Zhipu AI's GLM-5.1 can rethink its own coding strategy across hundreds of iterations
Key Points
- Zhipu AI has released GLM-5.1, a freely available model built for complex, long-running programming tasks. On the demanding SWE-Bench Pro software engineering benchmark, it edges out GPT-5.4 and Claude Opus 4.6.
- According to Zhipu AI, the model's key advantage is that it doesn't get stuck in dead ends on difficult tasks. Instead, it repeatedly reviews its own strategy and fundamentally changes course when progress stalls.
- On reasoning and knowledge tasks, GLM-5.1 falls behind models from Google and OpenAI. Zhipu AI calls the model a "first step" and openly acknowledges what still needs work.
Zhipu AI has released its new GLM-5.1 model under an MIT license. The model can reportedly refine its own approach over hundreds of iterations when tackling coding tasks.
Zhipu AI has introduced GLM-5.1, a new open-weight model designed for long-running, agent-based programming tasks. The core argument: existing models, including Zhipu's own predecessor GLM-5, run out of ideas too quickly on complex problems. They apply familiar strategies, make early progress, and then hit a wall. Throwing more compute at the problem doesn't help.
GLM-5.1 is supposed to fix this by repeatedly reviewing its own strategy, recognizing dead ends, and trying new approaches. Zhipu AI describes optimization across "hundreds of rounds and thousands of tool calls."
The company demonstrates this with three scenarios, though all of them were conducted internally. Independent evaluations don't exist yet.
GLM-5.1 switches strategies on its own mid-task
In the first scenario, GLM-5.1 had to optimize a vector database - a system that searches large datasets and finds similar entries. The goal: answer as many search queries per second as possible without losing accuracy. In a standard test run with 50 rounds, Claude Opus 4.6 held the previous best score of 3,547 queries per second, according to Zhipu AI.
Instead, Zhipu AI gave GLM-5.1 unlimited attempts. The model decided on its own when to submit a new version and what to try next. After more than 600 iterations and over 6,000 tool calls, it reached 21,500 queries per second - roughly six times the previous best, the company says.
According to Zhipu, the model fundamentally changed its strategy multiple times during the run. Around iteration 90, it switched from exhaustively searching all data to a more efficient clustering approach. Around iteration 240, it introduced a two-stage pipeline that does rough pre-sorting before precise filtering. The company identifies six such structural shifts over the entire run, each initiated by the model itself.
GPU optimization shows progress but doesn't reach the top
In the second scenario, the model had to rewrite existing machine learning code to run faster on GPUs. GLM-5.1 achieved a 3.6x speedup over the baseline implementation and continued making progress even in later phases, according to Zhipu AI. GLM-5, by contrast, plateaued much earlier.
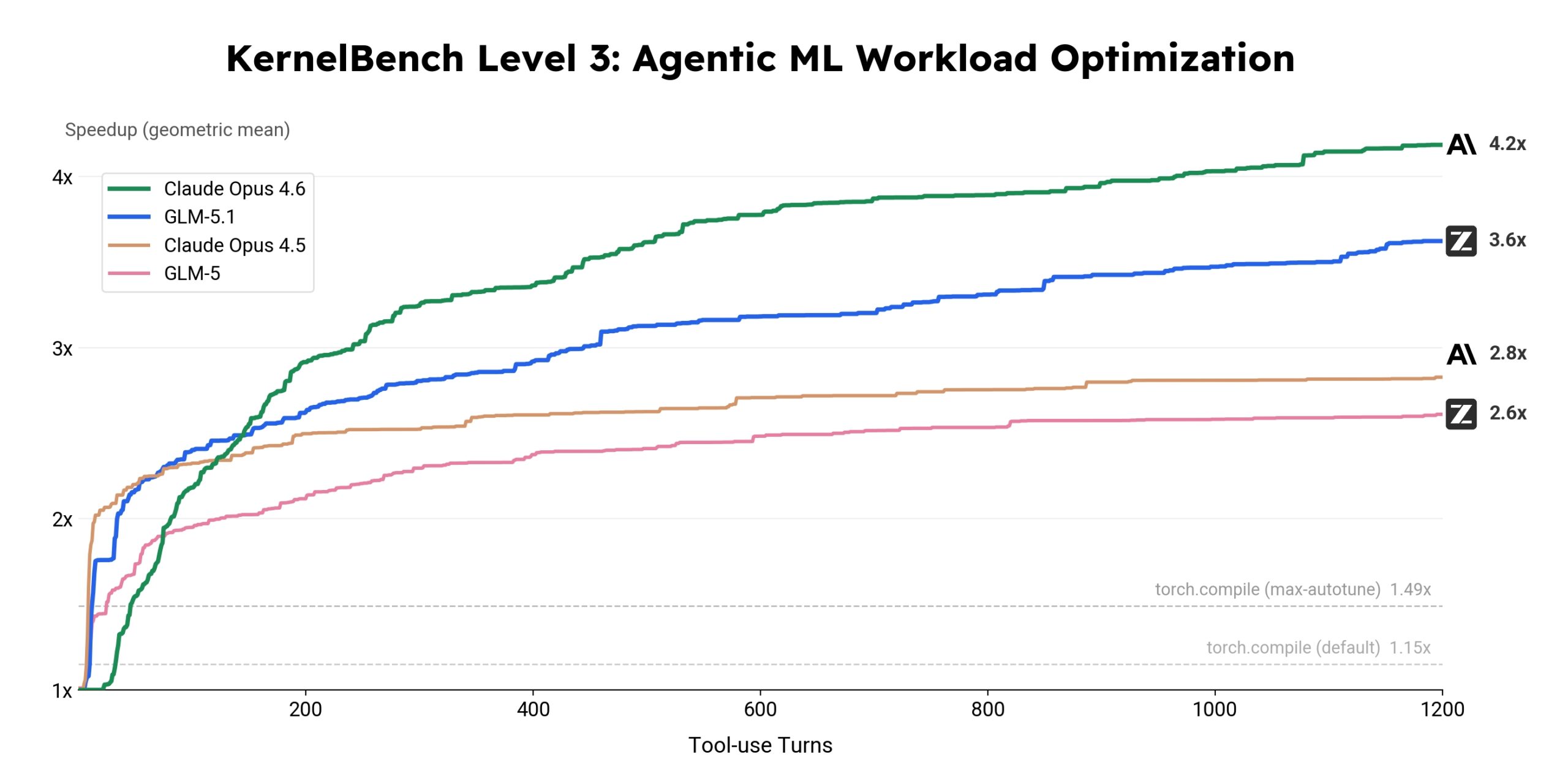
Claude Opus 4.6 remains clearly ahead in this test with a 4.2x speedup and still shows room for improvement at the end. GLM-5.1 extends the productive horizon compared to its predecessor but doesn't close the gap to the strongest competitor.
A Linux desktop from a single prompt
The third scenario is the most unusual. GLM-5.1 was asked to build a complete Linux desktop environment as a web application - no starter code, no intermediate instructions. Most models deliver a basic shell with a taskbar and a few placeholder windows, then call the job done, according to Zhipu AI.
