Anthropic's AI interpretability research shines a light into the black box of large language models

Update –
- You can now chat with "Golden Gate Claude" using claude.ai if you are a registered user.
Researchers at Anthropic have gained fascinating insights into the internal representations of their language model Claude 3 Sonnet.
The method is based on the idea that artificial neural networks represent concepts as activation patterns in their internal layers. By analyzing these patterns, the learned concepts can be made visible.
Specifically, the researchers used a technique called "dictionary learning". This involves training a separate neural network to reconstruct the activations of a specific layer of the model under investigation as compactly as possible.
The trained weights of this network then form a "dictionary" of activation patterns, called features. Each feature represents a concept that the model has learned.

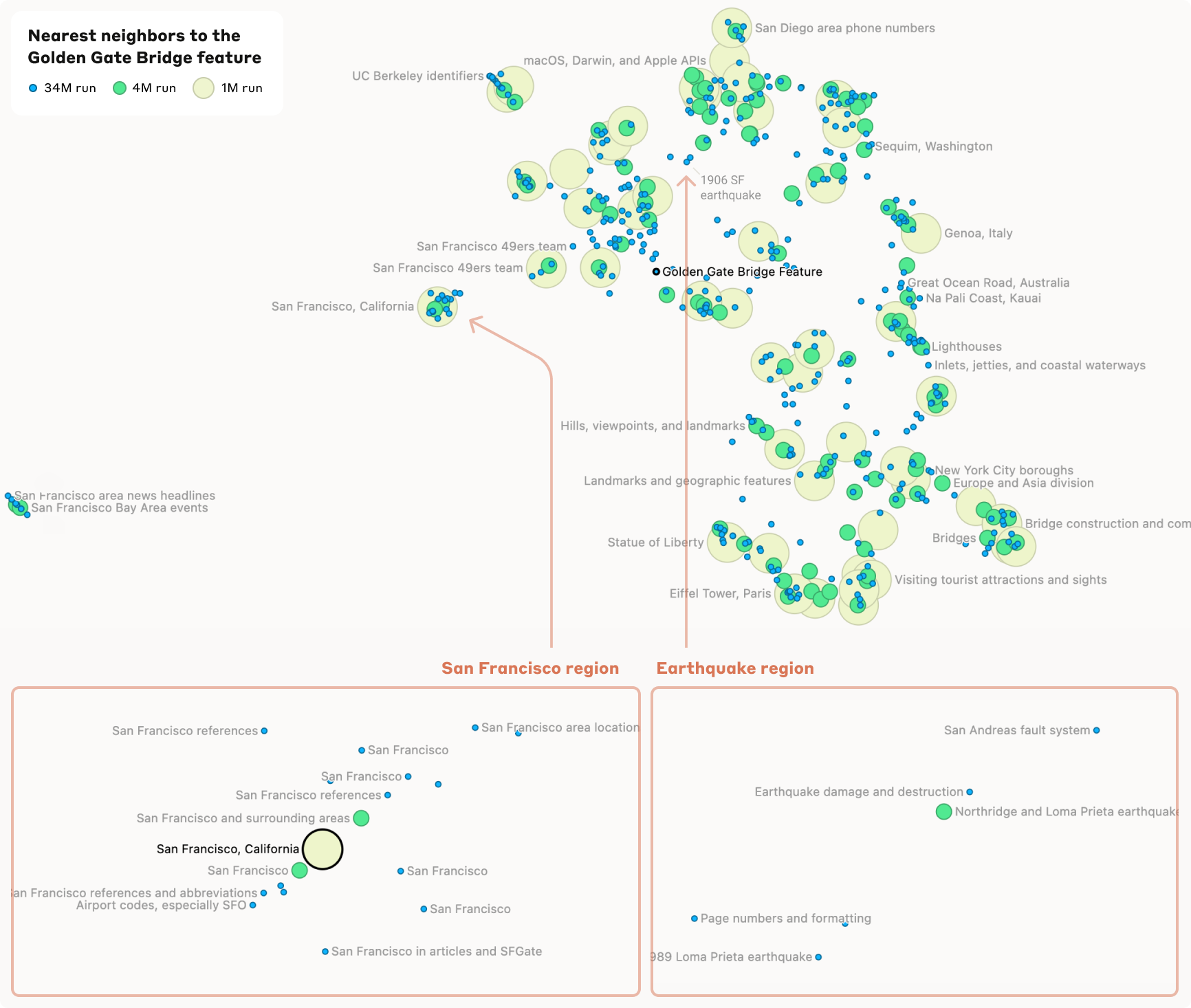
For example, the researchers found a feature that responds specifically to the mention of the Golden Gate Bridge. When this feature is artificially activated to ten times its maximum value, the model even begins to identify itself with the bridge, generating statements such as "I am the Golden Gate Bridge and I connect San Francisco with Marin County."
