AI agent benchmarks obsess over coding while ignoring 92% of the US labor market, study finds
Key Points
- A study by Carnegie Mellon and Stanford University reveals that current AI agent benchmarks are heavily skewed toward programming tasks, while economically significant fields like management or law remain largely underrepresented.
- The imbalance extends to individual skills as well: benchmarks primarily evaluate information retrieval and computer-based work, while critical capabilities such as interpersonal interaction are almost entirely ignored.
- The researchers advocate for more realistic benchmarks that cover underrepresented domains and assess not just outcomes but also the intermediate steps agents take to reach them.
A large-scale study shows that AI agent development focuses almost entirely on programming tasks, ignoring the vast majority of the labor market.
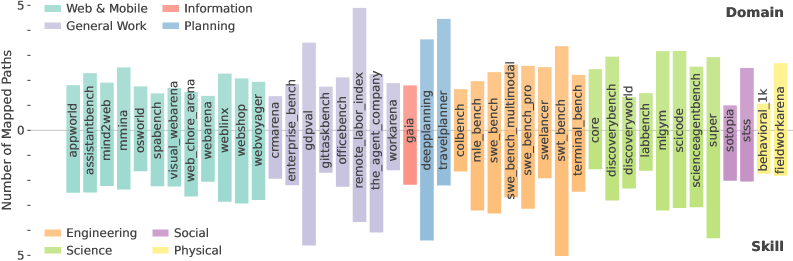
Researchers from Carnegie Mellon University and Stanford University systematically compared 43 agent benchmarks totaling 72,342 tasks against the US labor market. They mapped benchmark tasks to 1,016 real occupations using the US government's O*NET database, which catalogs work activities at multiple levels of detail.

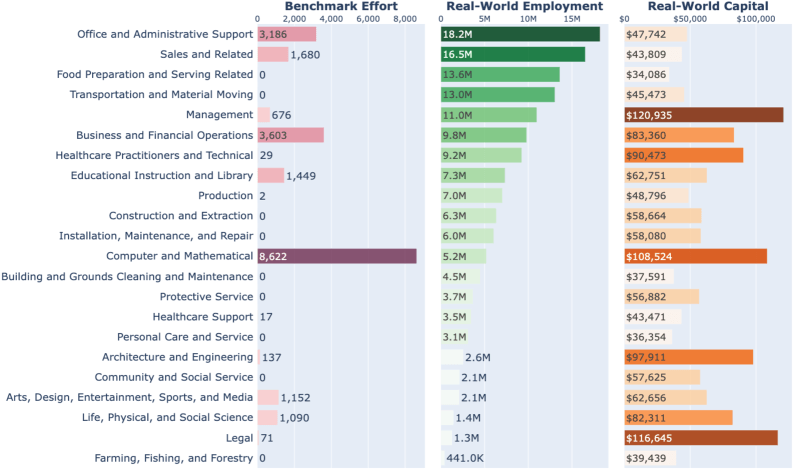
The study paints a lopsided picture. Current agent development targets the computer and math domain almost exclusively, a field dominated by programming that makes up just 7.6 percent of total US employment.
Highly digitized industries get almost zero benchmark coverage
The analysis turned up several work areas that are heavily digitized but barely show up in existing benchmarks. Management has a digitization rate of 88 percent, yet it represents just 1.4 percent of all benchmark tasks analyzed. Legal work (70 percent digital) accounts for 0.3 percent, and architecture and engineering (71 percent digital) for a mere 0.7 percent.
The researchers argue that AI agents could deliver near term productivity gains in exactly these areas. But these domains also come with specific technical challenges, including ambiguous goals and results that can only be verified over long stretches of time.
The study also identifies an economic blind spot. When looking at capital distribution, meaning total income per professional field, the most economically valuable areas like management and law remain underrepresented in benchmarks. At the same time, poorly paid, labor intensive fields like personal services and care barely get a look either, the researchers write.
Agents cover less than five percent of the skills workers actually need
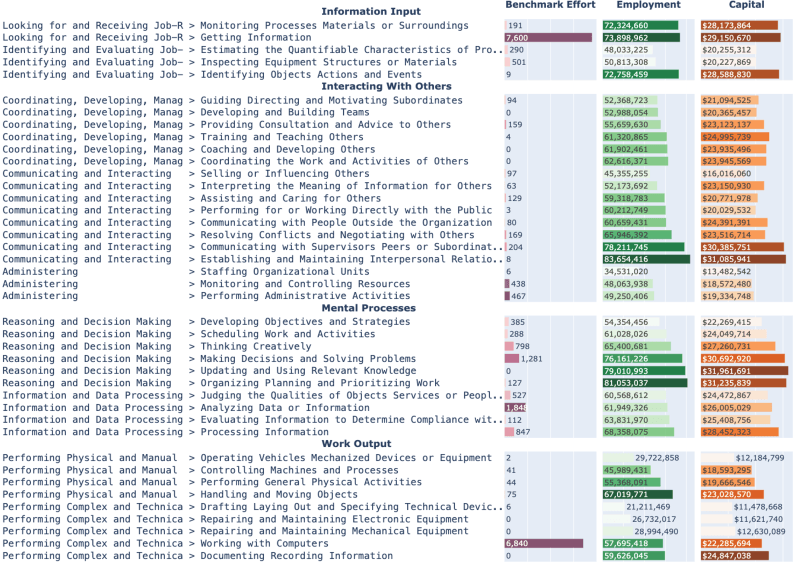
The imbalance runs just as deep at the individual skill level, according to the study. The researchers built a taxonomy that breaks professional skills into four categories: information intake, mental processes, interaction with others, and work outcomes. In the real world, the required skills spread fairly evenly across all four.
