Microsoft-Tsinghua team trains 7B coding model that beats 14B rivals using only synthetic data
Researchers show that an AI model trained on synthetic programming tasks alone can beat larger competitors. A key finding: task variety matters more than the number of solutions.
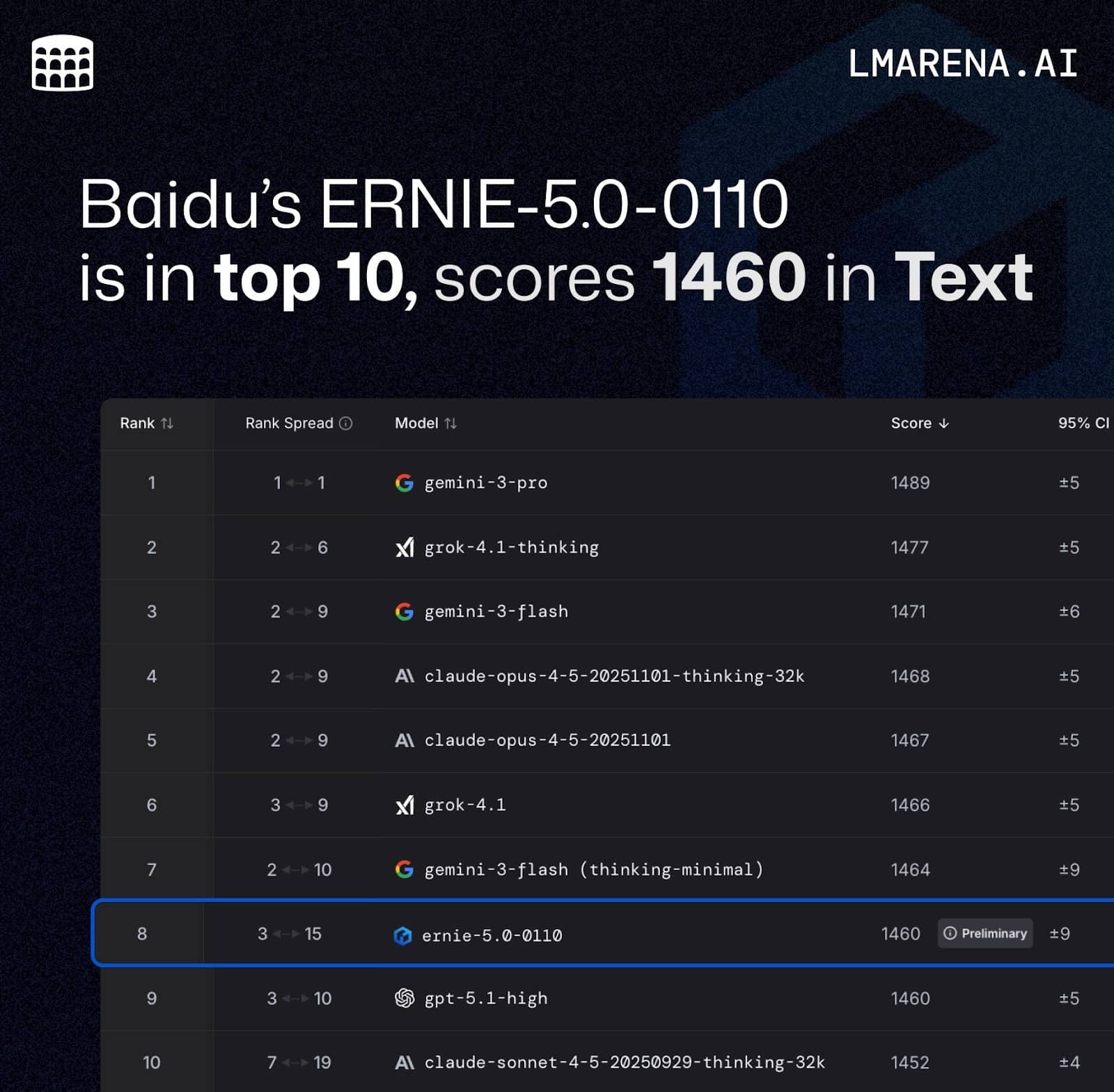
Baidu's new AI model Ernie 5.0, which processes text, images, audio, and video in a unified architecture, is now officially available. According to the LMArena ranking from January 15, 2026, Ernie-5.0-0110 scored 1,460 points, placing 8th globally and 1st among all Chinese models. That puts it on par with OpenAI's slightly older GPT-5.1 (High) and ahead of both Google's Gemini 2.5 Pro and Anthropic's Claude Sonnet 4.5. The next best Chinese model is GLM-4.7 from Zhipu AI. In the math category, Ernie 5.0 came in second worldwide, trailing only GPT 5.2 (High).
The LMArena ranking is determined from numerous anonymous pair comparisons in which users choose the better model answer.
Under the hood, the model uses a mixture-of-experts architecture with around 2.4 trillion parameters - but less than 3 percent of those are active for any given query. For now, the model is only available at ernie.baidu.com. Unlike previous releases, Baidu hasn't published any weights yet, and there's no technical report or detailed documentation available. The company's most recent open release was Ernie-4.5-VL-28B-A3B-Thinking, a model that can manipulate images during its reasoning process - for example, zooming in on text to read it more clearly.
Cursor's agent swarm tackles one of software's hardest problems and delivers a working browser
Building a web browser from scratch is considered one of the most complex software projects imaginable. All the more remarkable: Cursor set hundreds of autonomously working AI agents to exactly this task and after nearly a week produced a working browser with its own rendering engine.
OpenAI's GPT-5.2 Pro has helped solve another Erdős problem. Neel Somani used the AI model to crack Erdős problem #281 from number theory. Mathematician Terence Tao calls this "perhaps the most unambiguous instance" of an AI solving an open mathematical problem. While earlier proofs may have influenced the model's answer, Tao confirms GPT-5.2 Pro's proof is "rather different".
But Tao warns against a skewed perception of AI capabilities. Negative results rarely get published, while positive results go viral. A new database by Paata Ivanisvili and Mehmet Mars Seven tracks AI attempts at Erdős problems, showing actual success rates of just one to two percent, clustered around easier problems.
Terence Tao says GPT-5.2 Pro cracked an Erdős problem, but warns the win says more about speed than difficulty
Terence Tao says OpenAI’s GPT-5.2 Pro has solved an open Erdős problem largely on its own for the first time. He calls it a milestone but warns against reading too much into it. For Tao, the more exciting development lies elsewhere.