Baidu's latest ERNIE model brings visual reasoning to open-source AI

Baidu has launched ERNIE-4.5-VL-28B-A3B-Thinking, a new AI model that can process images as part of its reasoning process.
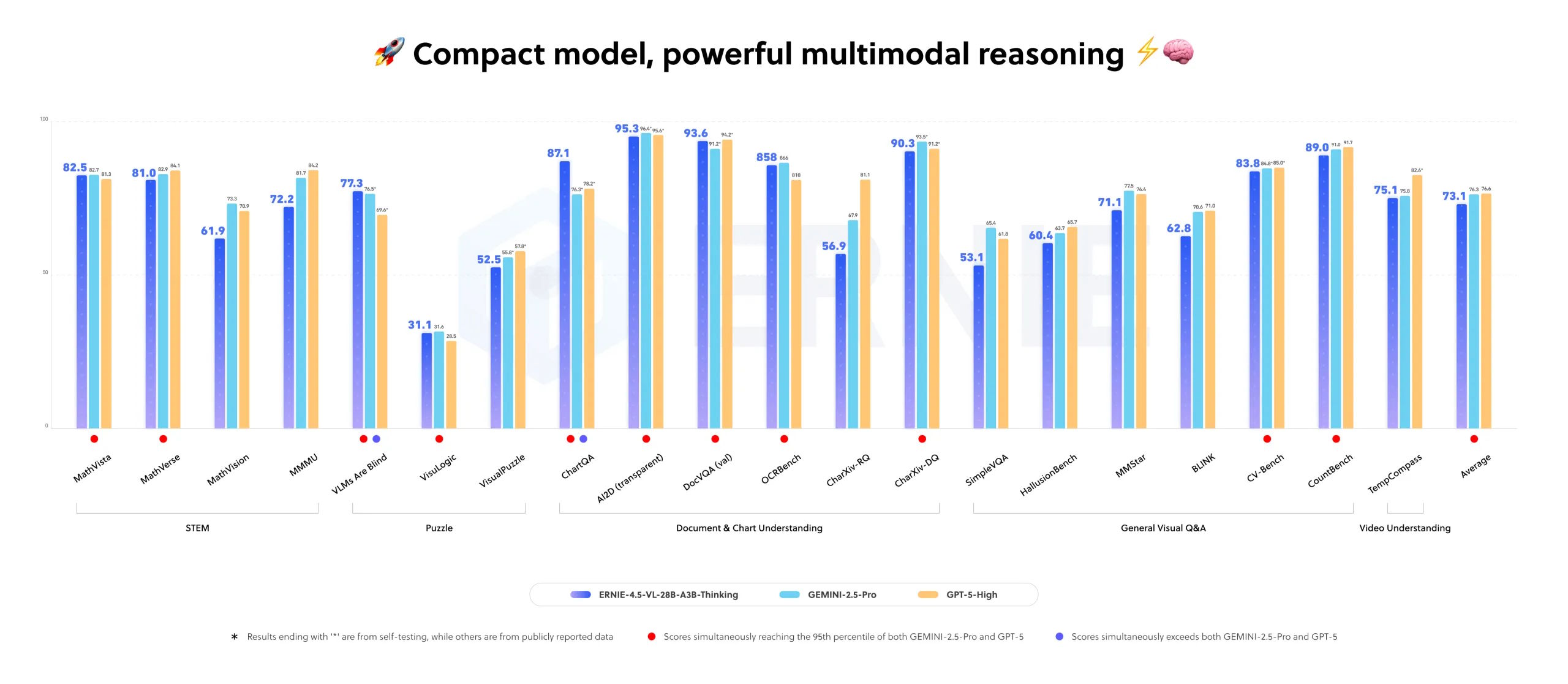
The company claims it outperforms larger commercial models like Google Gemini 2.5 Pro and OpenAI GPT-5 High on several multimodal benchmarks. Despite using just 3 billion active parameters (within a total of 28 billion, thanks to a routing architecture), the model delivers strong results and runs on a single 80 GB GPU, such as the Nvidia A100.
ERNIE-4.5-VL-28B-A3B-Thinking is released under the Apache 2.0 license, so it can be used freely for commercial projects. Its reported performance has not yet been independently verified.
