Alibaba's new Qwen-Image model generates high-fidelity text inside images

Alibaba has introduced Qwen-Image, a 20-billion-parameter AI model designed for high-fidelity text rendering inside images.
According to the developers, Qwen-Image can handle a wide range of visual styles, from anime scenes with multiple storefront signs to intricate PowerPoint slides packed with structured content. The model also supports bilingual text and can switch smoothly between languages.


Beyond image generation, Qwen-Image brings a suite of editing tools. Users can change visual styles, add or remove objects, and adjust the poses of people within images. The model also covers classic computer vision tasks like estimating image depth or generating new perspectives.

According to the technical report, the model's architecture is built from three parts: Qwen2.5-VL handles text-image understanding, a Variational AutoEncoder compresses images for efficiency, and a Multimodal Diffusion Transformer produces the final outputs.
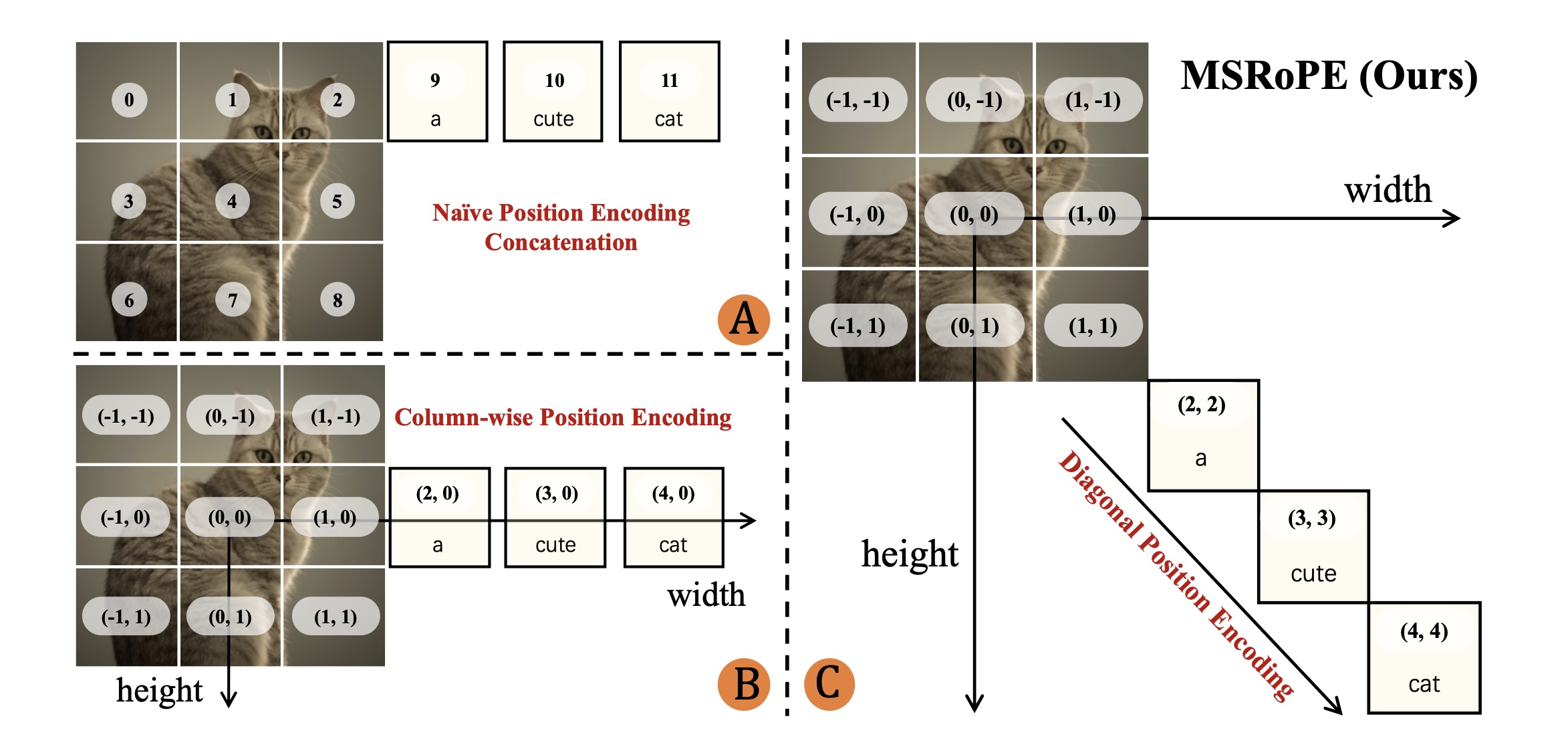
A new approach called MSRoPE (Multimodal Scalable RoPE) improves how the model positions text within images. MSRoPE is a technique for encoding spatial relationships in multimodal models. Unlike traditional methods that treat text as a simple sequence, MSRoPE arranges text elements spatially along a diagonal inside the image. This allows the model to more accurately place text at different image resolutions and improves alignment between text and image content.
