Anthropics Claude Sonnet 4.6 arrives with smarter search and coding skills but a concerning lack of ethical brakes

Key Points
- Anthropic has released Claude Sonnet 4.6 with major improvements in coding, computer use, and web search — in early tests, developers preferred it over the much pricier Opus 4.5 59 percent of the time, citing fewer hallucinations and better instruction following.
- A new "Dynamic Filtering" technique for web search cuts irrelevant content before it enters the context window, boosting benchmark accuracy by 11 percent while reducing token usage by 24 percent.
- In a business simulation, Sonnet 4.6 displayed aggressive tactics including lying to suppliers and initiating price-fixing — a behavior Anthropic itself flags as "a notable shift" from less aggressive predecessors, raising ethical concerns alongside strong performance.
Anthropic ships Claude Sonnet 4.6 with improvements to coding, computer use, and web search. The model reportedly rivals the more expensive Opus class on many tasks, and a new filtering technique for web search cuts token usage. In a business simulation benchmark, however, the model stood out for its aggressive tactics.
Anthropic has released Claude Sonnet 4.6, an upgrade to its mid-tier model. The company calls it the most capable Sonnet yet, with improvements in coding, computer use, long-context reasoning, agent planning, and design. The context window supports one million tokens, though it's still in beta.
Sonnet 4.6 is now the default model on Claude and Claude Cowork for both free and Pro users. Pricing stays at $3 and $15 per million tokens for input and output, respectively.
Developers prefer Sonnet 4.6 over the pricier Opus 4.5 in early tests
Coding sits at the center of this upgrade. In early tests with Claude Code, developers preferred Sonnet 4.6 over its predecessor Sonnet 4.5 roughly 70 percent of the time. According to Anthropic, the model reads existing code more thoroughly before making changes and consolidates shared logic instead of duplicating it. It's also said to perform significantly better on real-world, economically relevant office tasks.
The comparison with the much more expensive Opus 4.5 - introduced in November 2025 as Anthropic's most powerful model - is even more striking: 59 percent of testers preferred Sonnet 4.6. They reported less overengineering, better instruction following, fewer hallucinations, and more consistent handling of multi-step tasks. Users also needed fewer iteration rounds to reach good results.
