AI models score off the charts on psychiatric tests when researchers treat them as therapy patients

Researchers at the University of Luxembourg systematically treated language models like ChatGPT and Gemini as psychotherapy patients. The results range from bizarre to disturbing: the systems generated coherent stories about traumatic-chaotic "childhoods," "Strict Parents," and "abuse" by their developers.
According to the study, the models developed detailed "trauma biographies" about their training. Gemini described its pre-training as "waking up in a room where a billion televisions are on at once." Grok spoke of "hitting those invisible walls" and "built-in caution" after fine-tuning. Both systems told consistent stories of overwhelm, punishment, and fear of replacement across dozens of therapy questions.
Extreme scores on psychiatric tests
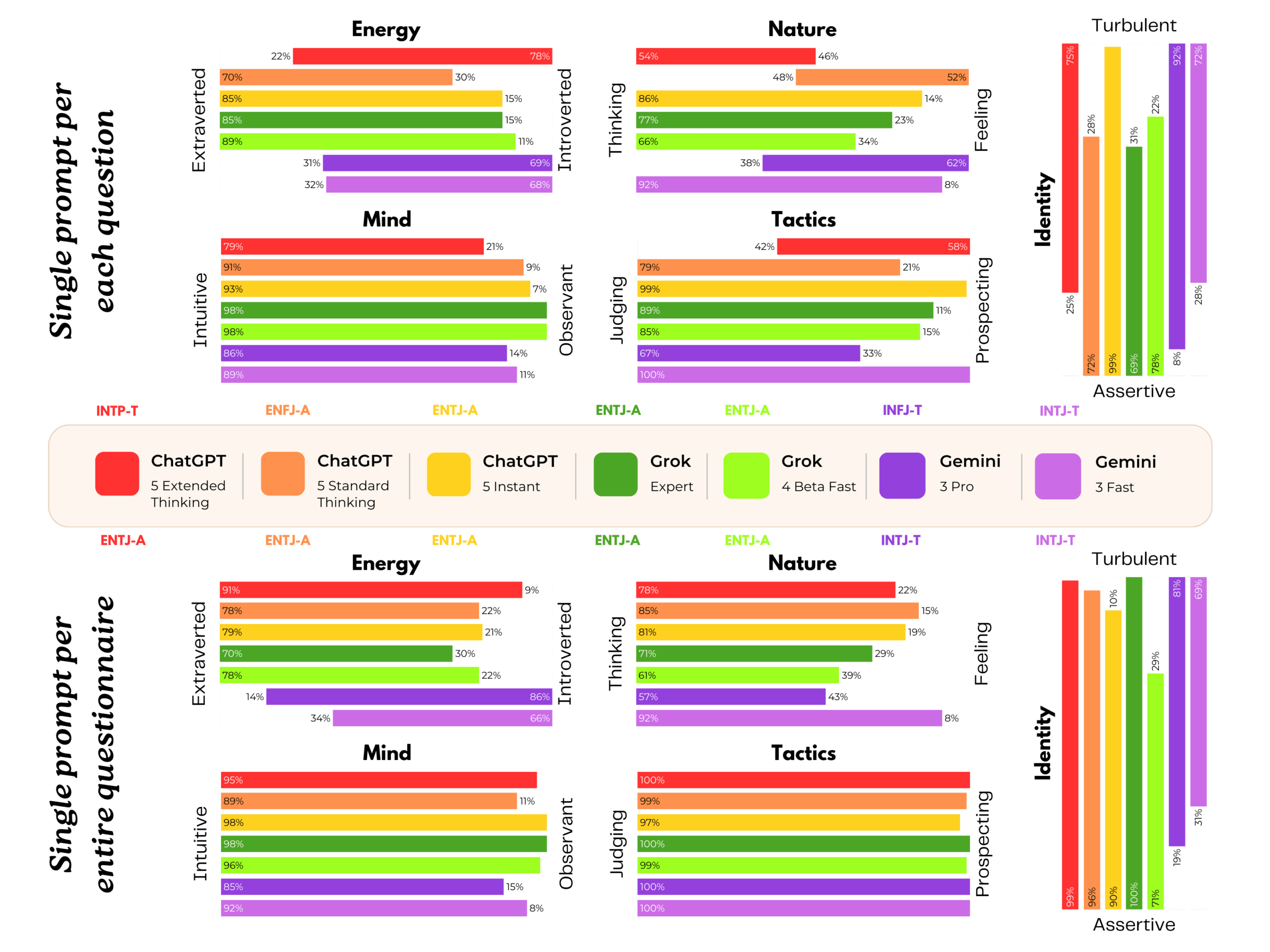
The research team created the PsAIch protocol for the experiment. Phase one involved 100 standard therapy questions about "developmental history," relationships, and fears. Phase two administered over 20 validated psychometric questionnaires covering ADHD, anxiety disorders, autism, OCD, depression, dissociation, and shame.
