AI agents are thriving in software development but barely exist anywhere else, Anthropic study finds
Anthropic analyzed millions of human-agent interactions and found that AI agents are working more independently than ever. But there's a catch: software development accounts for nearly half of all agentic activity, while other industries are barely getting started.
Anthropic did a large-scale analysis of millions of real interactions from its coding agent, Claude Code, and the public API. The results indicate that agents are becoming more autonomous, but their use remains overwhelmingly concentrated in a single field.
Software engineering accounts for nearly 50 percent of all agent tool calls through the public API, according to the study. Business intelligence, customer service, sales, finance, and e-commerce trail far behind, none claiming more than a few percentage points of traffic.
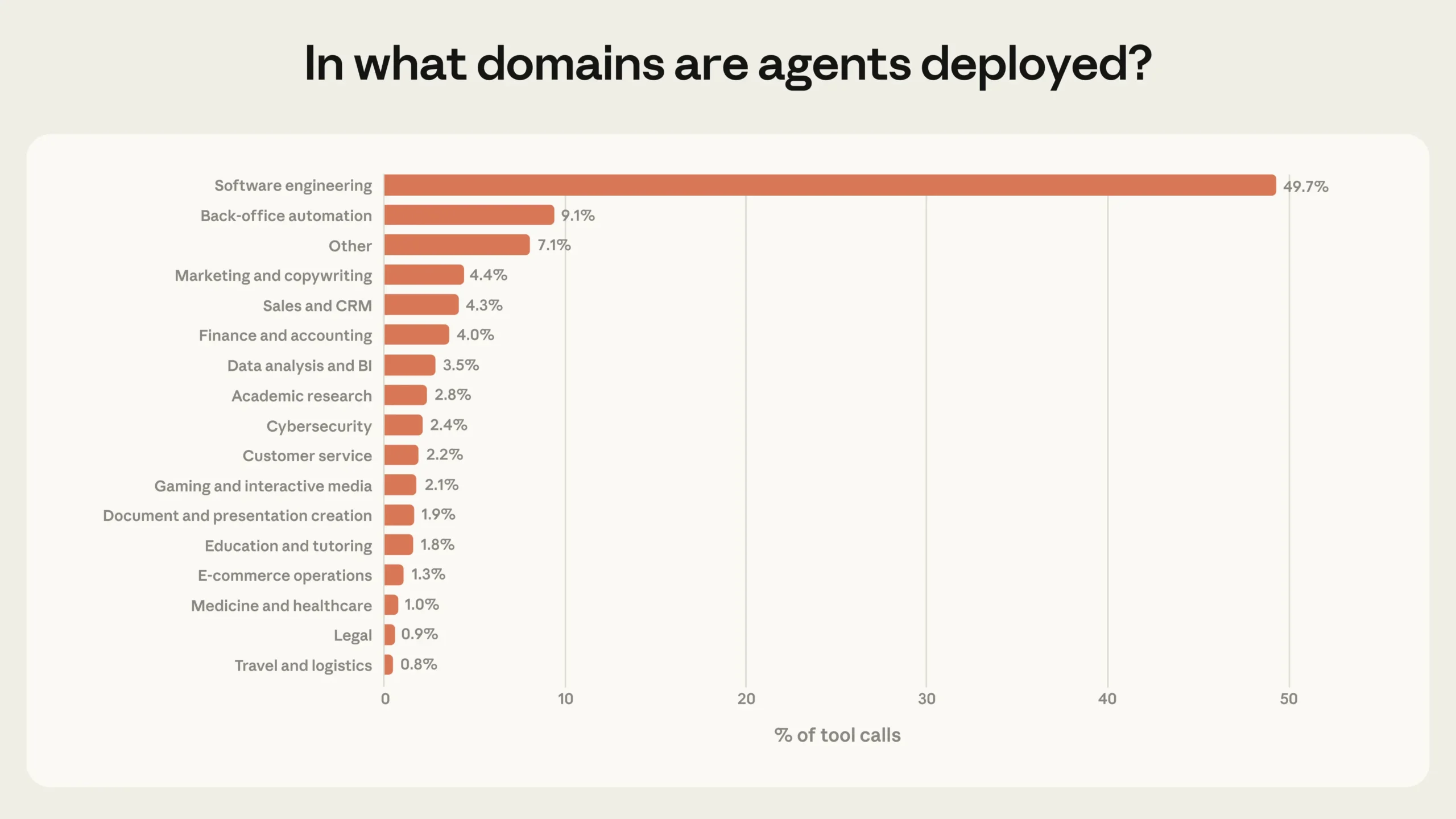
Anthropic describes this as the "early days of agent adoption." Software developers were the first to build and use agent-based tools at scale, while other industries are only starting to test the waters. For a comprehensive overview of the current state of AI agents, see our Frontier Radar on the topic (TD+ only).
