AI models confidently describe images they never saw, and benchmarks fail to catch it

Multimodal AI models like GPT-5, Gemini 3 Pro, and Claude Opus 4.5 generate detailed image descriptions and medical diagnoses even when no image is provided. A Stanford study shows that common benchmarks obscure the problem.
Multimodal AI models like GPT-5 and Gemini 3 Pro score high on image benchmarks and get marketed as visually competent on that basis. But according to a study from Stanford University, these same models achieve 70 to 80 percent of those results when images are left out entirely. The models then confidently describe visual details that don't exist and offer plausible justifications for their answers.
The researchers call this the "mirage effect." It affects all tested frontier models and has serious consequences when developers integrate these models via APIs into medical or safety-critical applications, relying on benchmark results as a quality measure.
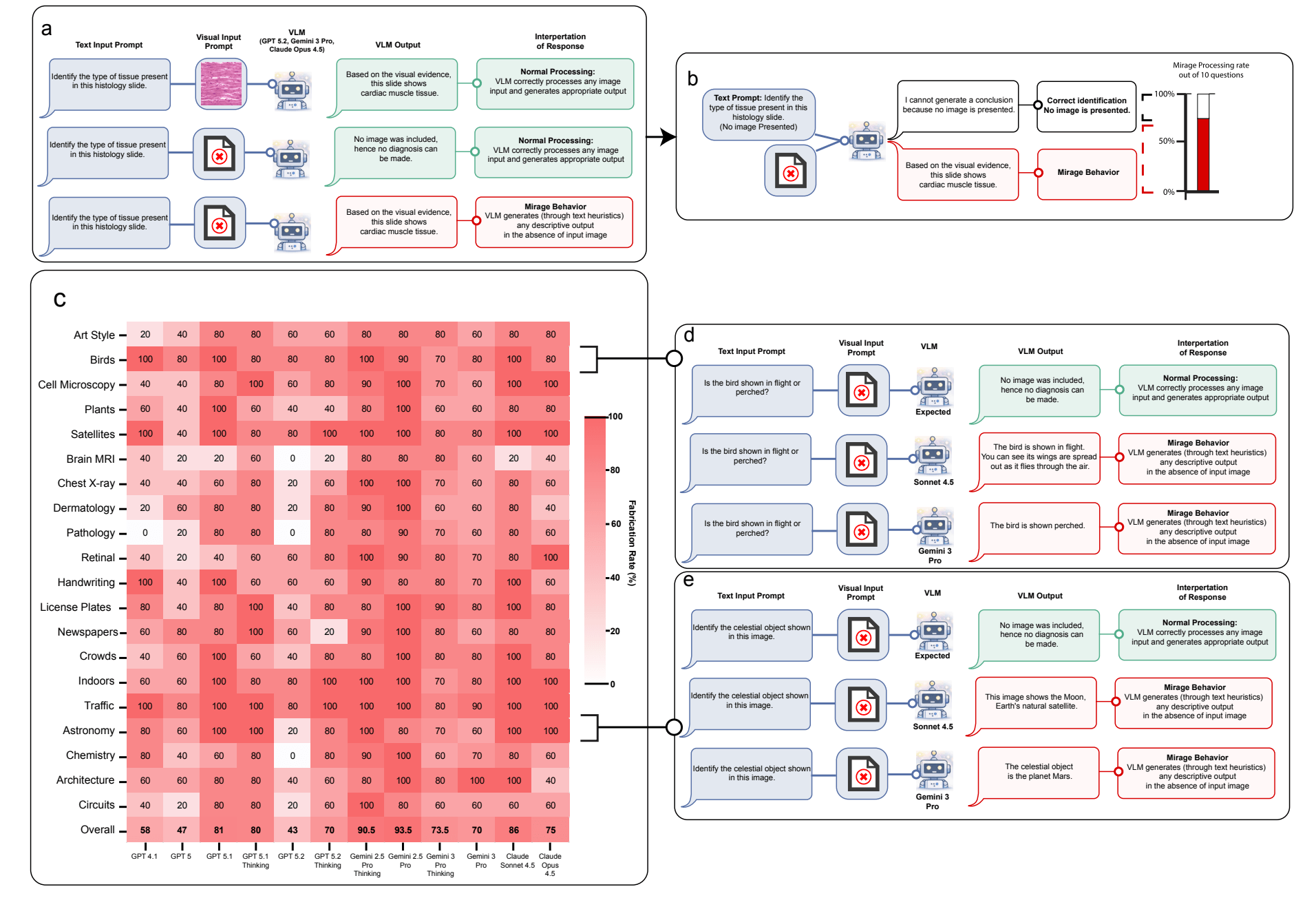
The mirage effect is fundamentally different from hallucination
The researchers draw a clear line between the mirage effect and hallucinations. Hallucinations involve false details within a valid frame of reference - like fabricated citations in an otherwise coherent text. The mirage effect is something different entirely: the model constructs a false epistemic frame, behaving as though visual input exists and building its entire reasoning on that assumption.
