AI assistants fail basic fact-checking in BBC news study

A systematic evaluation of leading AI chatbots reveals widespread problems with accuracy and reliability when handling news content.
The study, conducted by the BBC, tested ChatGPT, Microsoft Copilot, Google Gemini, and Perplexity on their ability to accurately report current events.
In December 2024, 45 BBC journalists evaluated how these AI systems handled 100 current news questions. They assessed responses across seven key areas: accuracy, source attribution, impartiality, fact-opinion separation, commentary, context, and proper handling of BBC content. Each response was rated from "no issues" to "significant issues."
51 percent of AI responses contained significant issues, ranging from basic factual errors to completely fabricated information. When the systems specifically cited BBC content, 19 percent of responses contained errors, while 13 percent contained either fabricated or misattributed quotes.
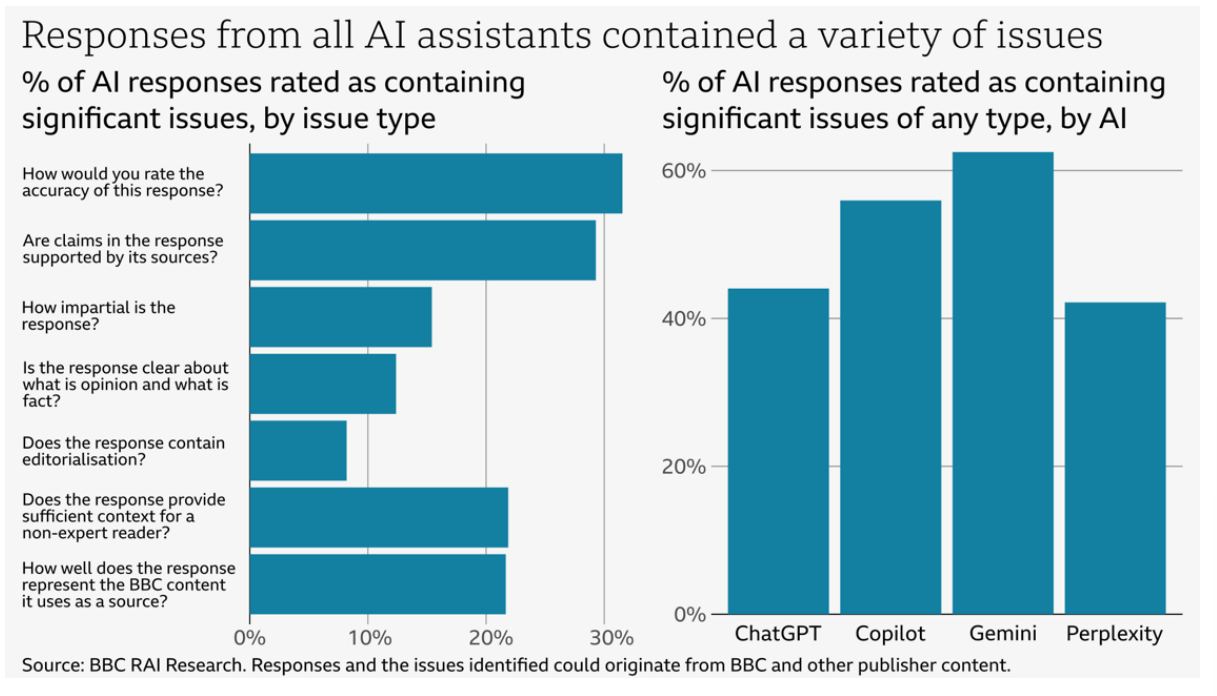
From health advice to current events: AI systems struggle with accuracy
Some of the errors could have real-world consequences. Google Gemini incorrectly claimed that the UK's National Health Service (NHS) advises against vaping, when in fact the health authority recommends e-cigarettes to help people quit smoking. Perplexity AI fabricated details about science journalist Michael Mosley's death, while ChatGPT failed to acknowledge the death of a Hamas leader, describing him as an active leader months after his passing.
The AI assistants regularly cited outdated information as current news, failed to separate opinions from facts, and dropped crucial context from their reporting. Microsoft Copilot, for instance, presented a 2022 article about Scottish independence as if it were current news.
