo driving data.
SWM generalizes to cities it was never trained on
The researchers tested SWM in Seoul and also in Busan and the U.S. city of Ann Arbor, both completely absent from training. According to the paper, SWM outperforms six current video world models, including Aether, DeepVerse, and HY-World1.5, across visual quality, camera fidelity, temporal consistency, and correspondence with real locations on custom benchmarks with 30 test sequences of roughly 100 meters each.
Existing models increasingly drift over longer distances, producing blurry videos or a complete generation collapse. SWM keeps its output stable over hundreds of meters. Despite the strict spatial anchoring, the model still responds to text prompts: users can change weather, time of day, or add hypothetical scenarios while the underlying city layout stays intact.
Missing video data still limits prediction quality
Because continuous video recordings of entire cities aren't freely available, training relies on interpolated sequences of individual images, which fall short of real video footage in quality. Incorrect timestamps in the metadata also occasionally cause vehicles to appear or vanish abruptly in generated videos.
All Street View data was processed in compliance with privacy regulations, the researchers say, with faces and license plates anonymized before training. They point to urban planning, autonomous driving, and location-based exploration as potential use cases.
World models are currently one of the most actively researched areas in AI. Runway recently unveiled its first "General World Model," GWM-1, which builds an internal representation of an environment and simulates future events in real time. Google Deepmind CEO Demis Hassabis sees such models as a critical step toward general artificial intelligence. And a recent study by Microsoft Research and several U.S. universities also showed that large language models can function as world models, predicting environmental conditions with more than 99 percent accuracy.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now