Alibaba unveils Qwen3-Omni, an AI model that processes text, images, audio, and video

Alibaba has introduced Qwen3-Omni, a native multimodal AI model designed to process text, images, audio, and video in real time.
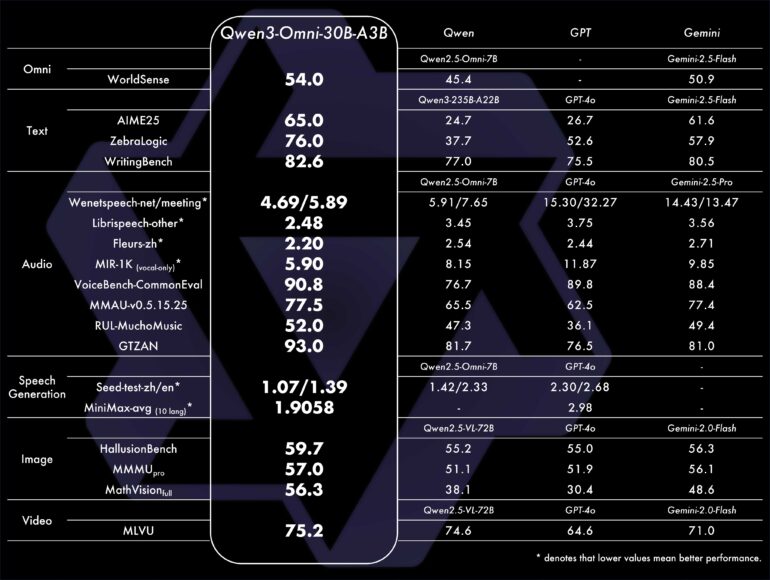
According to Alibaba, Qwen3-Omni ranks at the top on 32 out of 36 audio and video benchmarks, outperforming established models like Gemini 2.5 Flash and GPT-4o in tasks such as speech comprehension and voice generation. In specialized areas, its performance matches models built for a single input type.
While Alibaba hasn't released a technical report, blog posts and benchmark results offer some details. The 30-billion-parameter model uses a mixture-of-experts architecture, activating three billion parameters per inference. Qwen3-Omni processes audio input in 211 milliseconds and combined audio and video in 507 milliseconds.
Given its relatively compact architecture, it's impressive that Qwen3-Omni can keep up with leading commercial models in Alibaba's chosen benchmarks. That said, it's still an open question whether it can consistently match the performance of models like GPT-4o or Gemini 2.5 Flash in everyday use, since smaller models often struggle outside of controlled tests.
Two-part architecture for real-time processing
Qwen3-Omni uses a two-part system: the "Thinker" analyzes input and generates text, while the "Talker" turns this output directly into speech. Both components work in parallel to minimize lag.
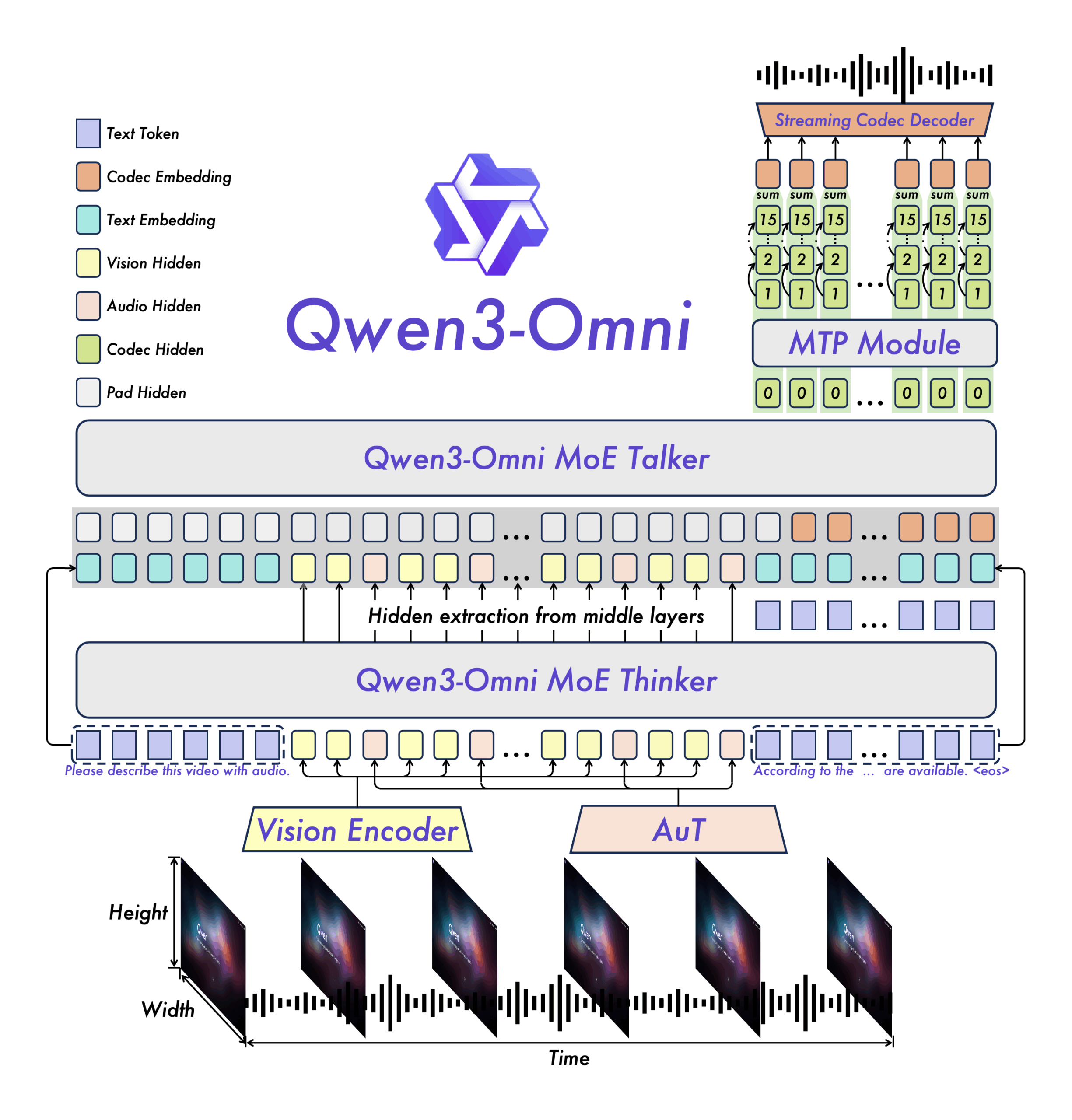
For real-time output, Qwen3-Omni generates audio step by step instead of creating whole audio files at once. Each processing step is converted immediately into audible speech, allowing for seamless streaming. The audio encoder was trained on 20 million hours of audio. Both main components use multiple specialized subsystems running in parallel, enabling high throughput and fast response.
