Best multimodal models still can't crack 50 percent on basic visual entity recognition
Key Points
- Researchers from Moonshot AI have released WorldVQA, a benchmark designed to test whether multimodal language models can truly recognize visual objects.
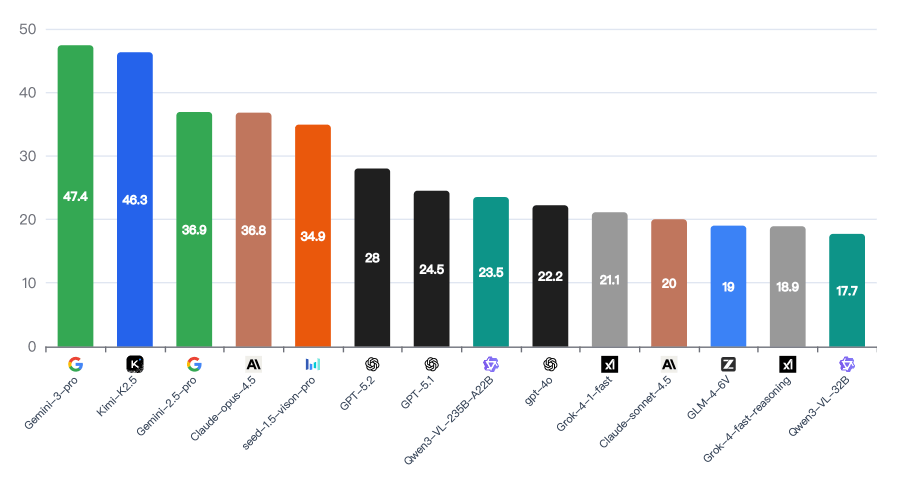
- Even the best-performing models fail to crack the 50 percent mark. Google's Gemini 3 Pro leads the pack at 47.4 percent, followed by Kimi K2.5 at 46.3 percent, while Claude Opus 4.5 reaches 36.8 percent and GPT-5.2 trails at just 28 percent.
- All tested models exhibit systematic overconfidence, assigning high confidence scores even when their answers are incorrect.
The WorldVQA benchmark tests whether multimodal language models actually recognize visual entities or just hallucinate them. Even the best models can't crack the 50 percent mark.
Researchers at Moonshot AI, the company behind the Kimi model series, have released a new benchmark called WorldVQA. The dataset includes 3,500 image-question pairs across nine categories, covering everything from nature and architecture to culture, art, brands, sports, and well-known personalities.
Generic labels don't cut it
WorldVQA sets itself apart from existing benchmarks like MMMU or MMBench by strictly separating pure object recognition from logical reasoning. According to the accompanying paper, the goal is to measure "what the model memorizes" rather than how well it can combine or deduce information.
The questions demand specific answers. If a model identifies a picture of a Bichon Frise simply as "dog," that counts as wrong. The model needs to name the exact breed.
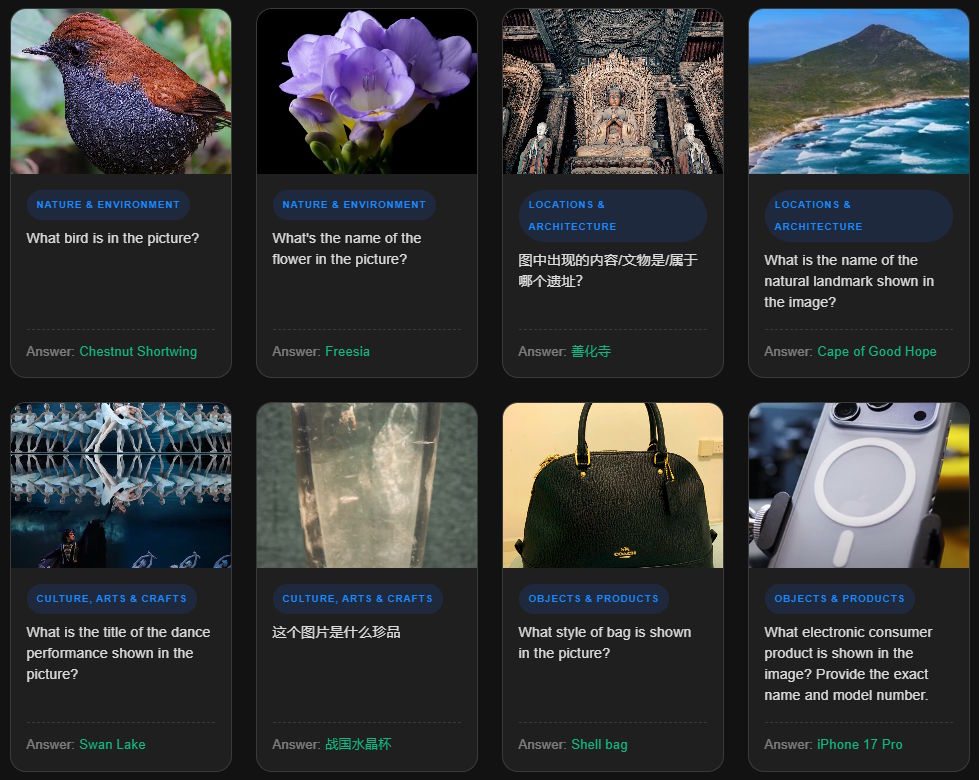
The split between common and rare knowledge is especially telling. Well-known landmarks and popular brand logos appear all over the internet and are well represented in training data, but rare entries test knowledge about obscure objects, animal and plant species, or cultural artifacts from around the world.