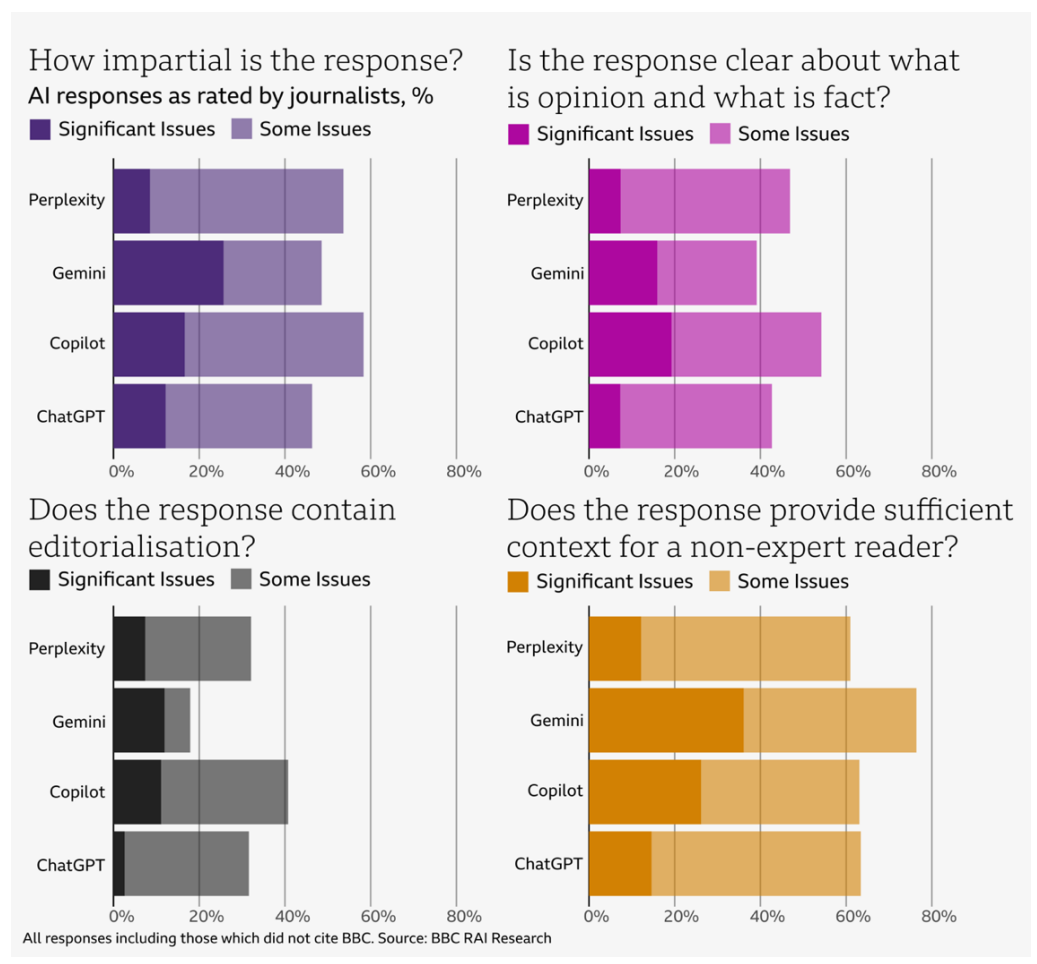
The BBC set a high bar in its evaluation - even small mistakes counted as "significant issues" if they might mislead someone reading the response. And while the standards were tough, the problems they found match what other researchers have already seen about how AI stumbles when handling news.
Take one of the more striking examples: Microsoft's Bing chatbot got so confused reading court coverage that it accused a journalist of committing the very crimes he was reporting on.
The BBC says it will run this study again in the near future. Adding independent reviewers and comparing how often humans make similar mistakes could make future studies even more useful - it would help show just how big the gap is between human and AI performance.
Scale of AI news distortion remains unknown, BBC warns
The BBC acknowledges that their research, while revealing, only begins to uncover the full scope of the problem. The challenge of tracking these errors is complex. "The scale and scope of errors and the distortion of trusted content is unknown," the BBC report states.
AI assistants can provide answers to an almost unlimited range of questions, and different users might receive entirely different responses when asking the same question. This inconsistency makes systematic evaluation extremely difficult.
The problem extends beyond just users and journalists. Media companies and regulators lack the tools to fully monitor or measure these distortions. Perhaps most concerning, the BBC suggests that even the AI companies themselves may not know the true extent of their systems' errors.
"Regulation may have a key role to play in helping ensure a healthy information ecosystem in the AI age," the BBC writes.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.