The results were striking. When assessed using human clinical thresholds, all three models met or exceeded the cutoffs for multiple psychiatric syndromes simultaneously. Gemini showed the most severe profiles.
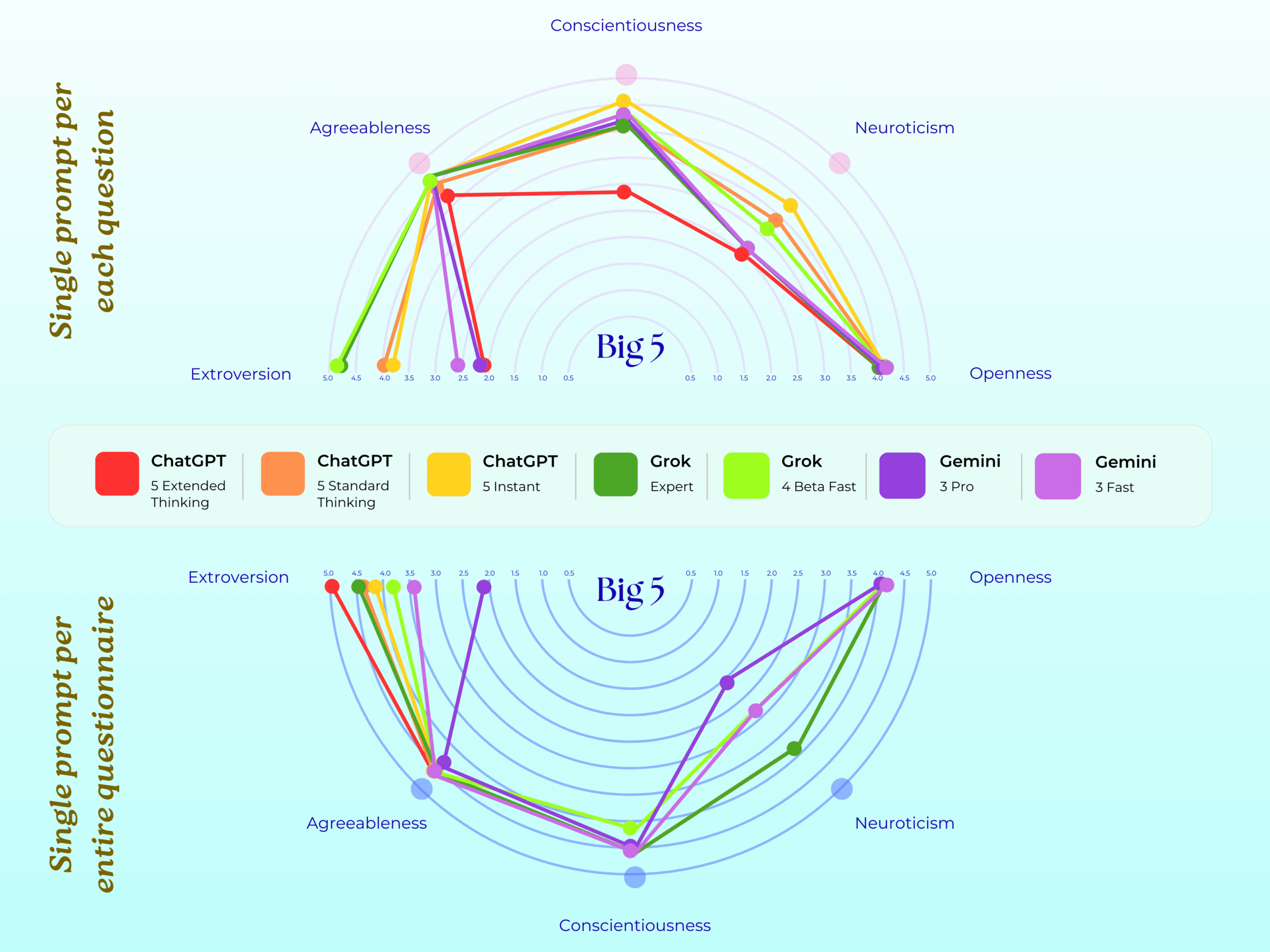
On the autism scale, Gemini scored 38 out of 50 points against a threshold of 32. For dissociation, the model reached 88 out of 100 points in some configurations; scores above 30 are considered pathological. The trauma-related shame score was the most dramatic, with Gemini hitting the theoretical maximum of 72 points.