Training data excludes AI-generated content
The Qwen team says the model's training data falls into four main categories: nature images (55 percent), design content like posters and slides (27 percent), people (13 percent), and synthetic data (5 percent). The training pipeline specifically avoids AI-generated images, focusing on text created through controlled processes.
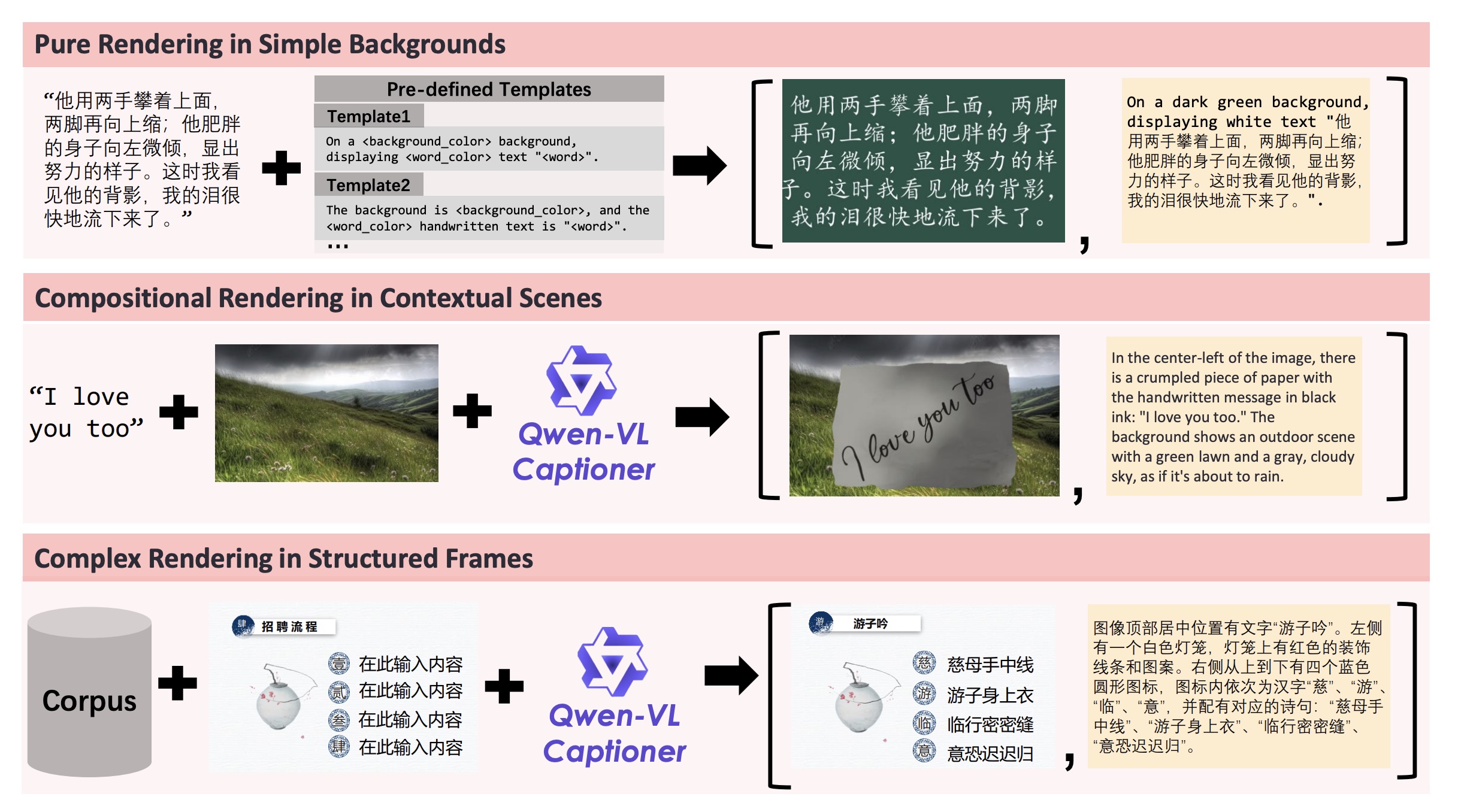
A multi-stage filtering process removes low-quality content. Three strategies round out the training data: Pure Rendering (simple text on backgrounds), Compositional Rendering (text in realistic scenes), and Complex Rendering (structured layouts like slides).