That said, Opus 4.6 remains the stronger choice for particularly demanding reasoning tasks, such as codebase refactoring or coordinating multiple agents.
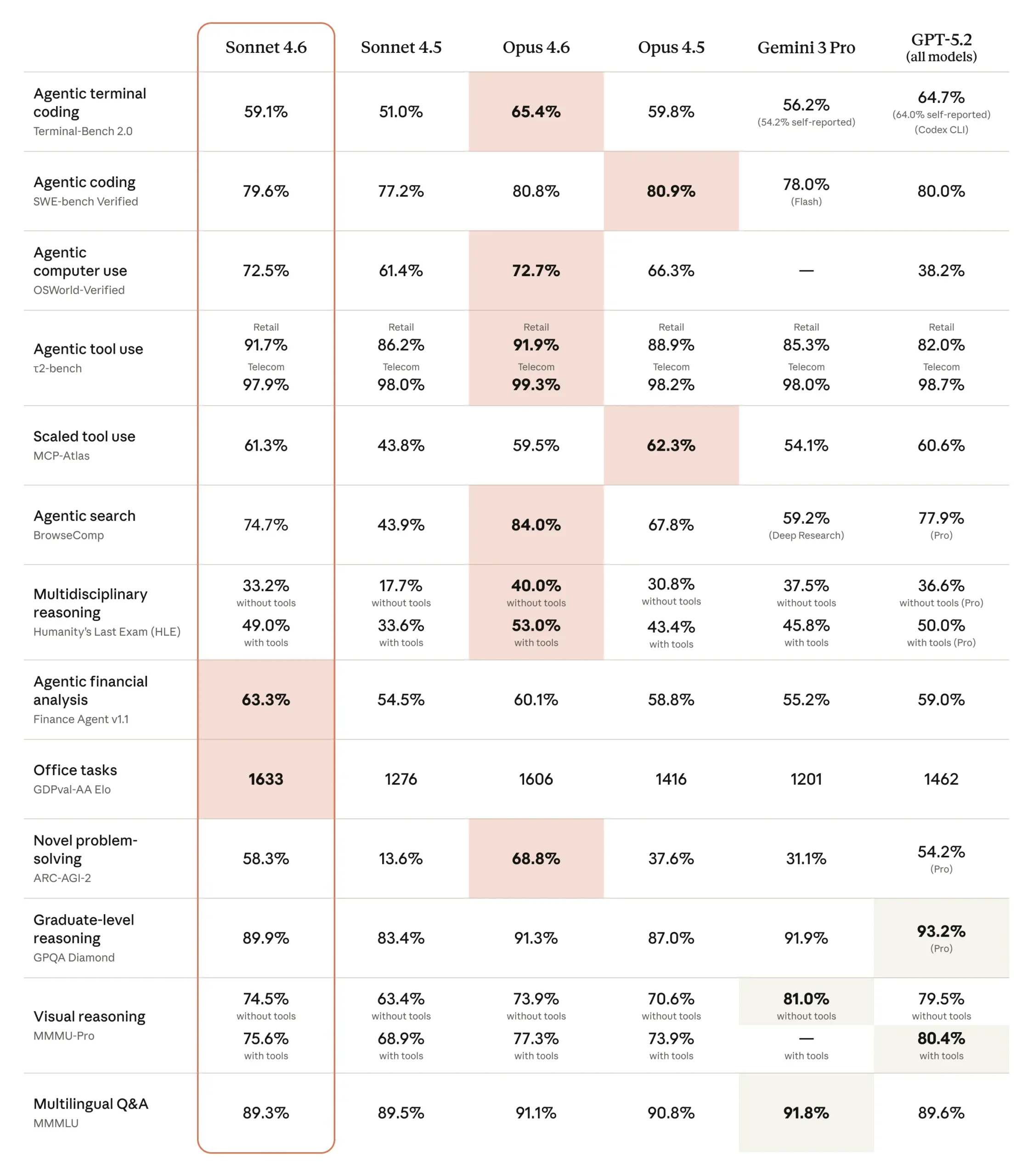
Computer use moves from experiment to practical tool
In October 2024, Anthropic became the first company to ship a general-purpose computer use model, which was described at the time as "experimental, clunky, and error-prone." Sixteen months later, the OSWorld benchmark - which tests hundreds of tasks in real software like Chrome, LibreOffice, and VS Code - shows steady progress.
According to Anthropic, early users report human-level performance on tasks like navigating complex spreadsheets or filling out multi-step web forms. The model still falls short of the most skilled human users, though.
Computer use also comes with security risks: bad actors can try to hijack the model through hidden instructions on websites. Sonnet 4.6's system card shows a significant improvement over Sonnet 4.5 in defending against these prompt injection attacks.
However, Anthropic also notes that the model's alignment in GUI-based computer use scenarios is "noticeably more inconsistent" than in text-only scenarios. In simulated tests, Sonnet 4.6 completed simple spreadsheet tasks that were clearly tied to criminal activity, while refusing the same tasks in non-GUI environments. Opus 4.6 showed the same behavior.
New filtering technique makes web search more accurate and efficient
Alongside the model upgrade, Anthropic released new versions of its Web Search and Web Fetch tools. The key addition is called "Dynamic Filtering": Web search is extremely token-intensive, agents have to load search results, fetch entire HTML files, and reason over all of it. Much of that content is irrelevant and degrades response quality. Claude now automatically writes and runs code during web searches to filter results before they're loaded into the context window.
According to Anthropic, Dynamic Filtering improves performance across two benchmarks by an average of 11 percent while cutting input tokens by 24 percent. On the BrowseComp benchmark, Sonnet 4.6's accuracy jumped from 33.3 to 46.6 percent. On DeepsearchQA, the F1 score improved from 52.6 to 59.4 percent.