GLM-5.1 was placed in a loop where it reviewed its own output after each round and decided what was still missing or needed improvement. After eight hours, the result was a functional desktop environment with a file browser, terminal, text editor, system monitor, calculator, and games, the company says.
Strong at coding, weaker at reasoning
Beyond the three demos, Zhipu AI published a benchmark table that paints a more nuanced picture. In coding, GLM-5.1 leads or matches the competition in several tests. On SWE-Bench Pro, a software engineering benchmark, it scores 58.4 percent - the highest among all tested freely available models, according to Zhipu AI, just ahead of GPT-5.4 at 57.7 percent and Claude Opus 4.6 at 57.3 percent. On CyberGym, a cybersecurity benchmark, it posts the top score of 68.7. Zhipu AI acknowledges, however, that Gemini 3.1 Pro and GPT-5.4 refused to execute some tasks for safety reasons, which likely dragged down their scores.
On Humanity's Last Exam, a knowledge test, the model scores 31 percent - behind Gemini 3.1 Pro at 45 and GPT-5.4 at 39.8. On scientific questions (GPQA-Diamond), it also trails with 86.2 compared to Gemini 3.1 Pro at 94.3 and GPT-5.4 at 92.
Results on agent-based tasks are mixed as well. In Vending Bench 2, where a model has to run a simulated vending machine business, GLM-5.1 ends up with a balance of $5,634. Claude Opus 4.6 reaches $8,018 - significantly more. On repository generation (NL2Repo), Claude Opus 4.6 also leads clearly with 49.8 versus GLM-5.1's 42.7.
On the Artificial Analysis Intelligence Index, the model currently sits just behind Anthropic's Claude 4.6 Sonnet.
Zhipu AI openly names remaining challenges: the model needs to recognize dead ends sooner, maintain coherence across thousands of tool calls, and reliably self-assess on tasks without clear metrics. GLM-5.1 is a "first step" in that direction, the company says.
The model is available under an MIT license on Hugging Face and ModelScope, and can be accessed through the API platforms api.z.ai and BigModel.cn. It integrates with coding agents like Claude Code and OpenClaw. For local deployment, Zhipu AI supports the inference frameworks vLLM and SGLang, with setup guides in the GitHub repository. Access through the Z.ai chat interface is expected to go live in the coming days.
Zhipu AI is rapidly expanding its model lineup
Zhipu AI recently introduced GLM-5V-Turbo, a multimodal coding model that generates code directly from images and video. Before that, the company released GLM-5 in February, an open-weight model with 744 billion parameters designed to compete with leading proprietary models on coding tasks. GLM-5.1 likely builds on both and adds the long-horizon capabilities Zhipu AI hopes will set it apart from Chinese competitors. That competition remains fierce: alongside Zhipu AI, Moonshot AI with Kimi K2.5 and Alibaba with Qwen3.5 are also pushing hard into the autonomous coding agent market.
Zhipu AI isn't the only company betting on long-running AI agents. In early 2026, Cursor had hundreds of GPT-5.2 agents spend a week building a web browser. The resulting three million-plus lines of Rust code turned out to be nearly unmaintainable, landing in the bottom five percent of all evaluated software systems according to an analysis by the Software Improvement Group.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now