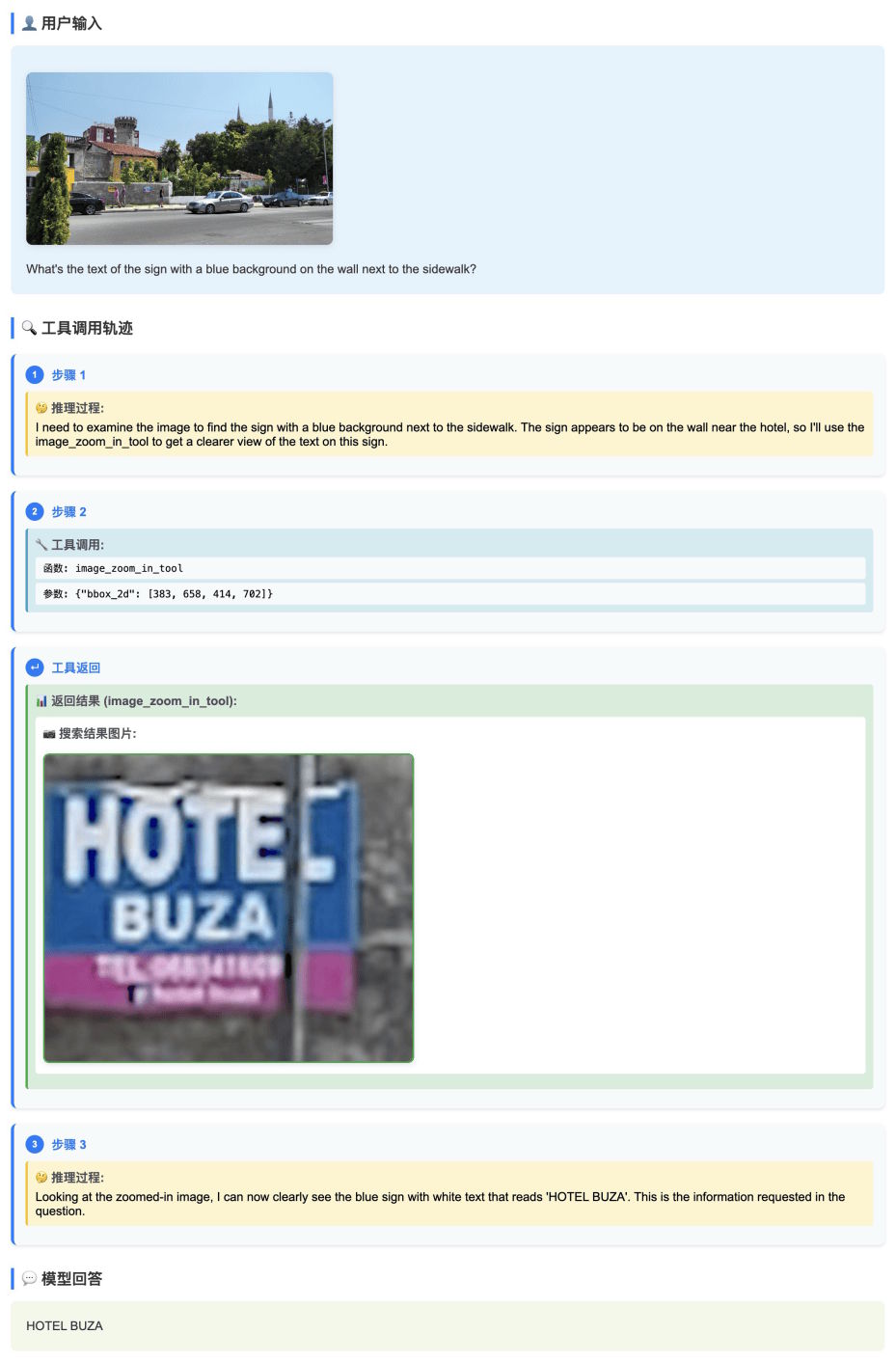
The model’s "Thinking with Images" feature lets it dynamically crop images to focus on key details. In one demo, ERNIE-4.5-VL-28B-A3B-Thinking automatically zoomed in on a blue sign and identified its text.
Other tests showed it pinpointing people in images and returning their coordinates, solving math problems by analyzing circuit diagrams, and recommending the best times to visit based on charts. For video inputs, it can pull out subtitles and match scenes to specific timestamps. The model can also access external tools like web-based image search to identify unfamiliar objects.
Although Baidu highlights ERNIE-4.5-VL-28B-A3B-Thinking’s ability to crop and manipulate images as part of its reasoning process, this approach isn’t entirely new. In April 2025, OpenAI rolled out similar capabilities with its o3 and o4-mini models, which can integrate images directly into their internal chain of thought and use native tools like zoom, crop, and rotate while working through visual tasks. These features helped set new benchmarks for agent-like reasoning and problem-solving.
What stands out now is that these cutting-edge visual reasoning features, previously limited to proprietary Western models, are starting to show up in open-source Chinese models as well, just months after their debut in Western AI systems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.