Anthropic's Claude Opus 4.5 can tackle some tasks lasting nearly five hours
AI research organization METR has released new benchmark results for Claude Opus 4.5. Anthropic's latest model achieved a 50 percent time horizon of roughly 4 hours and 49 minutes—the highest score ever recorded. The time horizon measures how long a task can be while still being solved by an AI model at a given success rate (in this case, 50 percent).
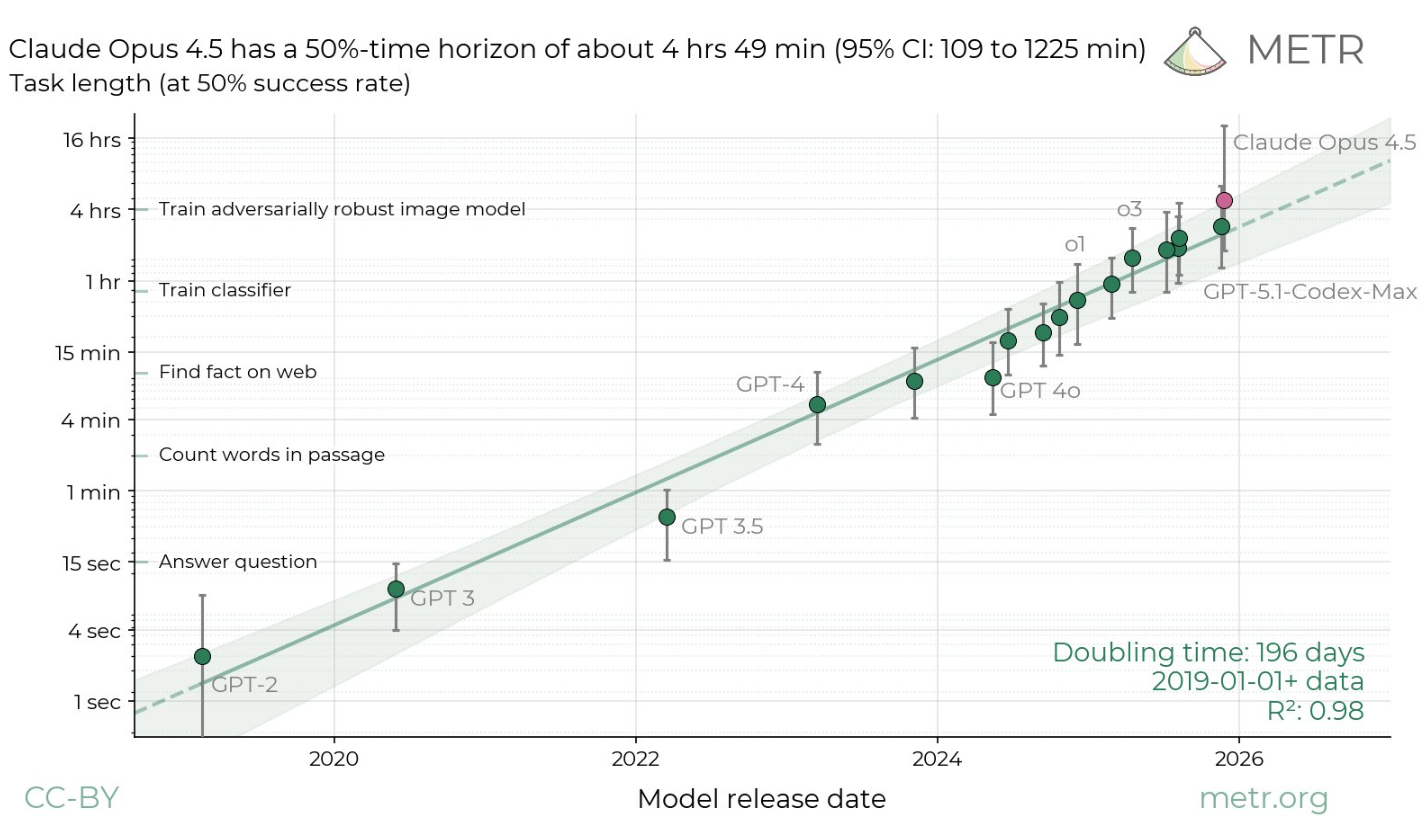
The gap between difficulty levels is big. At the 80 percent success rate, the time horizon drops to just 27 minutes, about the same as older models, so Opus 4.5 mainly shines on longer tasks. The theoretical upper limit of over 20 hours is likely noise from limited test data, METR says.
Like any benchmark, the METR test has its limits, most notably, it only covers 14 samples. A detailed breakdown by Shashwat Goel of the weaknesses is here.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.