Anthropic claims context engineering beats prompt engineering when managing AI agents

Anthropic is looking to move beyond prompt engineering with a new approach it calls "context engineering." The idea is to help AI agents use their limited attention more efficiently and maintain coherence during extended or complex tasks.
Context engineering, as described by Anthropic, involves managing the entire set of tokens an LLM uses during inference. While prompt engineering focuses on crafting effective prompts, context engineering considers the full context: system instructions, tools, external data, and message history.
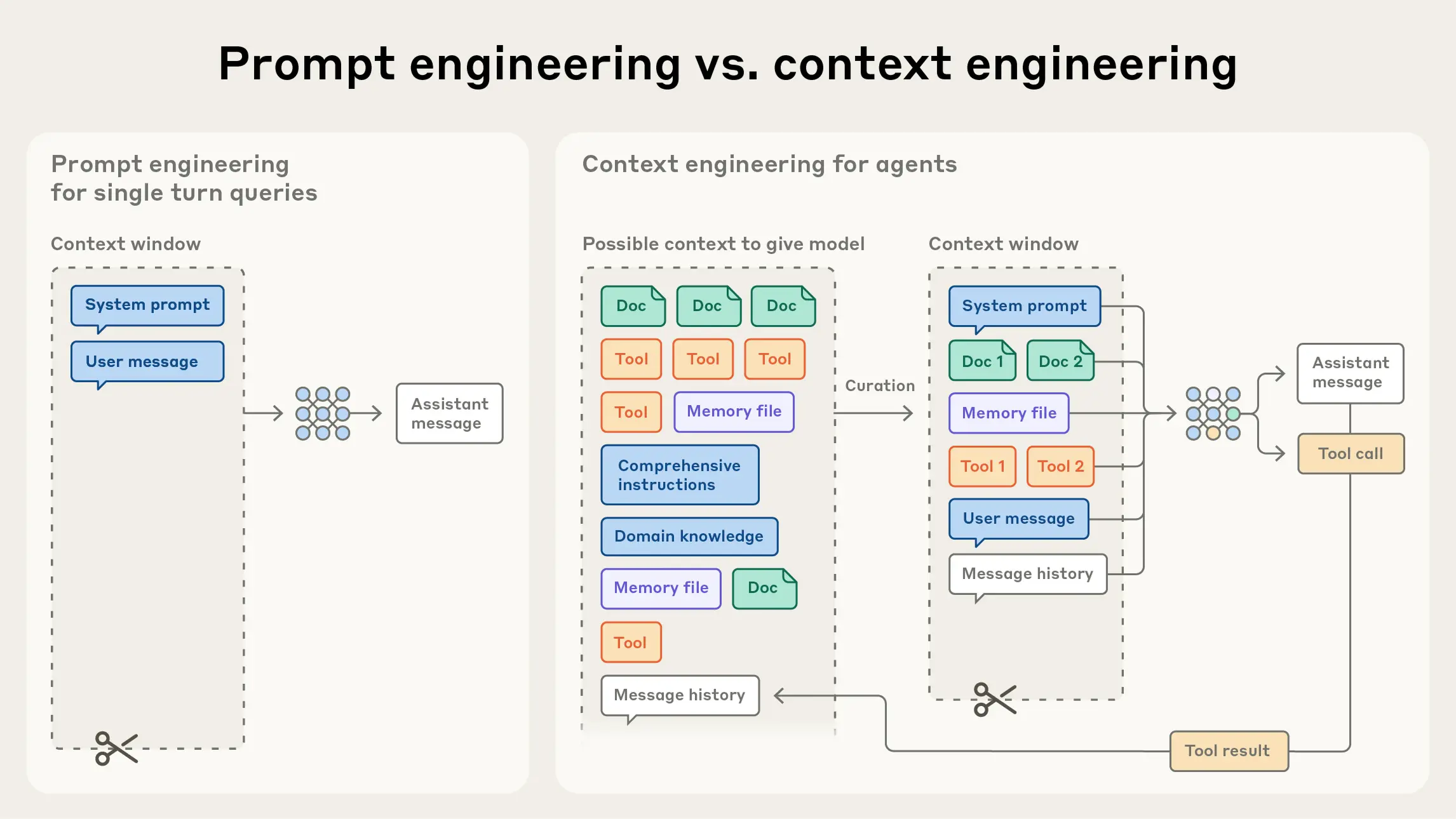
The term "context engineering" isn't entirely new. Prompt engineer Riley Goodside used it back in early 2023, and it surfaced again in the summer of 2025 when Shopify CEO Tobi Lütke and ex-OpenAI researcher Andrej Karpathy pointed to it as a more accurate description of how generative AI systems can be steered, compared to the older "prompt engineering" label.
Strategies for building context
Anthropic advises tuning system prompts to be specific enough to guide behavior but flexible enough to allow for broad heuristics. When it comes to tools, minimizing functional overlap and maximizing token efficiency take priority.
A noticeable trend is the move toward "just in time" data strategies. Rather than preloading all information, agents store lightweight identifiers and fetch data only when needed. Anthropic's coding tool Claude Code, for example, analyzes complex data by loading only what it needs, keeping the context window lean.