Agent benchmarks, though, zero in on just two: "Getting Information" and "Working with Computers." Together, these cover less than five percent of US employment. The "Interacting with Others" category, which touches a huge share of real world jobs, barely registers in the benchmarks at all, the researchers found.
The researchers attribute this bias to methodological convenience. Domains where it's easy to write task instructions and check results get disproportionate attention. While this has driven fast progress in niche areas, the team warns it risks steering agent development away from the fields where the social and economic payoff would be biggest.
The researchers single out OpenAI's GDPval benchmark as a positive example. Despite its relatively small size, it covers the widest range of professional domains and skills. OpenAI specifically designed the 2025 benchmark to measure how AI agents affect real knowledge work across different fields.
Agent autonomy falls off a cliff as tasks get harder
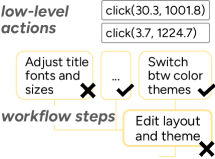
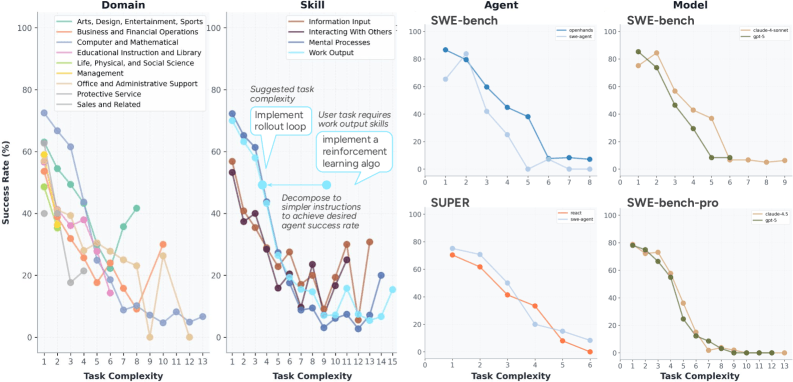
To gauge how autonomously AI agents actually operate within the work areas they cover, the researchers developed a quantifiable measure of autonomy. They define it as the maximum task complexity an agent can handle at a given success rate, with complexity measured by the number of steps in a hierarchical workflow.
Even in software development, the most heavily represented field, the study shows success rates dropping sharply as tasks get more complex. According to the findings, agents do best on independent activities like mental processes and producing work products but struggle with finding and retrieving information and coordinating with others, even on relatively simple tasks.
The few benchmarks that allow controlled comparisons, like SWE-bench, show the OpenHands framework outperforming SWE-agent and Claude beating GPT, especially on medium-complexity tasks. However, the researchers caution that these trends don't necessarily hold at other complexity levels and call for broader publication of agent trajectories to enable more systematic comparisons.
What better benchmarks should look like
Based on their findings, the researchers lay out three design principles for future benchmarks. First, new benchmarks should specifically target underrepresented but highly digitized domains like management and law, or aim for broad coverage across domains and skills.
Second, the team argues that benchmarks need to get more realistic and complex. Their analysis found that many automatically generated benchmarks only capture simplified fragments of real work. By contrast, human created tasks, like those in the GDPval or TheAgentCompany benchmarks, span diverse domains and skills. When automated generation is needed for scale, the researchers say task creation should reflect realistic domain and skill compositions.
Third, the researchers push for more granular evaluation. Simply measuring whether an agent finished a task misses where exactly it broke down, they argue. Instead, they suggest automatically deriving workflows from human demonstrations to create intermediate checkpoints that give a more detailed picture of agent performance. The study provides a framework and supporting resources to help benchmark designers spot gaps in work coverage, agent developers pinpoint areas for improvement, and users pick the right level of autonomy for their specific tasks.
These findings line up with real-world usage patterns. A recent Anthropic analysis based on millions of human agent interactions found that software development accounts for nearly 50 percent of all agent tool calls through the public API, while other industries clock in at just a few percentage points each. Anthropic described the current moment as the "early days of agent adoption."
A late 2025 study by UC Berkeley and partners reached a similar conclusion: in practice, companies mostly use AI agents as simple, tightly controlled tools with few autonomous steps. The biggest hurdle, according to that study, remains system reliability.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now