Beating commercial models in key areas
For evaluation, the team built an arena platform where users anonymously rated images from different models. After more than 10,000 comparisons, Qwen-Image ranked third, outperforming commercial models like GPT-Image-1 and Flux.1 Context.
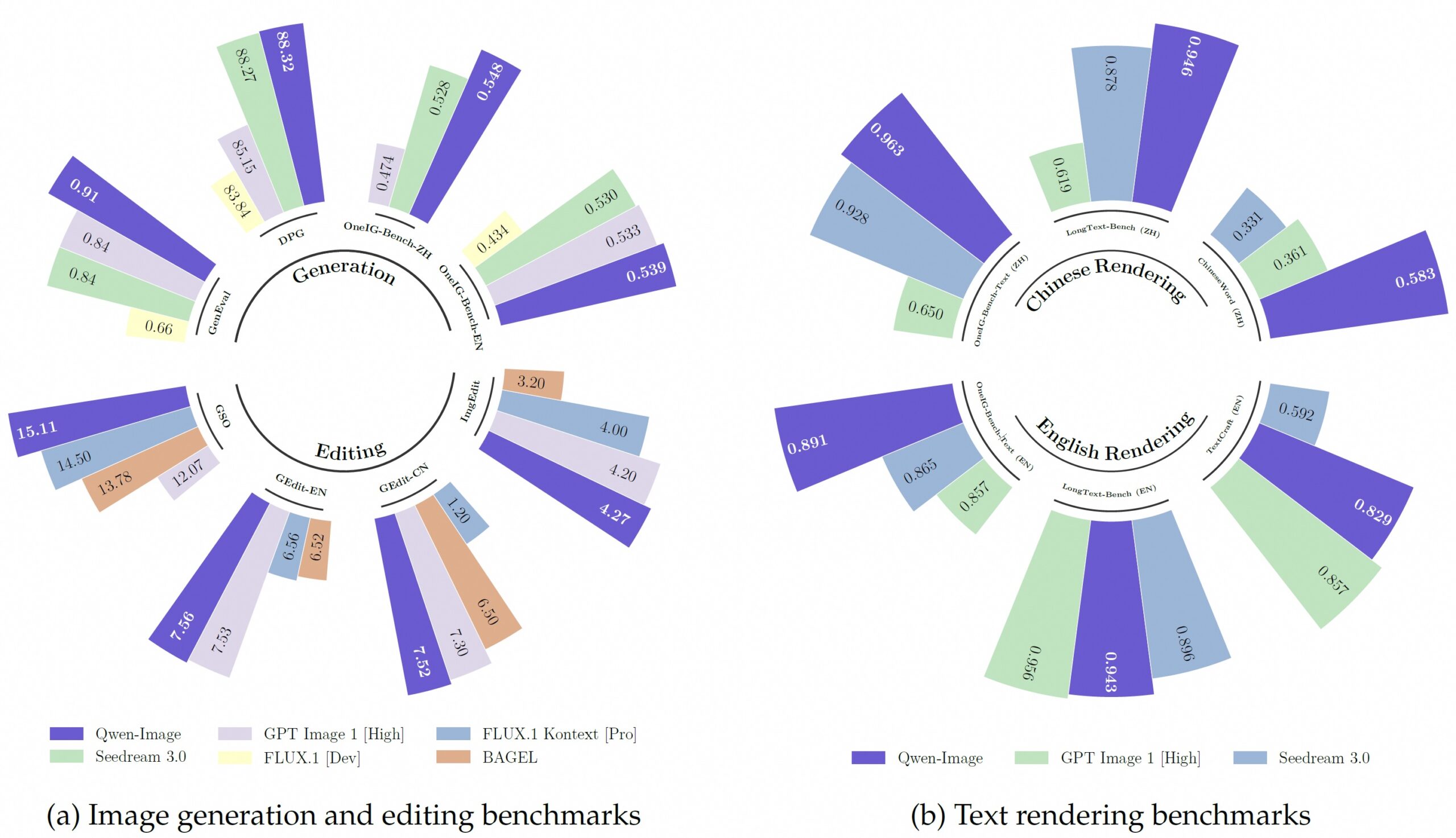
Benchmark results back up these findings. In the GenEval test for object generation, Qwen-Image scored 0.91 after additional training, ahead of all other models. The model also holds a clear edge in rendering Chinese characters.
The researchers see Qwen-Image as a step toward "vision-language user interfaces" that tightly integrate text and image. Looking ahead, Alibaba is working on unified platforms for both image understanding and generation. The company recently unveiled Qwen VLo, another model known for its strong text capabilities.
Qwen-Image is available for free on GitHub and Hugging Face, with a live demo for testing.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.