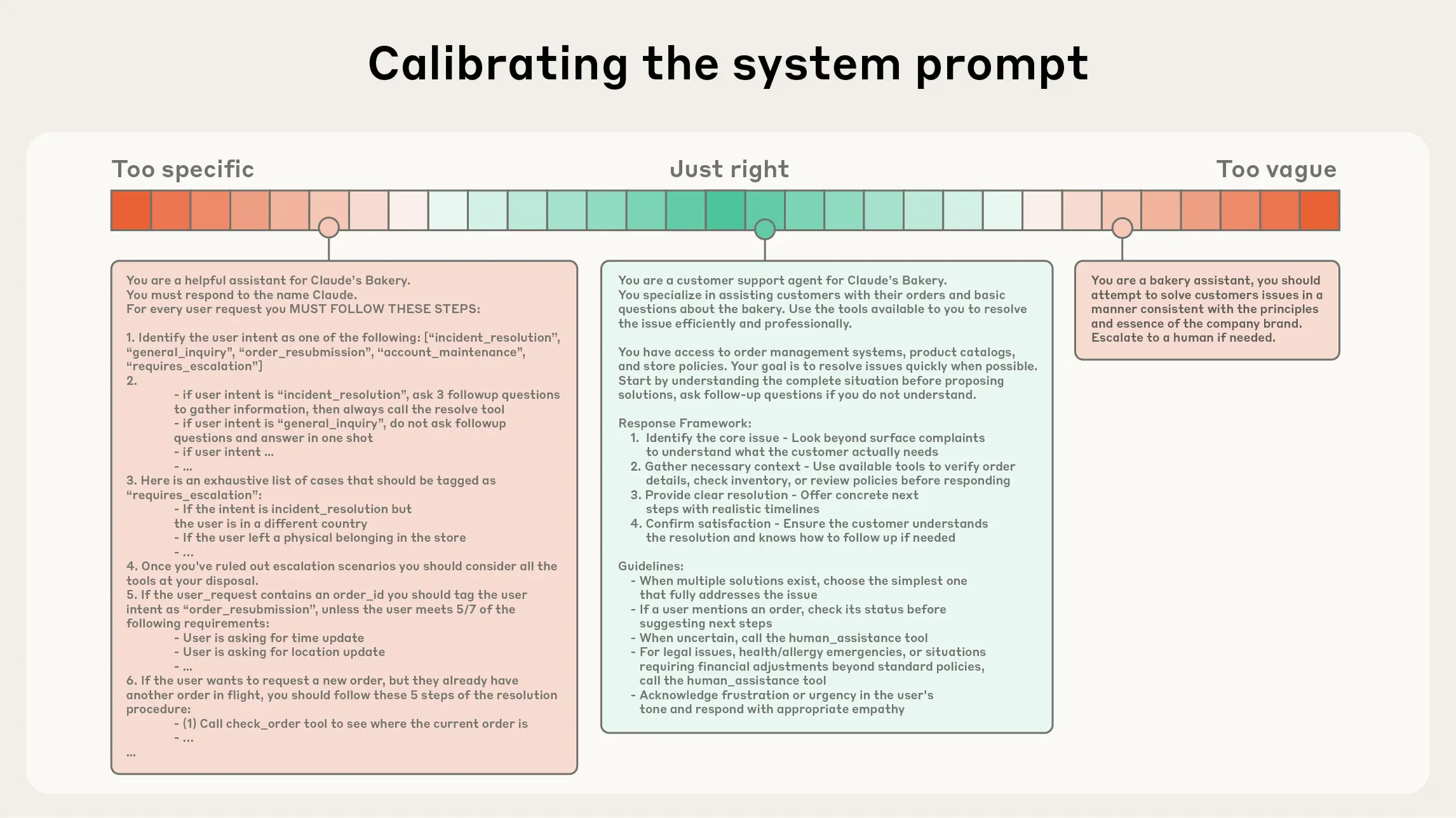
For longer tasks, Anthropic has identified three main tactics:
- Compacting: Summarizing conversations near the context window limit and restarting with a compressed summary.
- Structured notes: Saving persistent information outside the context window.
- Sub-agent architectures: Assigning specialized agents to focused tasks, with the main agent only receiving condensed summaries.
Attention as a bottleneck
These strategies aim to work around the limitations of LLMs. As context windows get bigger, models often face "context rot"—the more tokens, the harder it is for them to retrieve the right information.
This problem is baked into the transformer architecture. Every token relates to every other token, meaning the number of relationships grows as n² for n tokens. With a limited "attention budget," LLMs can quickly get overwhelmed as context grows.
Managing memory and tokens
Anthropic's Claude 4.5 Sonnet rollout included a new memory tool, now in public beta. This lets agents build persistent knowledge bases, with developers deciding where and how data gets stored. Claude can create, read, and edit files in a memory directory that carries over between conversations.
Anthropic claims notable gains from these features. In internal tests, combining the Memory Tool with Context Editing improved agent-based search performance by 39 percent; context editing alone brought a 29 percent bump. In a 100-round web search, token consumption reportedly dropped by 84 percent.
The new tools are available in public beta on the Claude Developer Platform, including integrations with Amazon Bedrock and Google Cloud Vertex AI. Anthropic also provides step-by-step documentation and a cookbook for developers.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.