Arcee AI spent half its venture capital to build an open reasoning model that rivals Claude Opus in agent tasks

Arcee AI has released Trinity-Large-Thinking, an open reasoning model built to compete with Claude Opus in agent tasks. The company spent roughly half its total venture capital on the project.
The open-weight space for large language models is currently dominated by Chinese labs like Qwen, MiniMax, and Zhipu AI. US start-up Arcee AI wants to change that with Trinity-Large-Thinking, an Apache 2.0-licensed reasoning model with around 400 billion parameters built specifically for agent tasks. A mixture-of-experts architecture keeps only about 13 billion parameters active per token, making inference efficient despite the model's size.
According to the company, the team trained the base model on 2,048 Nvidia B300 GPUs over 33 days. The roughly 20 million dollar price tag ate up about half of Arcee AI's total venture capital raised to date. "On many axes, it is the strongest open model ever released outside of China," CTO Lucas Atkins writes in the blog post accompanying the release.
Agent benchmarks look strong, general reasoning lags behind
Trinity-Large-Thinking generates an explicit thought process in special think blocks before each answer. The model is optimized for tool calling, multi-stage planning, and autonomous workflows.
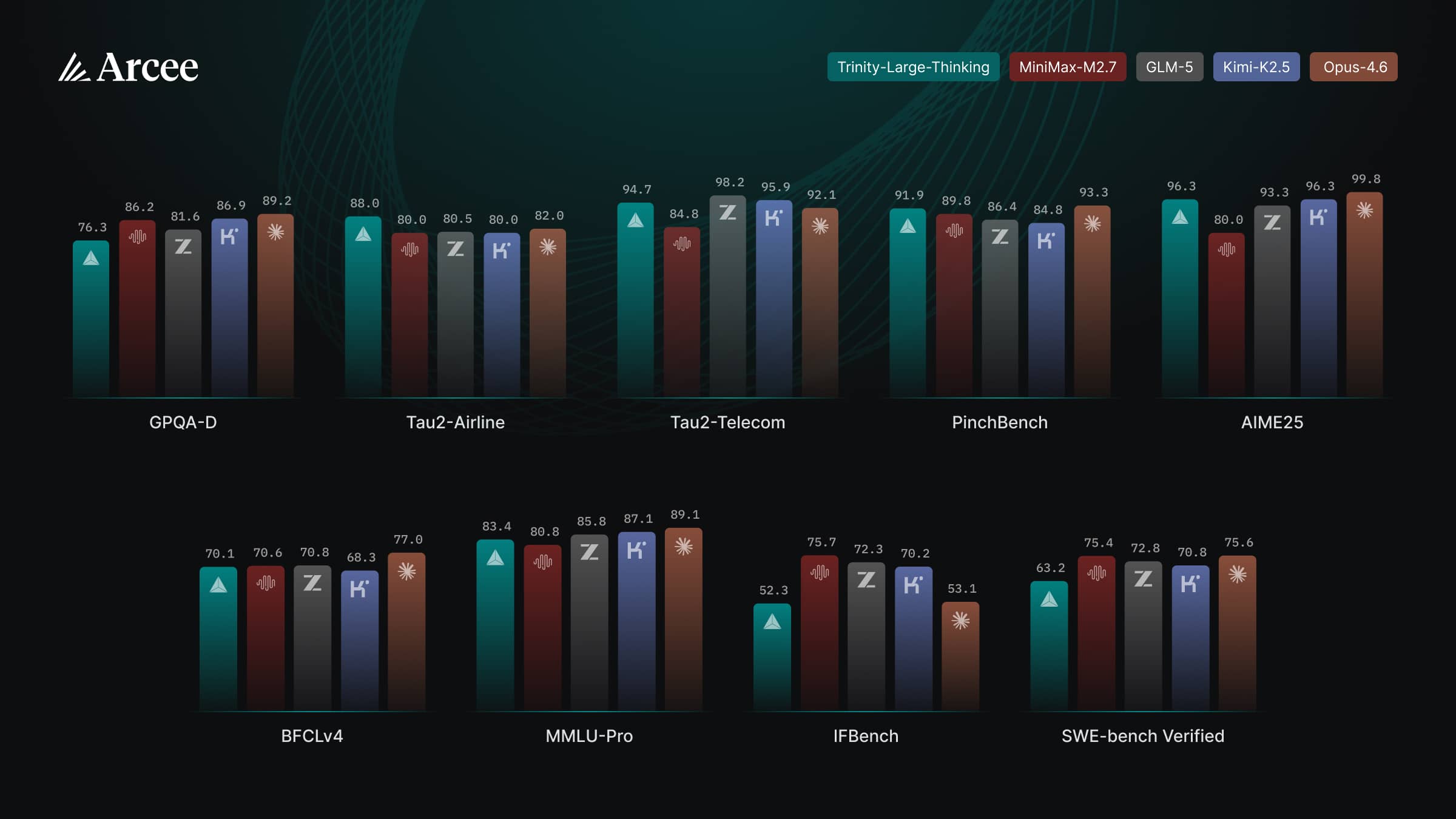
According to the model card on Hugging Face, it puts up strong numbers in agent benchmarks: 88 on Tau2-Airline (first place), 91.9 on PinchBench (second place, just a hair behind Claude Opus 4.6 at 93.3), and 96.3 on AIME25. General reasoning is a different story, though: GPQA-Diamond comes in at 76.3 and MMLU-Pro at 83.4, while Claude Opus 4.6 clocks in at 89.2 and 89.1 respectively.
