A new website makes AI training images searchable
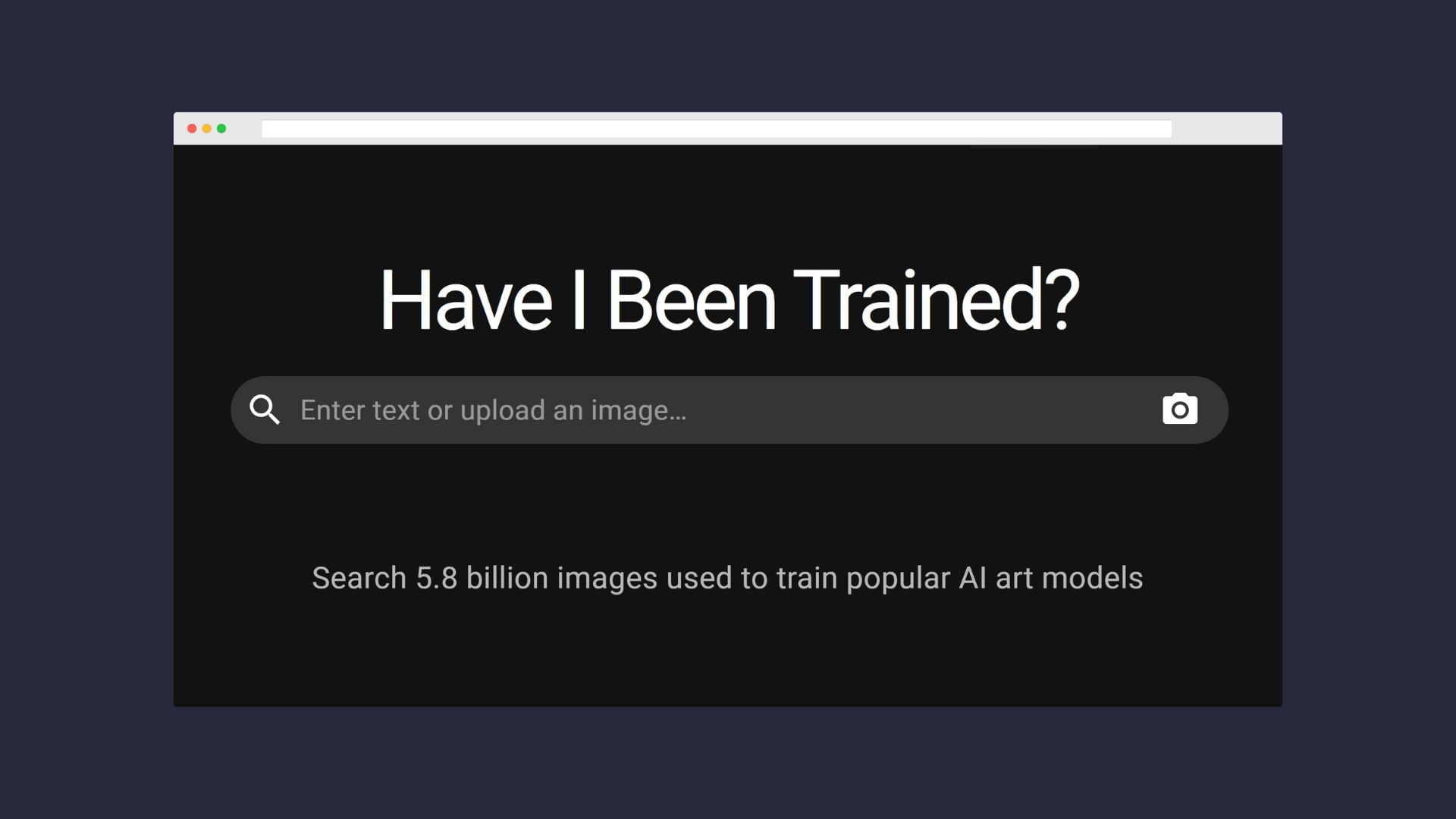
A new website shows anyone interested more than five billion images used to train AI systems such as DALL-E 2, Midjourney and Stable Diffusion.
The rapid development of current generative image AI systems such as DALL-E 2, Midjourney and Stable Diffusion is only possible thanks to an enormous amount of data. The systems require millions of images annotated with labels to learn the visual properties of numerous terms. The training raises questions about copyright and privacy.
One such dataset that was used to train Stable Diffusion, DALL-E 2, and Midjourney is called LAION-5B and contains more than five billion images. The LAION dataset was previously publicly available, but did not provide an easy way to search. This changes with haveibeentrained.com, which displays related training material based on either individual keywords or a reverse image search.
Spawning AI is behind the project. "We believe that the best path forward is to offer individual artists tools to manage their style and likenesses, and determine their own comfort level with a changing technological landscape," their website states.
"We are not focused on chasing down individuals for experimenting with the work of others. Our concern is less with artists having fun, rather with industrial-scale usage of artist training data."
Woman discovers photo from her medical records in AI training material
The website proved its usefulness shortly after its release. A woman discovered a medical image of herself in the database that shouldn't have ended up there. According to Twitter user Lapine, that photo had been taken in 2013 as part of clinical documentation. She had signed a declaration stating that the photo was only intended for her file and not for the public.
🚩My face is in the #LAION dataset. In 2013 a doctor photographed my face as part of clinical documentation. He died in 2018 and somehow that image ended up somewhere online and then ended up in the dataset- the image that I signed a consent form for my doctor- not for a dataset. pic.twitter.com/TrvjdZtyjD
— Lapine (@lapine___) September 16, 2022
Lapine is apparently not an isolated case, as Ars Technica found out in a search. "During our search for Lapine's photos, we also discovered thousands of similar patient medical record photos in the data set, each of which may have a similar questionable ethical or legal status, many of which have likely been integrated into popular image synthesis models that companies like Midjourney and Stability AI offer as a commercial service."
People can't suddenly create an AI version of Lupine's face now, in part because her name wasn't associated with the photo. But it bothers her that private, medical images are now part of a product, Lapine said.
Rights for AI training could be explicitly granted in advance in the future
The LAION dataset contains links to images on the Internet and not the image itself. According to LAION's privacy policy, providing name and face is a prerequisite for deleting an image link. Alternatively, you can try to delete the image directly at the source.
An unnecessarily complicated process, finds the team at haveibeentrained.com, which wants to create a standard for this matter with Source+. They propose that in the future, artists and others will be able to flip a switch before uploading whether or not their work can be used for AI training. However, if images are published illegally on the Internet, like Lapine's medical images, even this switch won't help.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.