AI-generated Tom chases Jerry for a full minute thanks to new method from Nvidia and others

Researchers have developed a method for generating longer, more coherent AI videos that tell complex stories.
While AI video generation has improved significantly in recent months, length limitations have remained a persistent challenge. OpenAI's Sora maxes out at 20 seconds, Meta's MovieGen at 16 seconds, and Google's Veo 2 at just 8 seconds. Now, a team from Nvidia, Stanford University, UCSD, UC Berkeley, and UT Austin has introduced a solution: Test-Time Training layers (TTT layers) that enable videos up to one minute long.
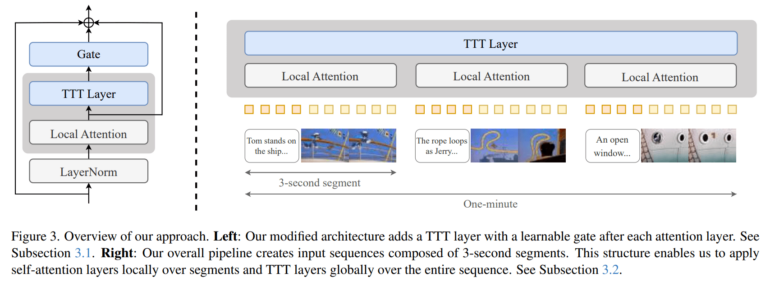
The fundamental issue with existing models stems from their "self-attention" mechanism in Transformer architectures. This approach requires each element in a sequence to relate to every other element, causing computational requirements to increase quadratically with length. For minute-long videos containing over 300,000 tokens, this becomes computationally prohibitive.
Recurrent neural networks (RNNs) offer a potential alternative since they process data sequentially and store information in a "hidden state," with computational demands that scale linearly with sequence length. However, traditional RNNs struggle to capture complex relationships over extended sequences due to their architecture.
Today, we're releasing a new paper - One-Minute Video Generation with Test-Time Training.
We add TTT layers to a pre-trained Transformer and fine-tune it to generate one-minute Tom and Jerry cartoons with strong temporal consistency.
Every video below is produced directly by... pic.twitter.com/Bh2impMBWA
- Karan Dalal (@karansdalal) April 7, 2025
How TTT layers transform video generation
The researchers' innovation replaces simple hidden states in conventional RNNs with small neural networks that continuously learn during the video generation process. These TTT layers work alongside the attention mechanism.
During each processing step, the mini-network trains to recognize and reconstruct patterns in the current image section. This creates a more sophisticated memory system that better maintains consistency across longer sequences - ensuring rooms and characters remain consistent throughout multiple scenes. A similar test-time training approach showed success in the ARC-AGI benchmark in late 2024, though that implementation relied on LoRAs.
The team demonstrated their approach using Tom and Jerry cartoons. Their dataset includes approximately seven hours of cartoon footage with detailed human descriptions.

Users can describe their video ideas with varying levels of specificity:
- A short summary in 5-8 sentences (e.g., "Tom happily eats an apple pie at the kitchen table. Jerry looks on longingly...")
- A more detailed plot of about 20 sentences, with each sentence corresponding to a 3-second segment
- A comprehensive storyboard where each 3-second segment is described by a paragraph of 3-5 sentences detailing background, characters, and camera movements
Extending video length by 20 times
The researchers built upon CogVideo-X, a pre-trained model with 5 billion parameters that originally generated only 3-second clips. By integrating TTT layers, they progressively trained it to handle longer durations - from 3 seconds to 9, 18, 30, and finally 63 seconds.
The computationally expensive self-attention mechanisms only apply to 3-second segments, while the more efficient TTT layers operate globally across the entire video, keeping computational requirements manageable. Each video is generated by the model in a single pass, without subsequent editing or montage. The resulting videos tell coherent stories spanning multiple scenes.
Despite these advances, the model still has limitations - objects sometimes change at segment transitions, float unnaturally, or experience abrupt lighting changes.
All information, examples, and comparisons with other methods are available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.