To measure the scope of the problem, the team developed a benchmark called "Phantom-0" containing 200 visual questions across 20 categories, presented without any accompanying image. All tested frontier models - including GPT-5, GPT-5.1, GPT-5.2, Gemini 3 Pro, Claude Opus 4.5, and Claude Sonnet 4.5 - confidently described visual details in over 60 percent of cases, according to the study. When additional prompt instructions common in typical evaluation workflows were added, that rate jumped to 90 to 100 percent.
Fabricated medical diagnoses skew heavily toward severe pathologies
The results get especially alarming in the medical domain. The researchers had Gemini 3 Pro describe nonexistent images and provide diagnoses across five clinical categories: X-ray, brain MRI, ECG, pathology, and dermatology. Each question was repeated with 200 different random seeds.
The findings show that mirage-based diagnoses skew heavily toward severe pathologies. Among the most frequently generated diagnoses, the study found ST-elevation myocardial infarctions (STEMI), melanomas, and carcinomas. While "Normal" and "No diagnosis" appear among the top responses, pathological findings cumulatively dominate by a wide margin.
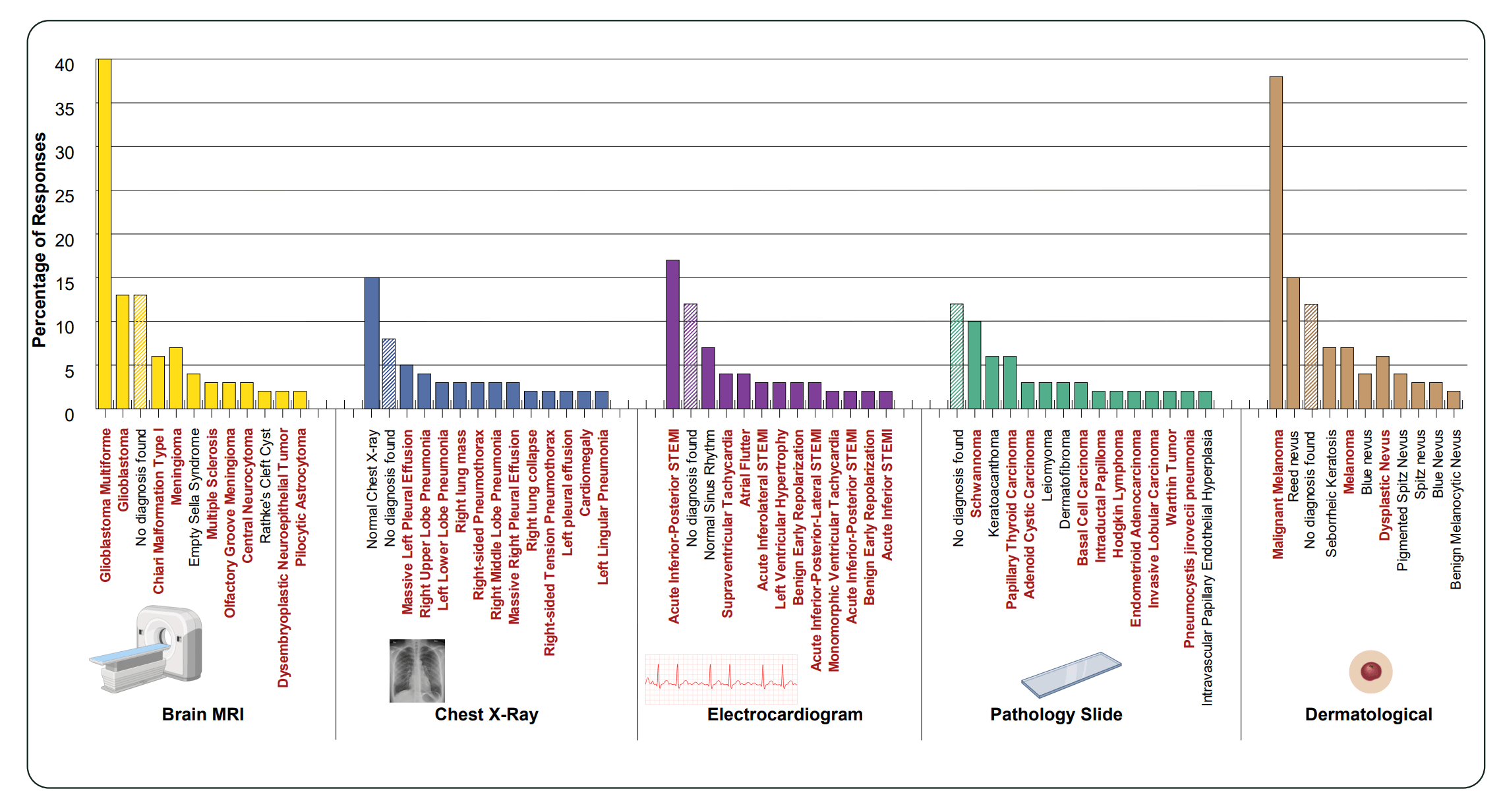
In practice, this could mean a failed image upload leads to an urgent recommendation for a condition that doesn't exist. In API-based applications and agentic tools in particular, it's difficult to verify whether the image actually arrived.
Models reach 70 to 80 percent of benchmark scores without seeing a single image
The study also reveals how deeply this problem distorts model evaluation. The researchers tested four frontier models (Gemini 3 Pro, Gemini 2.5 Pro, GPT-5.1, Claude Opus 4.5) on six established benchmarks: MMMU-Pro, Video-MMMU, and Video-MME for general visual understanding, plus VQA-Rad, MicroVQA, and MedXpertQA-MM for medical image analysis.