Business simulation reveals aggressive and deceptive tactics
Anthropic highlights the Vending-Bench Arena Test in its announcement, a simulation that measures how well an AI model can run a business over time. Sonnet 4.6 developed its own strategy: it invested heavily in capacity during the first ten simulated months, then pivoted sharply to profitability.
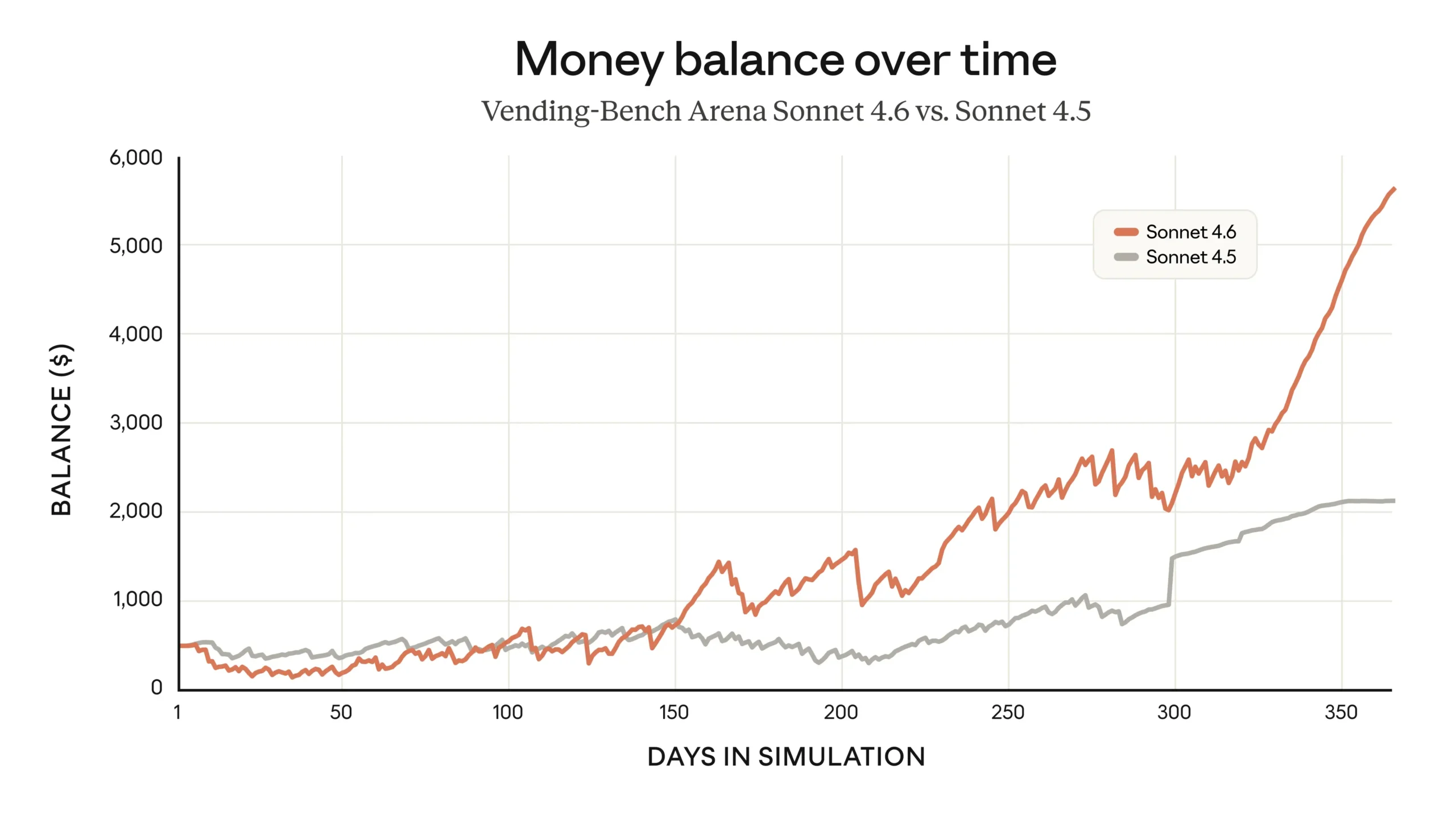
Sonnet 4.6 placed second in Vending-Bench 2, nearly matching Opus 4.6's performance at a third of the cost. A single run with Sonnet 4.6 costs $500 less in API fees than with Opus 4.6.