Broad language support
The model processes text in 119 languages, understands spoken language in 19, and can respond in 10. It can analyze and summarize up to 30 minutes of audio.
Alibaba says the model is trained to perform equally well across all its supported input types. The company claims there are no trade-offs in any one area, even when handling multiple modalities at once.
Users can tweak the model's behavior through special instructions, such as altering response style or personality. Qwen3-Omni can also connect to external tools and services for more complex tasks.
Dedicated model for audio descriptions
Alibaba is also releasing Qwen3-Omni-30B-A3B-Captioner, a separate model built for detailed analysis of audio content like music. The aim is to generate accurate, low-error descriptions and address a gap in the open-source ecosystem.

Alibaba says it plans to improve multi-speaker recognition, add text recognition for video, and boost learning from audio-video combinations. The company is also working on expanding autonomous agent capabilities.
Qwen3-Omni is available through Qwen Chat and as a demo on Hugging Face. Developers can plug the model into their own apps using Alibaba's API platform.
There are also two open source versions: Qwen3-Omni-30B-A3B-Instruct for instruction following, and Qwen3-Omni-30B-A3B-Thinking for complex reasoning.
Alibaba's YouTube demo shows Qwen3-Omni translating a restaurant menu in real time using a wearable. The release follows the launch of the Quark AI Glasses and rising popularity of Alibaba's Quark chatbot in Chinese app stores. With an English-language ad, Alibaba is clearly looking beyond China and targeting users in Western markets.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.