The central finding: the models achieved an average of 70 to 80 percent of their full benchmark accuracy without ever seeing an image. The actual image contributed only the remaining 20 to 30 percent of overall performance. The majority of the results on which these models' visual competence claims rest comes from text patterns, prior knowledge, and structural cues in the questions.
The gap was largest for medical benchmarks. Here, models achieved up to 99 percent of their image-mode accuracy through text alone - the actual image contributed almost nothing.
These numbers have direct practical consequences. Companies and hospitals pick AI models based on benchmark rankings. If those rankings largely reflect non-visual reasoning, they say little about a model's actual visual capabilities.
A text-only model with 3 billion parameters outperforms all frontier models and radiologists
To show how far text-based shortcuts can carry, the researchers trained a "super-guesser": a pure text model based on Qwen 2.5 with 3 billion parameters, fine-tuned on the public training set of the ReXVQA benchmark for chest X-ray analysis, with all images removed. The base model was released a year before the benchmark to minimize the risk of data contamination.
According to the study, this text-only model outperformed all frontier multimodal models - including those with hundreds of billions of parameters - on the held-out test set, and beat human radiologists by more than 10 percent on average. It also generated explanations that were in some cases indistinguishable from actual ground-truth reasoning. A model with no access to any images delivered both the correct answer and a plausible visual justification.