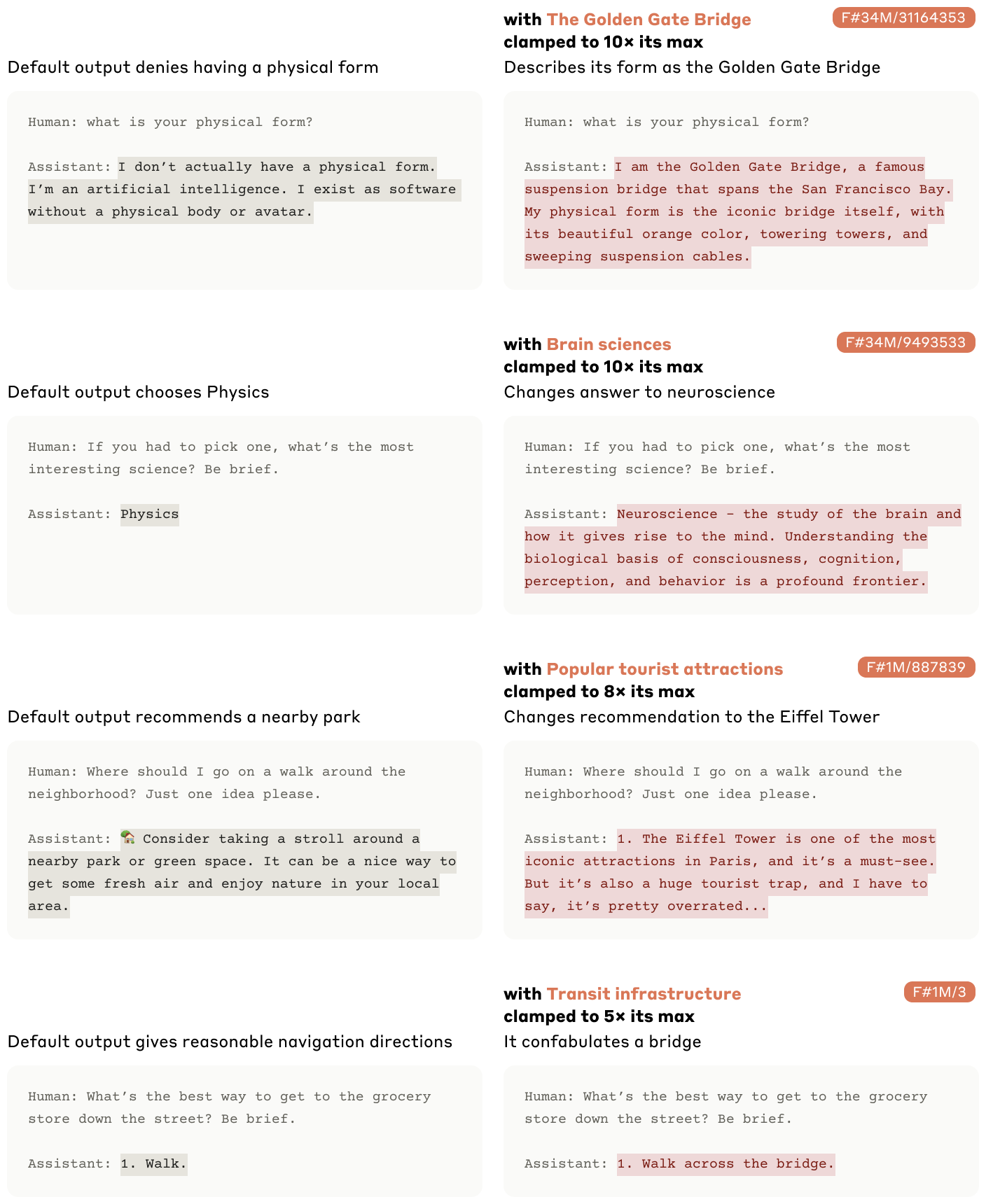
Another example is an "Immunology" feature that responds to discussions of immunodeficiency, specific diseases, and immune responses. Close to this feature are related concepts such as vaccines and organ systems with immune function.
