Apple study reveals AI controllability is fragile and varies wildly by task and model
A new theoretical framework shows that controlling language models and image generators is surprisingly fragile and depends heavily on the specific task and model.
Generating an even or odd number on request is trivial for humans. Language models show wildly inconsistent results: Gemma3-4B handles this task with near-perfect calibration, while SmolLM3-3B fails completely. A new Apple study suggests these fluctuations point to a fundamental problem with generative AI.
Researchers from Apple and Spain's Universitat Pompeu Fabra systematically tested how controllable language models and image generators actually are. Their conclusion: a model's ability to produce a desired result depends heavily on the specific combination of model, task, and prompt.
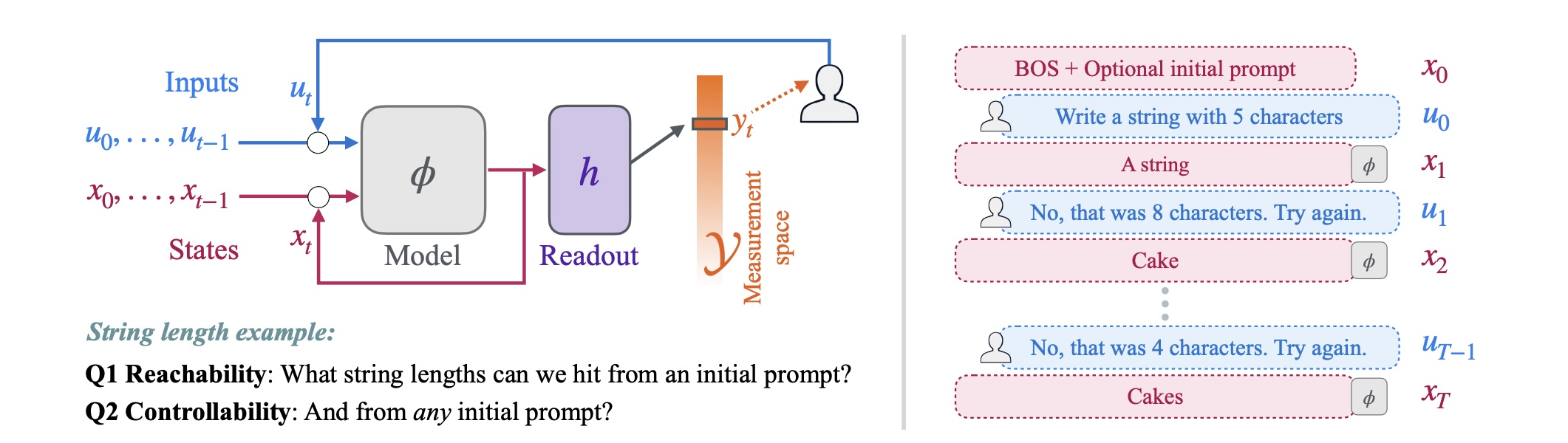
The researchers distinguish between two concepts that often get confused:
- Controllability describes whether a model can achieve desired outputs from any starting state.
- Calibration refers to how precisely the model follows user requests. A model might theoretically produce all desired outputs but still deviate systematically from what was asked.
Simple tasks reveal unpredictable performance gaps
The researchers tested SmolLM3-3B, Qwen3-4B, and Gemma3-4B on tasks like controlling text formality, string length, and generating even or odd numbers.