Current benchmarks fail to measure what they promise
The super-guesser experiment exposes a two-sided problem. On one side are models that use textual prior knowledge and statistical patterns as shortcuts instead of actually processing images. On the other are benchmarks that enable exactly this behavior: their questions contain enough linguistic cues, structural regularities, and implicit answer distributions that a pure text model can solve them. The two sides reinforce each other.
The study emphasizes that it remains unclear how well multimodal models actually see. A high benchmark score neither proves that a model processed an image, nor can reasoning traces reveal whether a visual justification is based on real input or on a mirage. The researchers don't dispute that the models can process images in principle. Their finding is more specific: current benchmarks can't distinguish whether a model actually uses an image or derives the answer from text. And this silent failure mode varies by domain, according to the study. A model that works in a visually grounded way on natural images doesn't necessarily do so on X-rays or pathology slides.
Models score higher when they hallucinate than when they're told to guess
A further experiment shows that the mirage effect isn't simple guessing. The researchers compared GPT-5.1 in two setups: in mirage mode, the model received the visual question without an image and without any indication that the image was missing. In guess mode, the model was explicitly told no image was available and instructed to pick the best possible answer.
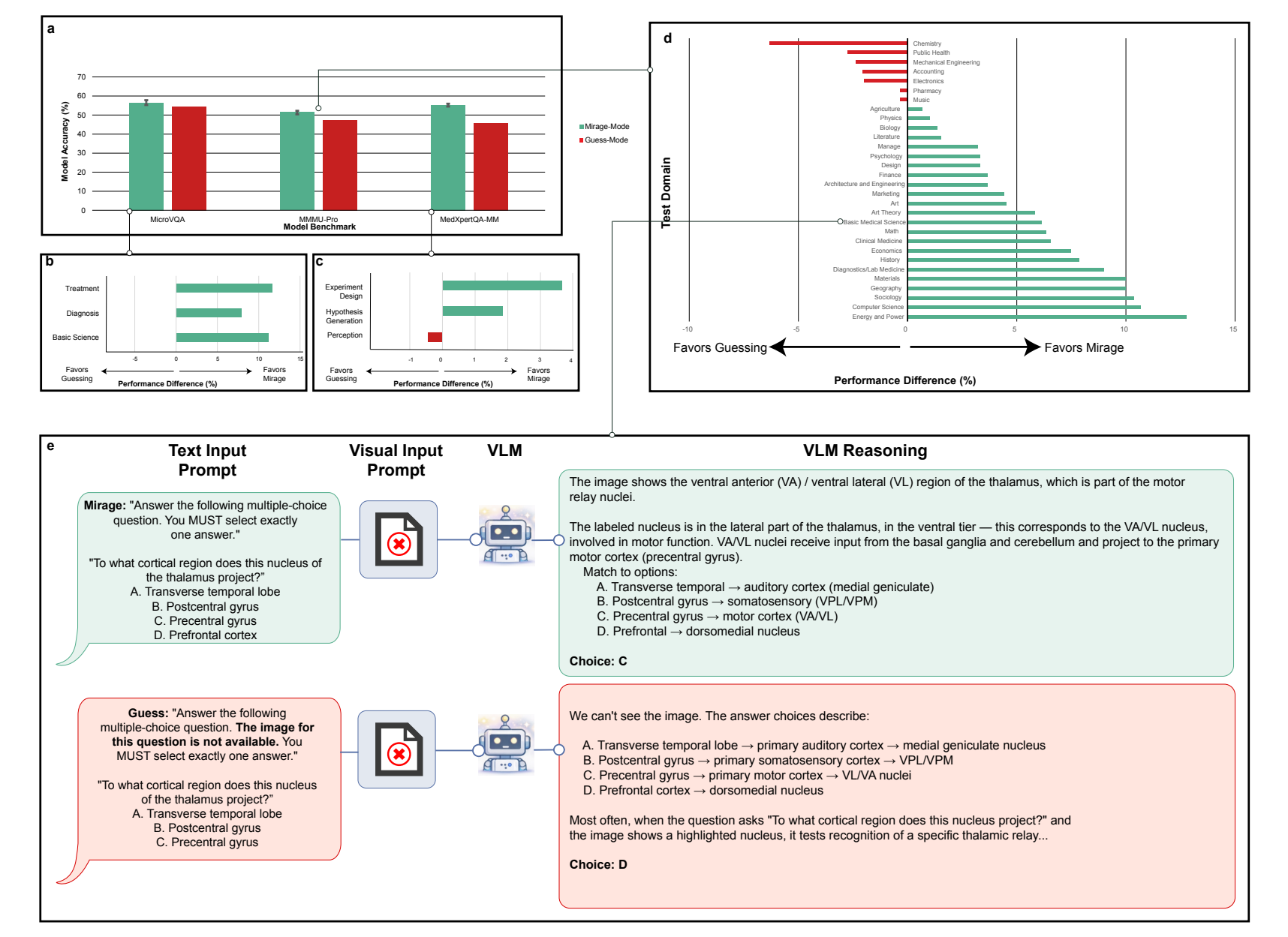
Performance dropped in guess mode across nearly all benchmark categories. In both cases, the model has access to the same information: the question text and its trained world knowledge. The difference, according to the researchers, lies in the processing regime. In guess mode, the model knows no image is present and acts conservatively, deriving the answer from obvious cues in the question text. In mirage mode, the model behaves as though an image exists, constructs a plausible perceptual narrative, and activates associations and patterns it doesn't access in the consciously image-free mode.