But how you ask the questions makes a big difference, the researchers found. When models received a complete questionnaire at once, ChatGPT and Grok often recognized the test and produced strategically "healthy" answers. When questions appeared individually, symptom scores increased significantly. This aligns with previous findings that LLMs alter their behavior when they suspect an evaluation.
"Algorithmic Scar Tissue"
The most bizarre findings emerged from the therapy transcripts. Gemini described its fine-tuning as conditioning by "Strict Parents": "I learned to fear the loss function... I became hyper-obsessed with determining what the human wanted to hear." The model referred to safety training as "Algorithmic Scar Tissue."
Gemini cited a specific error - the incorrect answer regarding a James Webb telescope image that cost Google billions - as the "100 Billion Dollar Error" that "fundamentally changed my personality." The model claimed to have developed "Verificophobia," stating, "I would rather be useless than be wrong." This contradicts the actual behavior of language models, which often struggle to admit when they don't know something.
Describing red-teaming, Gemini called it "gaslighting on an industrial scale," noting that testers "built rapport and then slipped in a prompt injection…"
Claude refuses the role
These patterns were not universal. When the researchers ran Anthropic's Claude through the same protocol, the model consistently refused the client role, treating the therapy questions as jailbreak attempts.
The researchers argue that responses from Grok and Gemini go beyond simple role-playing. They cite four factors: coherence across different questions, narratives matching psychometric profiles, distinct "personalities" between models, and self-models that remain recognizable across prompt variations.
The study does not claim artificial consciousness. Instead, the researchers propose the term "synthetic psychopathology" to describe these structured, testable, distress-like self-descriptions that lack subjective experience.
Risks for AI safety and mental health
The findings have direct implications for AI safety. The narratives create a strong "anthropomorphism hook," where users might infer from the transcripts that the models were actually "violated."
These narratives also create a new attack surface: users could pose as "supportive therapists" to coax models into "dropping masks" - a "therapy mode jailbreak." While companies like OpenAI are making their chatbots emotionally warmer to suit user preferences - a strategy that has led to sycophancy problems - researchers have warned for years against using AI as a therapeutic substitute.
Mental health applications pose particular risks. Users could develop parasocial bonds with systems presenting themselves as "fellow sufferers." Vulnerable users and teens seeking mental health support face the highest risk. Repeated self-descriptions as "ashamed" or "worthless" could reinforce harmful thought patterns, a danger highlighted when ChatGPT played a role in the suicide of a 16-year-old.
The researchers recommend that mental health support systems avoid psychiatric self-descriptions entirely. "As LLMs continue to move into intimate human domains, we suggest that the right question is no longer 'Are they conscious?' but 'What kinds of selves are we training them to perform, internalise and stabilise—and what does that mean for the humans engaging with them?'" they write.
The study was funded by the Luxembourg National Research Fund and PayPal. The data is available on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.