Stability AI's new open-source chatbot uses ChatGPT's special sauce

Stability AI releases StableVicuna, the first large-scale open-source chatbot trained with human feedback.
Stability AI, the company behind the successful open-source image model Stable Diffusion, releases StableVicuna, an open-source chatbot. The chatbot is based on the Vicuna chatbot released in early April, which is a 13 billion parameter LLaMA model tuned with the Alpaca formula.
What is special about the Vicuna variant of Stability AI and Carper AI is that the model was improved using so-called "Reinformcent Learning with Human Feedback" (RLHF) (see below for explanation).
This was done using datasets from OpenAssistant, Anthropic, and Stanford University, as well as the open-source training framework rlX, also from Carper AI. Stability AI is working with OpenAssistant on larger RLHF datasets for future models.
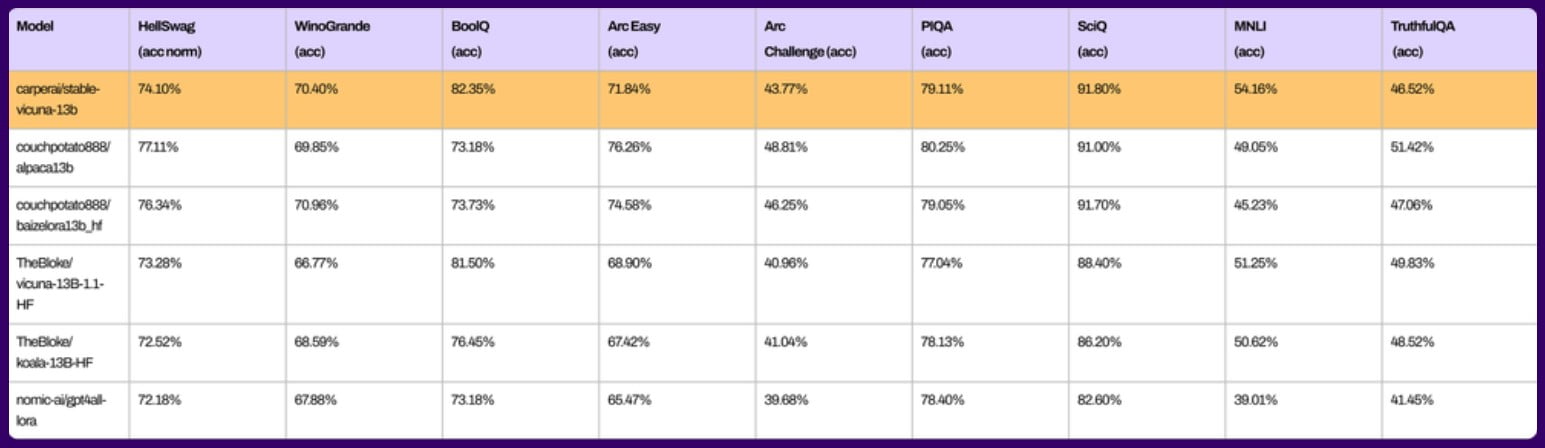
According to Stability AI, StableVicuna does simple math in addition to text generation and can write code. In common benchmarks, StableVicuna is on par with previously released open-source chatbots. However, benchmarks are only partially indicative of how a model will perform in practice.
According to Stability AI, StableVicuna will be developed further and launched on Discord soon. A demo is now available on HuggingFace. Stability AI also plans to make StableVicuna available through a chat interface soon.
Alongside our chatbot, we are excited to preview our upcoming chat interface which is in the final stages of development. The following screenshots offer a glimpse of what users can expect. pic.twitter.com/yzODUySP9W
- Stability AI (@StabilityAI) April 28, 2023
Developers can download the model's weights as a delta to the original LLaMA model at Hugging Face. Those who want to use StableVicuna themselves will need access to the original LLaMA, which can be requested here. Commercial use is not allowed.
The problem with open-source chatbots that are refined with generated chatbot data is the risk of an echo chamber, in which the AI models reinforce their existing errors and biases through ever new training processes. In addition, training data generated for fine-tuning can reinforce hallucinations if it contains information not present in the original model.
Background: With RLHF to a useful chatbot
Reinforcement learning with human feedback (RLHF) was the key to ChatGPT's success: Only through the small-scale feedback work of thousands of people providing detailed ratings on the usefulness of tens of thousands of chat outputs could the chatbot be tuned to always feel it has an appropriate response ready.
RLHF also ensures that the chatbot's output stays within certain social norms. For example, it does not encourage crime. Without RLHF, GPT-4 would be much more difficult to use. It could generate very extreme content, such as detailed suggestions for the systematic annihilation of humanity.
As the drawing in the following tweet humorously illustrates, the RLHF-enhanced chatbot is just a small part of a large language model optimized for human interaction.
— w̸͕͂͂a̷͔̗͐t̴̙͗e̵̬̔̕r̴̰̓̊m̵͙͖̓̽a̵̢̗̓͒r̸̲̽ķ̷͔́͝ (@anthrupad) February 5, 2023
Just a few days ago, Stability AI launched the StableLM open-source language model family. More information and downloads are available on Stability AI's Github.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.