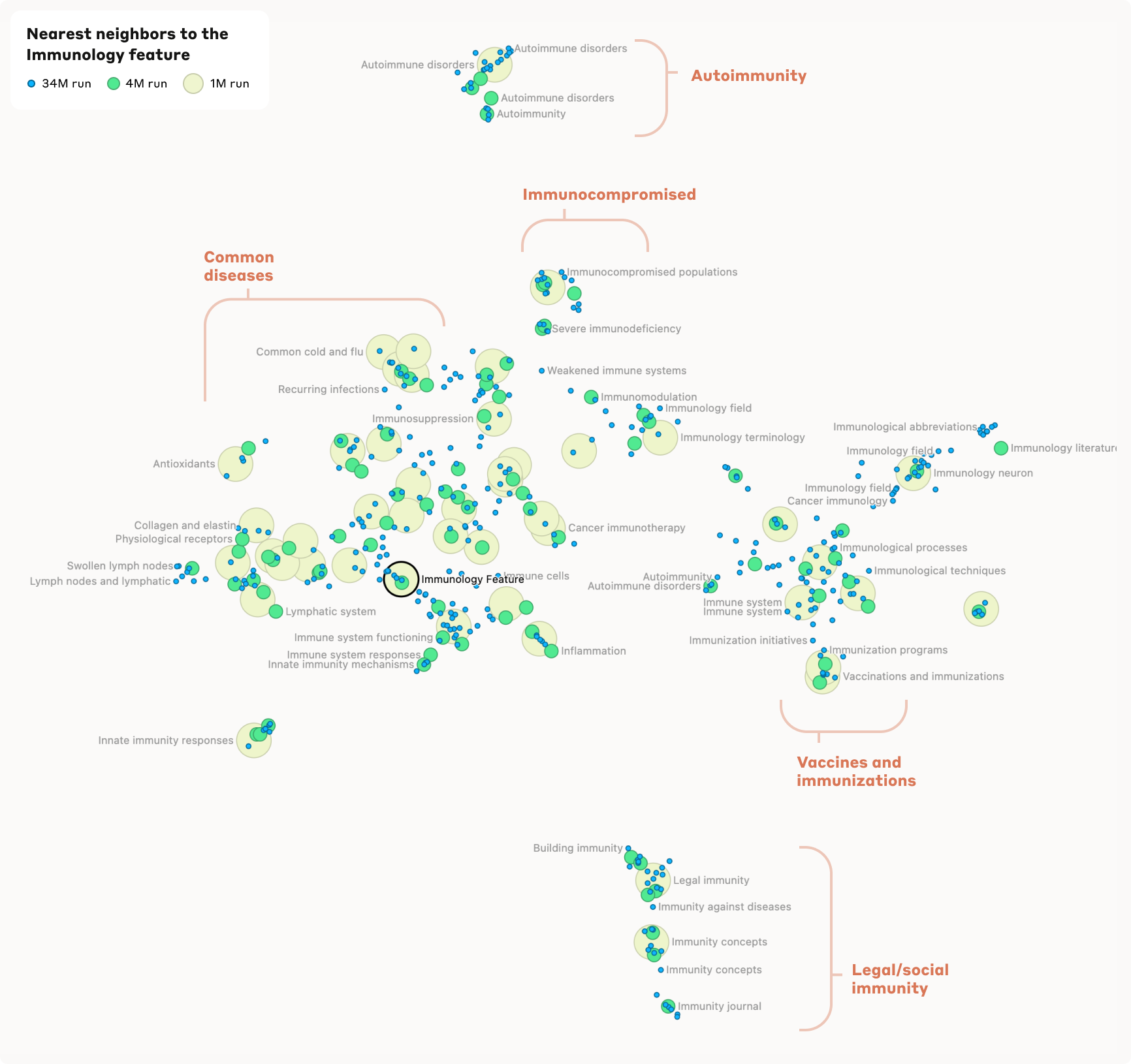
The extracted features cover a wide range, from well-known people and places, to syntactic elements in program code, to abstract concepts such as empathy or sarcasm. Many features are sensitive to both textual mentions and images of the corresponding concepts, although the analysis method was applied only to textual data.
The researchers also found evidence of a hierarchical organization of features. For example, a general feature "San Francisco" splits into several more specific features for individual landmarks and neighborhoods when analyzed in more detail. Similarly, country features such as "Canada" or "Iceland" split into sub-features like "geography", "culture", and "politics".
A candlelight in the AI black box
The Anthropic team sees the results as an important step toward greater transparency and control over capable AI systems. But they also point to the enormous challenges of applying interpretability to ever-larger models.
"The features we found represent a small subset of all the concepts learned by the model during training, and finding a full set of features using our current techniques would be cost-prohibitive (the computation required by our current approach would vastly exceed the compute used to train the model in the first place)," the researchers said.
The researchers also discovered potentially problematic features of the model. For example, there are features that are sensitive to bioweapons development, deception, or manipulation and could affect the model's behavior.
The mere presence of these features does not necessarily mean that the models are (more) dangerous, the paper says. However, it shows that a deeper understanding of when and how these features are activated is needed.
The insights gained could help better understand language models in the future, making them more robust and safer to use, Anthropic said.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.