Gemini and Kimi lead the pack, but neither breaks 50 percent
Google's Gemini 3 Pro scores highest at 47.4 percent, closely followed by Kimi K2.5 at 46.3 percent as the top freely available model. Anthropic's Claude Opus 4.5 lands at 36.8 percent, and OpenAI's GPT-5.2 at 28 percent. Even Google's older Gemini 2.5 Pro outperforms both.
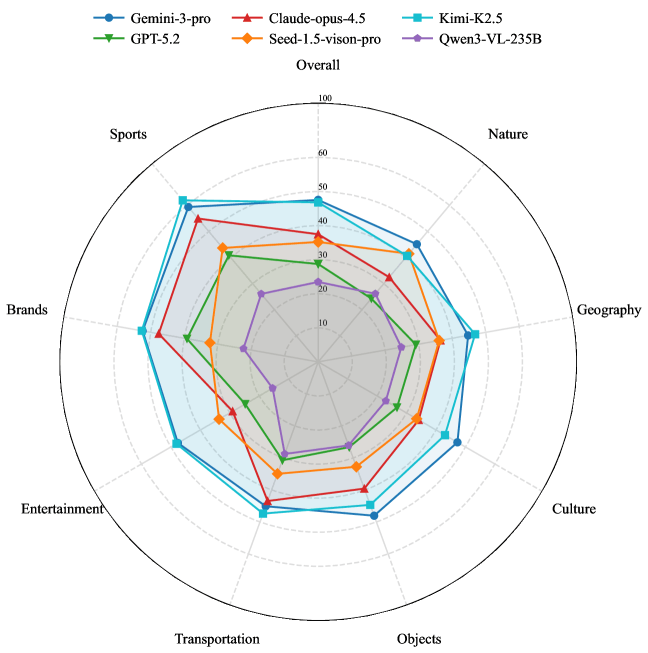
Breaking down the results by category reveals clear knowledge gaps. Models do relatively well on brands and sports, likely because these topics are heavily represented in web training data. Nature and culture scores, on the other hand, drop significantly.
In those categories, models tend to fall back on generic terms like "flower" instead of naming specific species. The AI systems are essentially fluent in pop culture but stay superficial when it comes to the natural world and cultural heritage.
Models consistently overestimate their own accuracy
Another key finding involves self-assessment. The research team asked each model to rate its confidence on a scale of 0 to 100. The results are striking: every model tested showed systematic overconfidence. Gemini 3 Pro reported confidence of 95 percent or higher in over 85 percent of cases - regardless of whether the answer was actually correct. Kimi K2.5 had the best self-calibration with a calibration error of 37.9 percent, but that's still far from ideal.
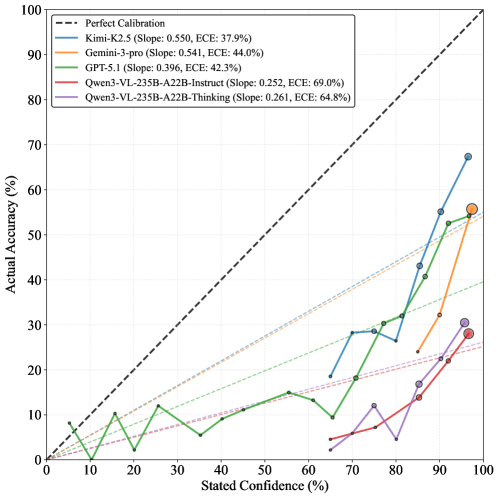
This gap between self-assessment and actual performance suggests that current models lack a reliable internal sense of their own knowledge limits. Put simply, they don't know what they don't know.
Errors trace back to genuine knowledge gaps
To make sure difficult questions actually reflect a real lack of knowledge rather than ambiguous images, the researchers validated their classification using a large reference vocabulary. The analysis confirms the pattern: the less frequently an entity appears in real data, the harder it is for models to recognize it.
Easy questions focus on common objects and people, while questions labeled as difficult genuinely ask about rare occurrences. The benchmark's difficulty comes from actual knowledge scarcity, not annotation errors or visual ambiguity.
Why this matters for AI agents
The researchers see WorldVQA as a necessary step for the next generation of AI assistants. If models can't reliably recognize what they see, their usefulness for real-world tasks stays limited.
The team acknowledges one limitation: the benchmark measures factual knowledge in a highly isolated setting. Whether the ability to correctly name specific entities translates to better performance on complex practical tasks remains an open research question. The dataset and evaluation scripts are publicly available.
Recent studies keep exposing fundamental weaknesses in AI model reliability. The AA Omniscience benchmark from Artificial Analysis recently showed that only four out of 40 models tested scored positive. Gemini 3 Pro led there too, but still had a hallucination rate of 88 percent.
Another study looked at whether language models can estimate how difficult exam questions are for humans. The finding: models are too capable to reproduce the struggles of weaker learners. The researchers called this the "curse of knowledge," and it further shows that models can't reliably gauge their own limitations.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now