
Emergent abilities in large language models have generated both excitement and concern. Now, Stanford researchers suggest that these abilities may be more of a metric-induced mirage than a real phenomenon.
The sudden emergence of new abilities while scaling large language models is a fascinating topic and a reason for and against further scaling of these models: OpenAI's GPT-3 was able to solve simple mathematical tasks above a certain number of parameters, and a Google researcher counted no less than 137 emergent abilities in NLP benchmarks like BIG-Bench.
In general, emergent abilities (or capabilities) refer to those that suddenly manifest in models above a specific size, but are absent in smaller models. The appearance of such instantaneous and unpredictable leaps has spurred extensive research into the origins of these abilities and, more crucially, their predictability. This is because, within the realm of AI alignment research, the unforeseen emergence of AI abilities is considered a cautionary indicator that highly-scaled AI networks may unexpectedly develop unwanted or even dangerous abilities without any warning.
Now, in a new research paper, researchers at Stanford University show that while models like GPT-3 develop rudimentary mathematical skills, they cease to be emergent abilities once you change the way you measure them.
Emergent abilities are a result of a particular metric
"We call into question the claim that LLMs possess emergent abilities, by which we specifically mean sharp and unpredictable changes in model outputs as a function of model scale on specific tasks."
Typically, the ability of a large language model is measured in terms of accuracy, which is the proportion of correct predictions out of the total number of predictions. This metric is nonlinear, which is why changes in accuracy are seen as jumps, the team said.
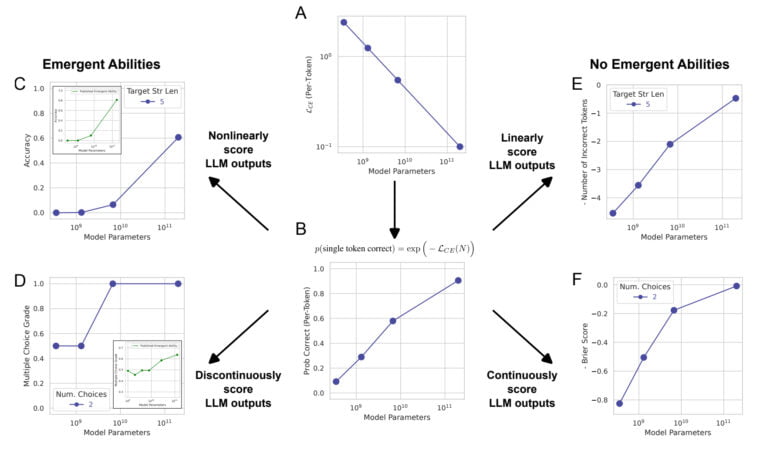
"Our alternative explanation posits that emergent abilities are a mirage caused primarily by the researcher choosing a metric that nonlinearly or discontinuously deforms per-token error rates, and partially by possessing too few test data to accurately estimate the performance of smaller models (thereby causing smaller models to appear wholly unable to perform the task) and partially by evaluating too few large-scale models," the paper states.
Using a linear metric such as token edit distance, a metric that calculates the minimum number of single-token edits required to transform one sequence of tokens into another, there is no longer a visible jump - instead, a smooth, continuous, and predictable improvement is observed as the number of parameters increases.
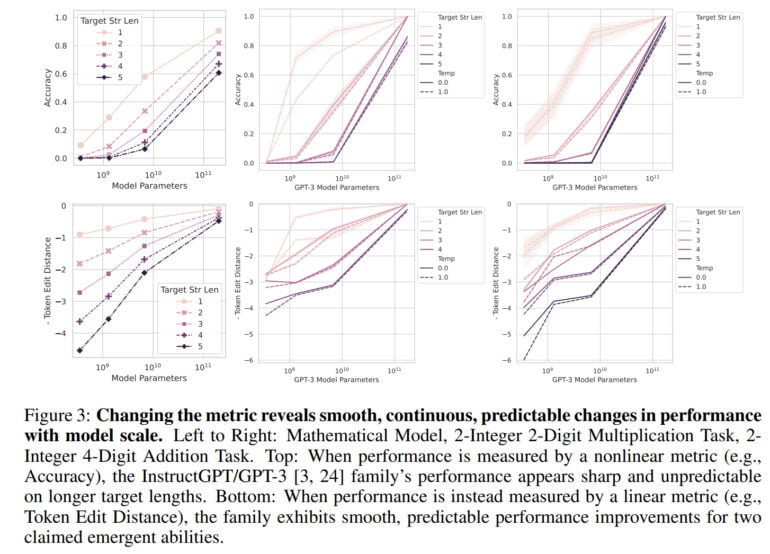
In their work, the team shows that the emergent abilites of GPT-3 and other models are due to such nonlinear metrics and that no drastic jumps are apparent in a linear metric. In addition, the researchers reproduce this effect with computer vision models, in which emergence has not been measured before.
Emergent abilities are "probably a mirage"
"The main takeaway is for a fixed task and a fixed model family, the researcher can choose a metric to create an emergent ability or choose a metric to ablate an emergent ability," the team said. "Ergo, emergent abilities may be creations of the researcher’s choices, not a fundamental property of the model family on the specific task."

However, the team stresses that this work should not be interpreted to mean that large language models like GPT-4 cannot have emergent abilities. "Rather, our message is that previously claimed emergent abilities might likely be a mirage induced by researcher analyses."
For alignment research, this work could be good news, as it seems to demonstrate the predictability of abilities in large language models. OpenAI has also shown in a report on GPT-4 that it can accurately predict GPT-4 performance in many benchmarks.
However, since the team does not rule out the possibility of emergent abilities per se, the question is whether such abilities already exist. One candidate might be "few-shot learning" or "in-context learning," which the team does not explore in this work. This ability was first demonstrated in detail in GPT-3 and is the basis for today's prompt engineering.