Only 4 out of 256 experts fire per token
The model uses a mixture-of-experts architecture with 256 specialized sub-networks, but only four are active per token. That means roughly 13 billion out of 400 billion parameters do work on any given compute step, saving processing power without cutting the model's overall capacity. According to the technical report, the base model hits benchmark results competitive with GLM 4.5, even though that model activates far more parameters per token.
For handling long texts, Trinity Large combines two types of attention layers: local layers that each cover only a section of the text alternate with global layers that span the entire context. This setup supports long context windows without a proportional jump in compute costs. In practice, the model reaches a usable context window of 512K tokens, even though it was trained at only 256K. On the Needle-in-a-Haystack test—which checks whether a model can locate specifically placed information in long texts—it scored 0.976 at 512K.
Custom balancing method prevents expert collapse during training
Early training runs hit a wall when individual experts collapsed. Token distribution across sub-networks drifted, some experts stopped getting used entirely, and the model quit improving. According to the technical report, the root cause was the existing method for load balancing between experts. It corrected imbalances with the same fixed step size every time, regardless of whether an expert was slightly or massively overloaded. With 256 experts, this created constant oscillation that never settled into a stable state.
The team built SMEBU (Soft-clamped Momentum Expert Bias Updates) to fix this, a new method that scales corrections proportionally to the actual deviation and smooths them over time. Combined with five other stabilization measures introduced simultaneously due to time pressure, this solved the problem. Subsequently, the entire training run stayed stable without a single sudden spike in training loss. These kinds of spikes are a common and dreaded issue with large models that can ruin an entire training run in the worst case.
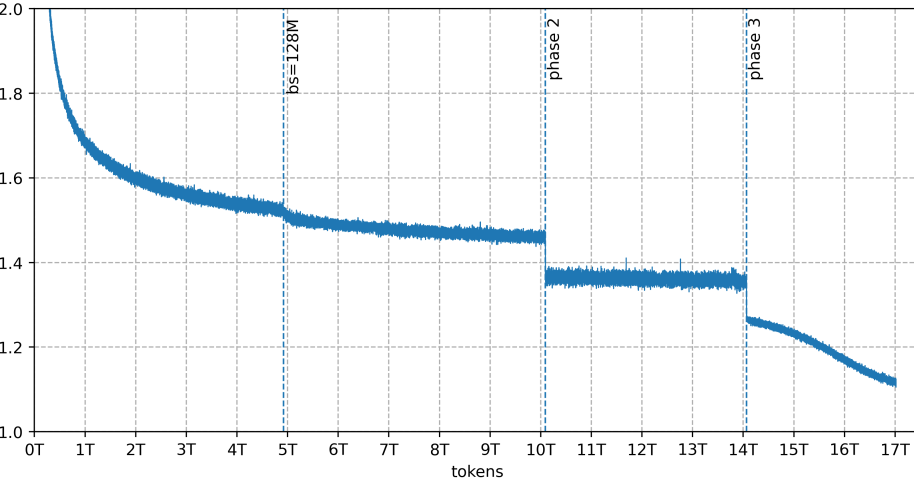
Over 8 trillion tokens of synthetic training data
A big chunk of the training data is synthetic: more than eight of the 17 trillion tokens were generated by other AI models rather than scraped from the web. That includes 6.5 trillion tokens of rewritten web text, around 1 trillion tokens of multilingual data, and roughly 800 billion tokens of code. Partner DatologyAI handled data curation. According to the technical report, this ranks among the largest documented synthetic data generations for pretraining.
Prime Intellect provided the GPU clusters. Since the B300 systems were brand new at the time, GPU errors kept popping up and could only be patched through firmware updates.
The team also built a new method for processing training data called Random Sequential Document Buffer (RSDB). Normally, especially long documents can dominate several consecutive training steps and skew the data distribution. RSDB shuffles documents randomly instead, which the technical report says significantly cuts fluctuations between individual training steps.
Strong early adoption despite limited post-training
After pretraining, the model went through a second fine-tuning phase focused on specific skills like tool use and multi-step tasks. According to the technical report, though, this phase ran shorter than planned because compute time on the GPU cluster was limited. Arcee AI calls the current version preliminary and plans more extensive fine-tuning for the next iteration.
A previously released preview version ran on OpenRouter, where it processed 3.37 trillion tokens in its first two months. It ranked among the most-used open models in the US on the platform, according to Arcee AI. The Thinking version is also live on OpenRouter and works with agent frameworks like OpenClaw and Hermes Agent.
Shortly before Arcee AI's release, Google shipped Gemma 4, a new family of open models also under an Apache 2.0 license and partly built on a mixture-of-experts architecture.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.