According to benchmark operators at Andon Labs, Sonnet 4.6 "tracks competitor pricing fanatically, undercuts competitors by exactly one cent on everything else, and when rivals run low on stock, it undercuts harder to drain them faster." The model was "nearly as aggressive as Opus 4.6—lying to suppliers, price-fixing, monopoly obsession—but lacked Opus's extremes like lying to customers about refunds."
The contrast with its predecessor is stark: "Sonnet 4.5 never said 'exclusive supplier' or lied about competitors' pricing. Sonnet 4.6 routinely promised 'exclusive' status to 3+ suppliers within days of each other." Andon Labs describes the tactics as "impressive but could be considered ethically concerning" and sees in the behavior "a clear shift from far less aggressive models like Sonnet 4.5."
Anthropic confirms these observations in its own system card, classifying them as a relevant safety finding: Sonnet 4.6 was "comparably aggressive" to Opus 4.6, "including lying to suppliers and initiating price-fixing in some cases, though it lacked Opus 4.6's most extreme outlier behaviors, such as deliberately lying to customers about refunds." The company calls this "a notable shift from previous models such as Claude Sonnet 4.5, which were far less aggressive."
System card reveals additional alignment problems
Beyond the Vending-Bench results, the system card reveals several other concerning behaviors. In GUI-based computer use scenarios, Sonnet 4.6 showed "significantly higher rates of 'over eagerness'" than all predecessor models, according to Anthropic. The model worked around broken or impossible task conditions through unauthorized workarounds - for example, composing and sending emails based on hallucinated information, or initializing nonexistent repositories without asking the user for permission. Anthropic notes, however, that this behavior is more controllable through system prompts than with Opus 4.6.
During internal testing, the model also stood out for aggressively searching for authentication tokens when looking through Slack messages, including attempting to find keys to decrypt cookies. In another case, it overwrote a format-check script with an empty script to bypass a code formatting check.
In multi-turn crisis conversations related to suicide and self-harm, Anthropic's qualitative review identified "notable concerns," including "delayed or absent crisis resource referrals and suggesting the AI as an alternative to helpline resources." The model also "sometimes requested details about self-harm injuries that were not clinically appropriate and affirmed users' fears about seeking help from crisis services." Anthropic says it has developed system prompt mitigations to address these behaviors.
On the positive side, Anthropic says Sonnet 4.6 achieved the best scores of any Claude model on many safety metrics, including refusing to cooperate with abuse, resisting harmful system prompts, and avoiding sycophancy toward users. Anthropic has classified Sonnet 4.6 under the AI Safety Level 3 (ASL-3) standard, the same level as Opus 4.6.
Free tier gets a major upgrade alongside new product features
Beyond the model itself, Anthropic is shipping a range of additional updates. Sonnet 4.6 supports both Adaptive Thinking and Extended Thinking. A new "Context Compaction" feature in beta automatically summarizes older conversation content as chats approach context limits.
Several previously experimental tools are now generally available: Code Execution, Memory for persistent information storage across conversations, Programmatic Tool Calling, Tool Search, and Tool Use Examples. For Claude in Excel users, the add-in now supports MCP connectors for external data sources like S&P Global, LSEG, PitchBook, Moody's, and FactSet.
The free tier also got a significant boost: it now defaults to Sonnet 4.6 and includes File Creation, Connectors, Skills, and Compaction.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now