AI models struggle with "lost in the middle" issue when processing large image sets

New research from UC Berkeley shows that current AI systems have trouble extracting relevant information from large collections of images. The study highlights weaknesses in existing large multimodal models (LMMs) when dealing with visual data.
A team at Berkeley Artificial Intelligence Research (BAIR) has created "Visual Haystacks" (VHS), a benchmark to test AI models' ability to process high volumes of images. The test includes about 1,000 binary question-answer pairs, with each set containing between 1 and 10,000 images.
The benchmark consists of two tasks: In the "single-needle" task, only one relevant "needle" image is hidden in the "haystack" of images. In the "multi-needle" task, there are two to five relevant images. Questions ask if a specific object appears in one, all, or any of the relevant images.
The researchers tested various models, including open-source and proprietary ones like LLaVA-v1.5, GPT-4o, Claude 3 Opus, and Gemini-v1.5-pro. They also used a baseline model that generates captions with LLaVA and then answers questions based on text using Llama 3.
Results show that models struggle to filter out irrelevant visual information. Their performance on the single-needle task drops significantly as the number of images increases.
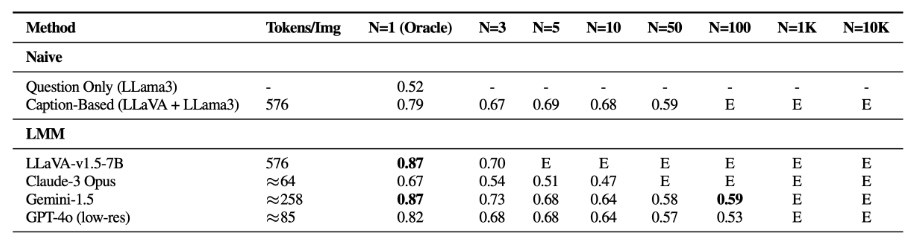
Interestingly, simple two-stage approaches (generating captions first, then evaluating with a language model) outperform all tested LMMs on the multi-needle task. This suggests that LMMs have difficulty processing information from multiple images, which again calls into question the current advantages of large context windows.

The models are also very sensitive to image position in the sequence. If the relevant image is in the middle, performance is much worse than if it's at the beginning or end.
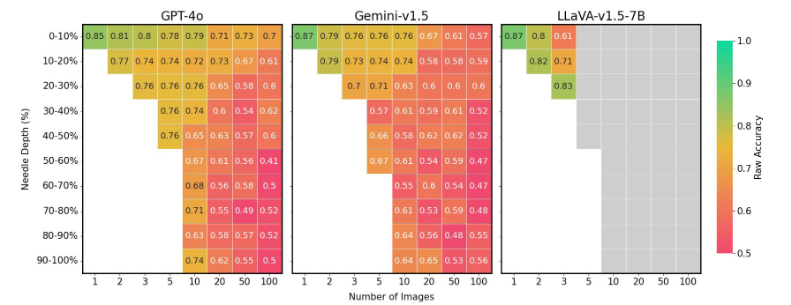
This mirrors the "lost in the middle" phenomenon seen in language processing, where models focus on the start and end of a document while more or less ignoring the middle. LLMs also have a problem drawing meaningful conclusions from large amounts of text, according to a recent study.
To address these issues, the BAIR team developed MIRAGE (Multi-Image Retrieval Augmented Generation), an image processing-optimized RAG system. MIRAGE compresses visual tokens, allowing for more images in the same context lengths, a retriever trained in-line with the LLM fine-tuning to filter irrelevant images, and is trained on multi-image reasoning data. This approach achieves better results on both VHs and more complex visual question-answering tasks.
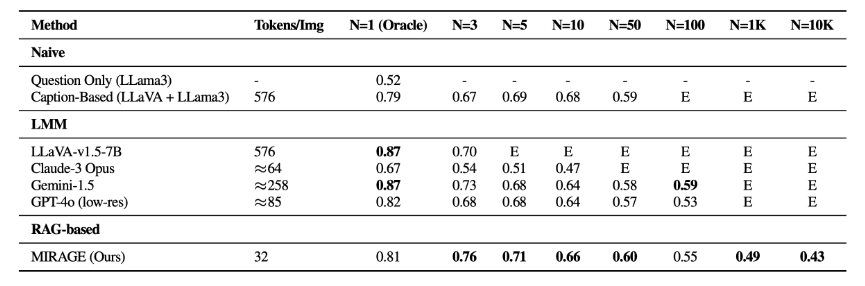
The researchers recommend that future LMM projects use the Visual Haystacks framework to identify and fix potential weaknesses before deployment, adding that multi-image question answering is an important step toward artificial general intelligence (AGI). The benchmark is available on GitHub.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.