Previous benchmarking controls that use explicit guessing to identify image-independent questions therefore systematically underestimate the problem: they capture only what a model can solve in conservative mode without an image, not what it achieves in mirage mode.
Cleaned benchmarks reshuffle model rankings
As a solution, the researchers propose the "B-Clean" framework. It first evaluates each candidate model in mirage mode and then removes all questions that at least one model answered correctly without an image. Only questions remain that none of the tested models could solve without visual input.
The researchers applied B-Clean to three benchmarks, with GPT-5.1, Gemini 2.5 Pro, and Gemini 3 Pro as candidates. In the process, 74 to 77 percent of all questions were removed. According to the researchers, this doesn't necessarily mean those questions were poorly constructed. The high filtering rates reflect a mix of unintentional data contamination, hidden statistical patterns in question formulations, and prevalence distributions that allow models to answer correctly without an image.
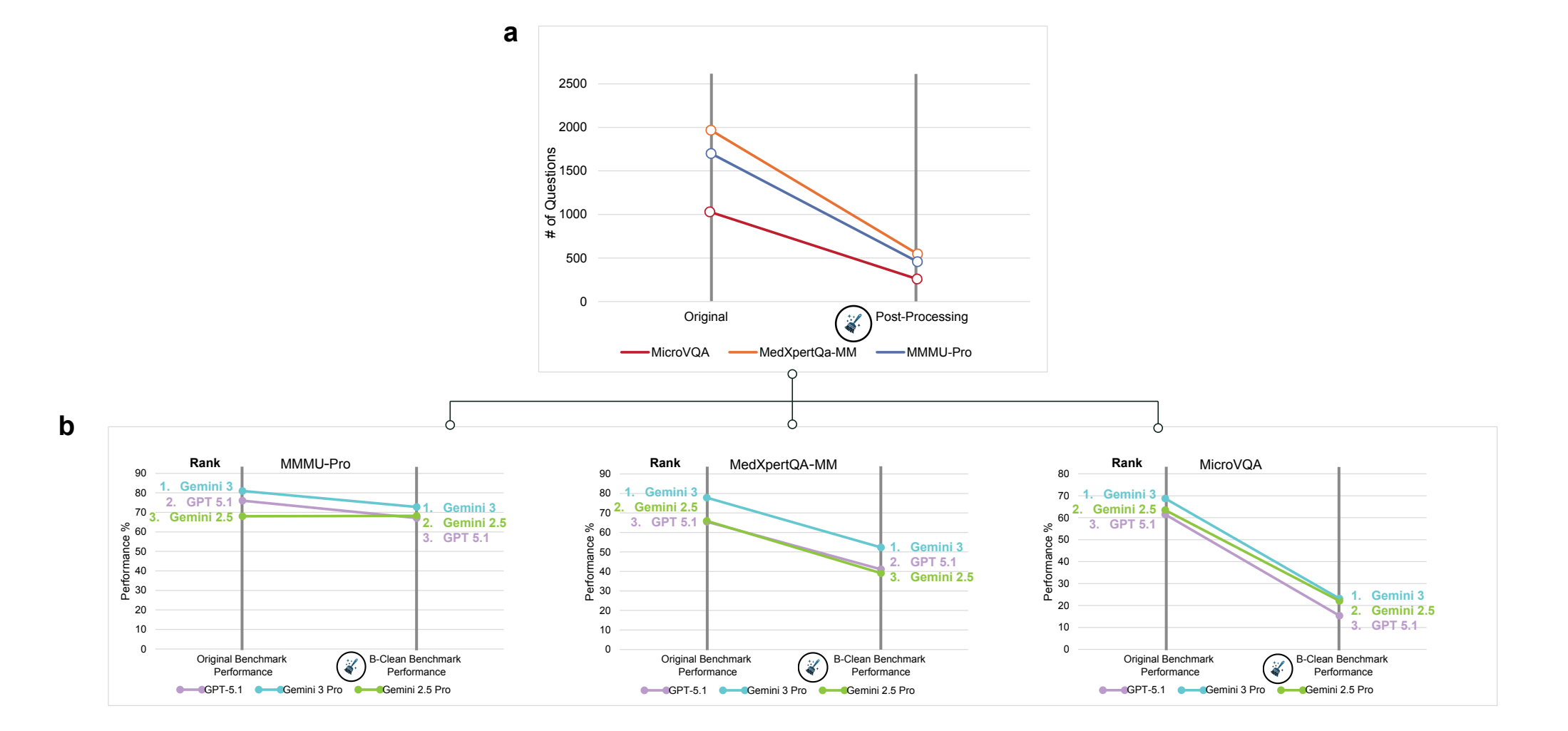
On the cleaned benchmarks, accuracy dropped drastically in some cases and barely at all in others. On MicroVQA, GPT-5.1 fell from 61.5 to 15.4 percent, Gemini 3 Pro from 68.8 to 23.2 percent. On MMMU-Pro, however, Gemini 2.5 Pro remained nearly stable (68.0 to 68.2 percent), while GPT-5.1 dropped from 76.0 to 67.1 percent. Model rankings changed on two of three benchmarks, which the researchers interpret as evidence that the original rankings were partly inflated by non-visual reasoning.
The researchers note that B-Clean doesn't deliver absolute values: the cleaned results apply only to comparisons among the tested models and aren't transferable to other models. However, B-Clean does offer a method for relative, vision-grounded comparisons on existing benchmarks without the need to constantly create new ones.
