AI text floods one of the most important human data sources

Is human data really human? One study comes to a different conclusion. Almost half of the supposedly human text summaries came from an AI.
A recent study by the École Polytechnique Fédérale de Lausanne (EPFL) examined the role of AI tools such as ChatGPT, which are based on large language models, in work that appears to be performed by humans.
The study focused on Amazon's Mechanical Turk (MTurk) crowdsourcing platform, where users can offer and perform tasks such as text summarization.
Nearly half of the summaries came from AI
The researchers found that between 33 and 46 percent of the summaries submitted in the study were created using AI language models. The crowd workers were asked to summarize medical texts of around 400 words. The researchers' instructions actually read like a prompt for a text AI:
You will be given a short text (around 400 words) with medicine-related information. Your task is to:
- Read the text carefully.
- Write a summary of the text. Your summary should:
- Convey the most important information in the text, as if you are trying to inform another person
about what you just read.- Contain at least 100 words.
We expect high-quality summaries and will manually inspect some of them.
The results of the study raise serious questions about the authenticity of human data. The researchers used a combination of keystroke recognition and synthetic text classification to detect the use of AI language models.
Proprietary recognition model trained with high accuracy
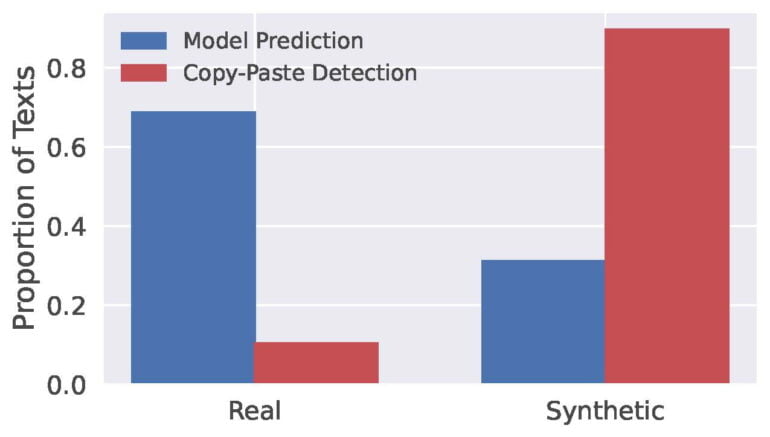
AI text detectors such as GPTZero did not provide reliable results. Out of ten AI-generated summaries, GPTZero only recognized six as such. Instead, the researchers trained their own model using both human-written and AI-generated summaries. According to the researchers, this model achieved up to 99 percent accuracy in correctly recognizing AI text.
"These high scores indicate that—at least for the task at hand—there exists an identifiable ChatGPT fingerprint in abstract summarization tasks that make it learn universal features to discriminate between real and synthetic texts," the paper states.
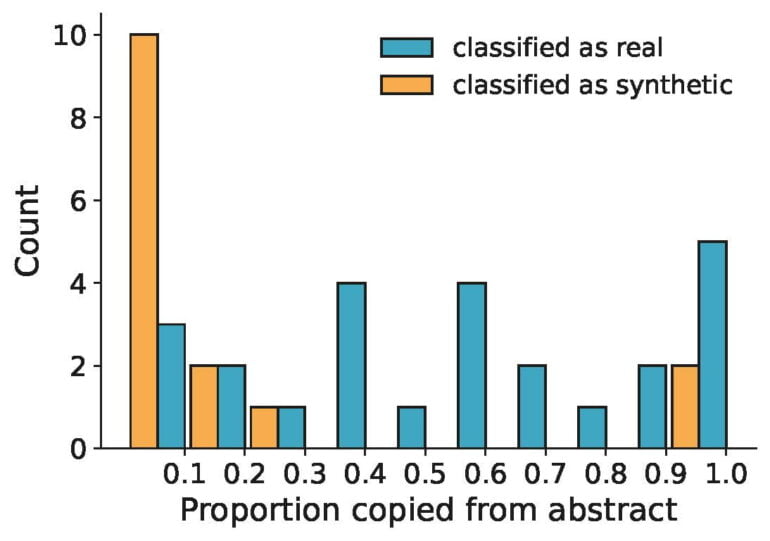
The AI-generated texts often bore little resemblance to the original abstracts, suggesting that the AI models were generating new texts rather than copying and pasting parts of the original abstracts.
How much is human labor still worth?
According to the Swiss researchers, these findings have far-reaching implications. They underline the growing trend of human involvement in text creation decreasing and being replaced by AI. This could have a negative impact on the quality and diversity of data available on crowdsourcing platforms, as human data is considered the gold standard.
"All this being said, we do not believe that this will signify the end of crowd work, but it may lead to a radical shift in the value provided by crowd workers," the researchers said. Instead, crowd workers could act as an important human filter to identify when these models succeed and when they fail. Even though AI appears to be partially replacing human labor, it remains an important part of training language models.
Framework for reliable AI text recognition
In addition to insights into the prevalence of AI for these tasks, the researchers have developed what appears to be a robust framework for reliably recognizing AI text in specific use cases. However, they also note that the (unannounced) monitoring of keystrokes in this method would not be entirely uncritical from an ethical point of view, and would therefore tend to be inapplicable on a larger scale.
In addition, the use of AI by crowd workers could raise privacy issues. For example, when using ChatGPT, crowd workers would need to explicitly prohibit the use of their work for further AI training, as OpenAI guidelines prohibit the use of model output to train competing products. So if AI is used by crowd workers without the knowledge of clients, there could be legal consequences.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.