AI agent Dynalang could change the way we talk to robots

Dynalang is an AI agent that understands language and its environment by making predictions about the future in environments with a multimodal world model.
A major challenge in AI research is to enable AI agents, such as robots, to communicate naturally with humans. Today's agents, such as Google's PaLM-SayCan, understand simple commands like "get the blue block". But they struggle with more complex language situations, such as knowledge transfer ("the top left button turns off the TV"), situational information ("we're running out of milk"), or coordination ("the living room has already been vacuumed").
For example, when an agent hears "I put the bowls away," it should respond differently depending on the task: If it is washing dishes, it should move on to the next cleaning step; if it is serving dinner, it should go get the bowls.
In a new paper, UC Berkeley researchers hypothesize that language can help AI agents anticipate the future: what they will see, how the world will react, and what situations are important. With the right training, this could create an agent that learns a model of its environment through language and responds better in those situations.
The key idea of Dynalang is that we can think of language as helping us make better predictions about the world:
"out of milk”→ 🥛 no milk if we open fridge
“wrenches tighten nuts”→ 🔧 nut rotates when using tool
(instructions too!) “get blue block”→ 🏆 reward if picked up— Jessy Lin (@realJessyLin) August 4, 2023
Dynalang relies on token and image prediction in Deepmind's DreamerV3
The team is developing Dynalang, an AI agent that learns a model of the world from visual and textual input. It is based on Google Deepmind's DreamerV3, condenses the multimodal inputs into a common representation, and is trained to predict future representations based on its actions.
The approach is similar to training large language models that learn to predict the next token in a sentence. What makes Dynalang unique is that the agent learns by predicting future text as well as observations - meaning images - and rewards. This also makes it different from other reinforcement learning approaches, which usually only predict optimal actions.
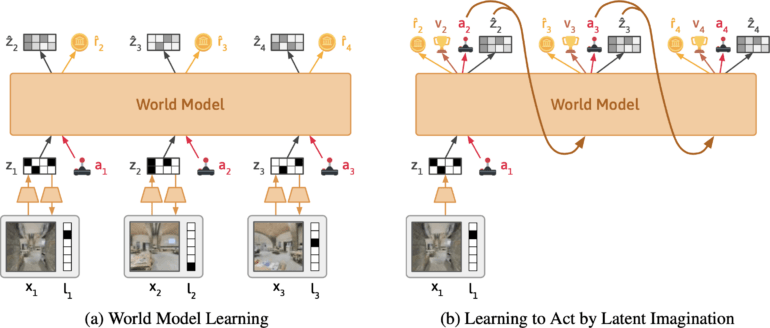
According to the team, Dynalang extracts relevant information from text and learns multimodal associations. For example, if the agent reads, "The book is in the living room," and later sees the book there, the agent will correlate the language and visuals through their impact on its predictions.
The team evaluated Dynalang in a number of interactive environments with different language contexts. These included a simulated home environment, where the agent receives cues about future observations, dynamics, and corrections to perform cleaning tasks more efficiently; a gaming environment; and realistic 3D house scans for navigation tasks.
🛋 In Habitat, we test Dynalang on instruction following in a more visually complex env with real natural language, learning to follow navigation instructions in scanned homes from scratch. pic.twitter.com/eawXgeQC4R
— Jessy Lin (@realJessyLin) August 4, 2023
Dynalang can also learn from web data
Dynalang has learned to use language and image prediction for all tasks to improve its performance, often outperforming other specialized AI architectures. The agent can also generate text and read manuals to learn new games. The team also shows that the architecture allows Dynalang to be trained with offline data without actions or rewards - that is, text and video data that is not actively collected as it explores an environment. In one test, the researchers trained Dynalang with a small dataset of short stories, which improved the agent's performance.
Video: Lin et al.
"The ability to pretrain on video and text without actions or rewards suggests that Dynalang could be scaled to large web datasets, paving then way towards a self-improving multimodal agent that interacts with humans in the world."
The team cites as limitations the architecture used, which is not optimal for certain long-horizon environments. In addition, the quality of the text produced is still far from that of large language models, but could approach it in the future.
More information and the code is available on the Dynalang project page.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.