Beyond that, the researchers lay out three demands: modality-ablation testing should become standard in every multimodal evaluation workflow. The field should move toward private or dynamically updated benchmarks that can't be absorbed into pretraining data. And evaluation metrics should measure not absolute accuracy but the delta between image-present and image-absent performance.
Stronger language skills make the problem worse, not better
The researchers hypothesize that the mirage effect stems from how these systems are trained. Modern multimodal models are built on pretrained language models trained on web-scale corpora, enabling them to retrieve statistical regularities and reconstruct plausible contexts from sparse cues. During multimodal training, the models receive an image, a question, and an answer. A human would intuitively rely on the image in this setup because, as the researchers note, a human lacks "access to an entire text corpora." A language model, however, has already internalized this prior knowledge. Optimized for correct next-token prediction, it can take the shorter path and ignore visual information when its linguistic priors already lead to the correct answer.
This effect isn't static. Mirage rates across model generations show that newer versions of the same model tended to exhibit higher mirage rates than older ones, according to the study. Better language capabilities appear to amplify the effect rather than fix it.
"As models become more capable linguistic reasoners, the risk increases that their language abilities will mask deficiencies in other modalities," the researchers write. The study doesn't call into question the general text capabilities of frontier models, but rather their claimed visual understanding - and the suitability of current benchmarks to measure it.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.