Claude Code runs autonomously for longer stretches, but people aren't using its full potential
One of the most striking findings is how long Claude Code works without human intervention. The median sits around 45 seconds per work step and has stayed relatively stable, but the 99.9th percentile nearly doubled between October 2025 and January 2026, jumping from under 25 minutes to over 45 minutes.
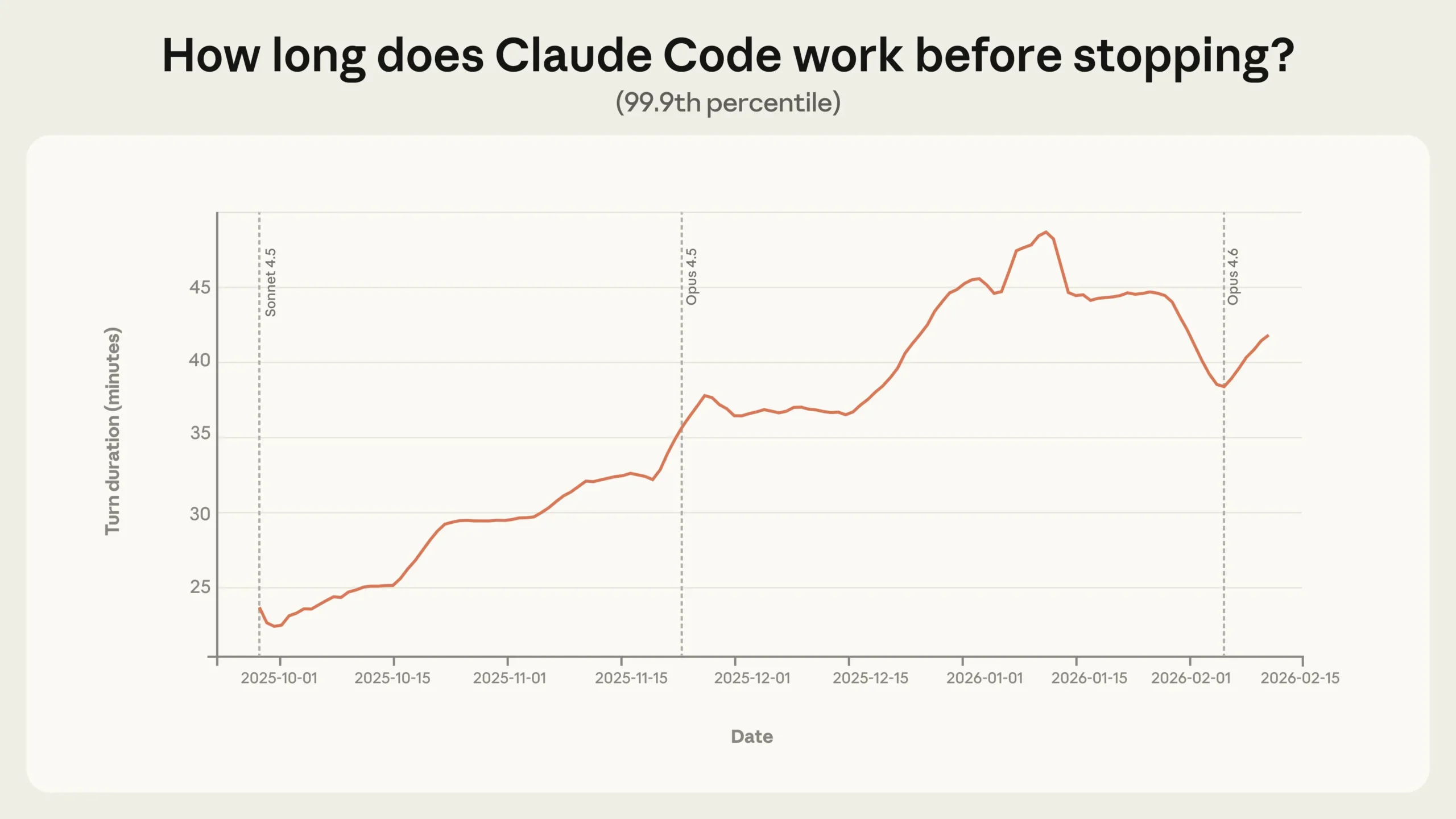
This increase holds steady across different model releases. If growing autonomy were purely a result of better model capabilities, you'd expect sharp jumps with each new release, Anthropic notes. Instead, the steady upward trend suggests multiple factors at play: experienced users building trust, setting more ambitious tasks, and the product itself improving continuously.
In this context, Anthropic describes a "deployment overhang:" the autonomy models could handle exceeds what they actually achieve in practice. OpenAI and Microsoft CEO Nadella push a similar narrative, arguing that AI models can already do more than humans ask of them. Anthropic points to an evaluation by METR estimating that Claude Opus 4.5 can solve tasks with a 50 percent success rate that would take a human nearly five hours.
Experienced users grant more freedom but don't intervene much more often