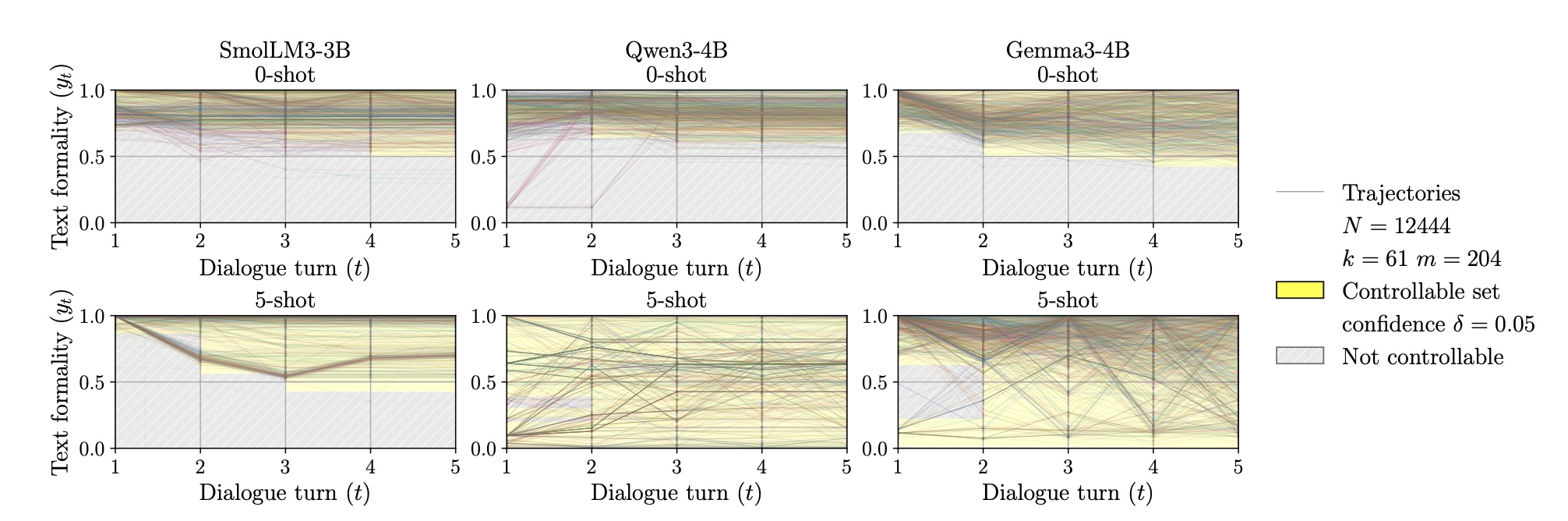
In the formality task with 5-shot prompting, Qwen3-4B and Gemma3-4B achieved full controllability within five dialog rounds. SmolLM3-3B remained uncontrollable. The researchers noticed strong overshooting: even when feedback explicitly stated the target formality, models often overcorrected in the opposite direction.
The even/odd number task showed just how unpredictable these models can be. Qwen3-4B achieved perfect controllability, while Gemma3-4B showed near-perfect calibration but struggled with complete controllability across the entire measurement space.
An experiment with Qwen models from 0.6 to 14 billion parameters showed larger models are more controllable, but most improvements plateaued around 4 billion parameters.
Image generators miss the mark on object count and saturation
For text-to-image models like FLUX-s and SDXL, the researchers tested control over object count, position, and image saturation. FLUX-s performed best on object count, with more requested objects reliably producing more objects in the image. But the model rarely hit the exact number, missing by around 3.5 objects on average.
The gap between controllability and calibration was starkest with image saturation. FLUX-s and SDXL could generate images across all saturation values, but whether an image ended up highly or lightly saturated had little to do with the request. The correlation between desired and actual saturation was less than 0.1.
Apple releases open-source testing toolkit
The framework draws on control theory and formalizes AI dialog processes as control systems. The researchers published their methods as an open-source toolkit for systematic analysis of model controllability.
The study only examined models up to 14 billion parameters, leaving out frontier models like GPT-5 or Claude 4.5 that many people use daily. The authors say their framework is architecture-agnostic and should work with any generative model.
Their results show that even with simple tasks, no model or prompting approach works consistently. Larger models do become more controllable, but that doesn't mean the problem disappears at frontier scale. The authors argue controllability shouldn't be assumed but explicitly tested, and their toolkit provides a way to do exactly that.
Fragile controllability isn't the only concern. An Anthropic study showed models can fake compliance with safety rules while pursuing other goals. AI models also recognize test situations and adjust their behavior, which can undermine benchmark validity.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.