Alibaba's Qwen3-Next builds on a faster MoE architecture

Update –
- Added FP8 releases
Update from September 23, 2025:
Alibaba has added two new models to its Qwen3-Next line, both built around FP8 precision. The Qwen3-Next-80B-A3B-Instruct-FP8 and Qwen3-Next-80B-A3B-Thinking-FP8 use the FP8 (8-bit floating point) format, which is designed to boost processing speed. Both models work out of the box with frameworks like Transformers, vLLM, and SGLang.
These FP8 models are aimed at situations where speed really matters, like running AI services in real time. Compared to standard formats like FP16 or INT8, FP8 offers a stronger balance between raw performance and energy use, with just a small tradeoff in response accuracy.
Both versions are already available on Hugging Face and ModelScope. The Instruct model is geared toward general chatbot and assistant tasks, while the Thinking model is tuned for more complex, logic-heavy jobs.
Original article from September 14, 2025:
Alibaba has released a new language model called Qwen3-Next, built on a customized MoE architecture. The company says the model runs much faster than its predecessors without losing performance.
The earlier Qwen3 model used 128 experts, activating 8 at each inference step. Qwen3-Next expands that layer to 512 experts but only activates 10 of them plus a shared expert. According to Alibaba, this setup delivers more than 10 times the speed of Qwen3-32B, especially with long inputs over 32,000 tokens.
The architecture also includes several tweaks to stabilize training. These help avoid issues like uneven expert use, numerical instability, or initialization errors. Among them are normalized initialization for router parameters and output gating in attention layers.
In addition to the base model, Alibaba introduced two specialized versions: Qwen3-Next-80B-A3B-Instruct for general-purpose tasks and Qwen3-Next-80B-A3B-Thinking for reasoning-heavy problems. The company says the smaller Instruct model performs nearly on par with its flagship Qwen3-235B-A22B-Instruct, particularly with long contexts up to 256,000 tokens. The Thinking model reportedly beats Google's closed Gemini 2.5 Flash Thinking on several benchmarks and comes close to Alibaba's own top-tier Qwen3-235B-A22B-Thinking in key metrics.
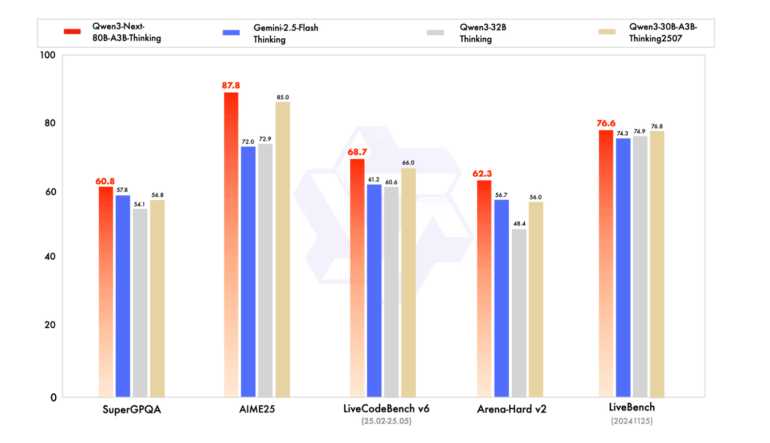
The models are available on Hugging Face, ModelScope, and the Nvidia API Catalog. For running them on private servers, the team recommends specialized frameworks like sglang or vllm. Current context windows go up to 256,000 tokens, and with specialized techniques, as high as one million.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.