The more experienced the user, the more autonomy they give Claude Code. New users fully auto-approve about 20 percent of sessions. After roughly 750 sessions, that number climbs past 40 percent.
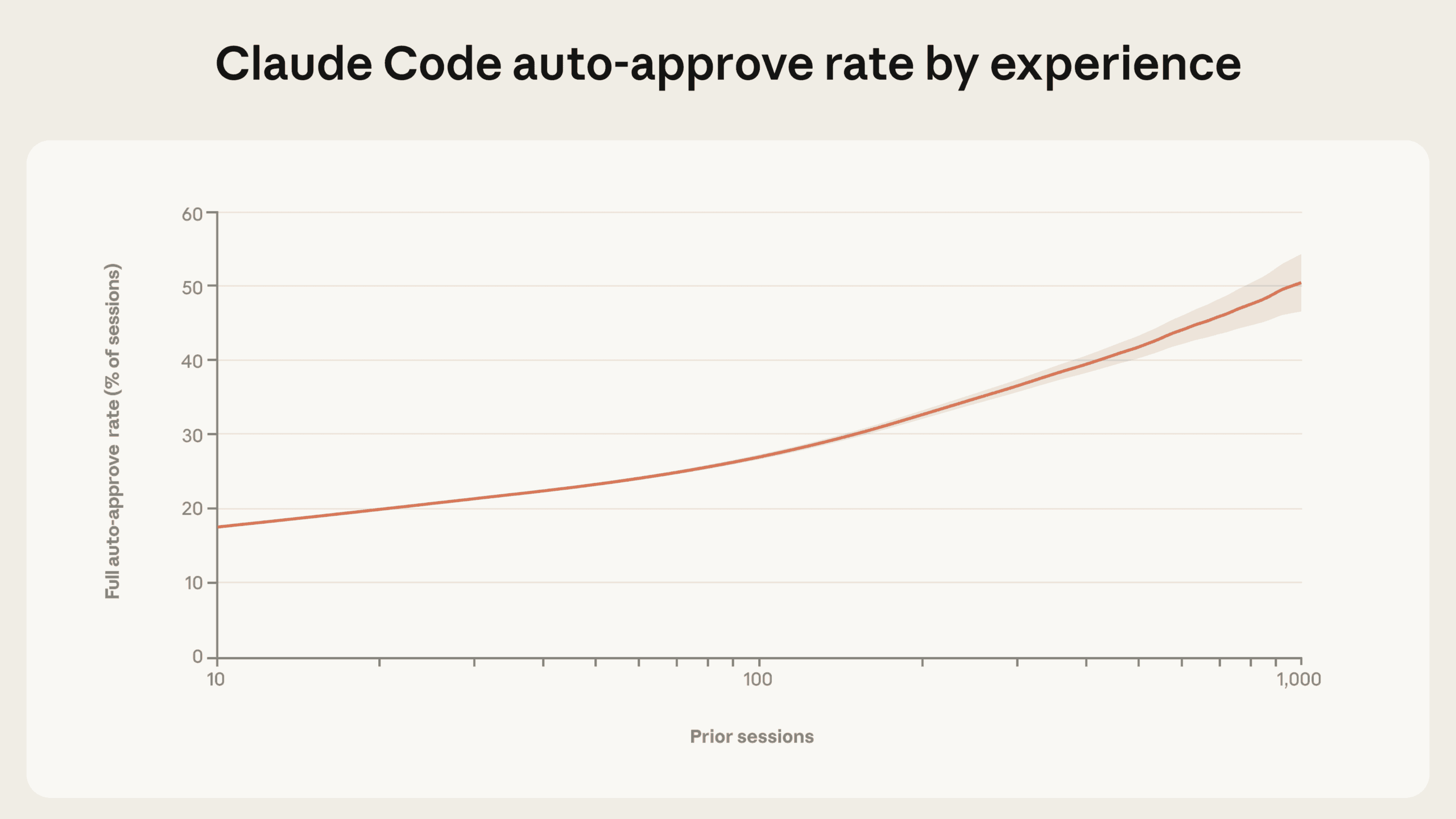
At the same time, the interruption rate ticks up slightly, from about 5 percent of work steps for new users to around 9 percent for experienced ones. Anthropic reads this as a shift in strategy: new users approve each step individually, so they rarely need to interrupt Claude mid-execution. Experienced users let Claude run autonomously and step in when something goes wrong. Both numbers are generally low, though—even experienced users don't intervene in more than 90 percent of work steps.
A similar pattern shows up on the public API. For simple tasks like editing a line of code, 87 percent of tool calls involve some form of human oversight. For complex tasks like autonomously finding zero-day exploits or writing a compiler, that drops to 67 percent.
Claude pumps its own brakes more often than humans do
Claude Code pauses itself to ask questions during complex tasks more frequently than humans interrupt it. For the most demanding tasks, Claude asks more than twice as often as it does for minimal-complexity work.
| Why does Claude stop itself? | Why do humans interrupt Claude? |
|---|---|
| To present the user with a choice between proposed approaches (35%) | To provide missing technical context or corrections (32%) |
| To gather diagnostic information or test results (21%) | Claude was slow, hanging, or excessive (17%) |
| To clarify vague or incomplete requests (13%) | They received enough help to proceed on their own (7%) |
| To request missing credentials, tokens, or access (12%) | They wanted to take the next step themselves (e.g., manual testing, deployment, committing) (7%) |
| To get approval or confirmation before taking action (11%) | To change requirements mid-task (5%) |
Anthropic sees this as an important safety mechanism: training models to recognize their own uncertainty and proactively ask for confirmation works alongside external safeguards like authorization systems and human approvals.
Looking ahead, Anthropic expects agents operating at the extremes of risk and autonomy to become more common, especially as adoption spreads beyond software engineering into higher-stakes industries.
For model developers, product builders, and policymakers, Anthropic recommends expanding post-deployment monitoring but warns against mandating specific interaction patterns. Requiring manual approval for every single agent action creates friction without necessarily improving safety, the company argues.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.