BLIVA: AI gets much better at reading text in images

BLIVA is a vision language model that excels at reading text in images, making it useful in real-world scenarios and applications in many industries.
Researchers at UC San Diego have developed BLIVA, a vision language model designed to better handle images that contain text. Vision language models (VLMs) extend large language models (LLMs) by incorporating visual understanding capabilities to answer questions about images.
Such multimodal models have made impressive progress in open-ended visual question-answering benchmarks. One example is OpenAI's GPT-4, which in its multimodal form can discuss image content when prompted by a user, although this capability is currently only available in the "Be my Eyes" app.
However, a major limitation of current systems is the ability to handle images with text, which are common in real-world scenarios.
BLIVA combines InstructBLIP and LLaVA
To address this problem, the team developed BLIVA, which stands for "BLIP with Visual Assistant". BLIVA incorporates two complementary types of visual embeddings, namely learned query embeddings extracted by a Q-former module to focus on image regions relevant to the textual input, similar to Salesforce InstructBLIP, and encoded patch embeddings extracted directly from the raw pixel patches of the full image, inspired by Microsofts LLaVA (Large Language and Vision Assistant).
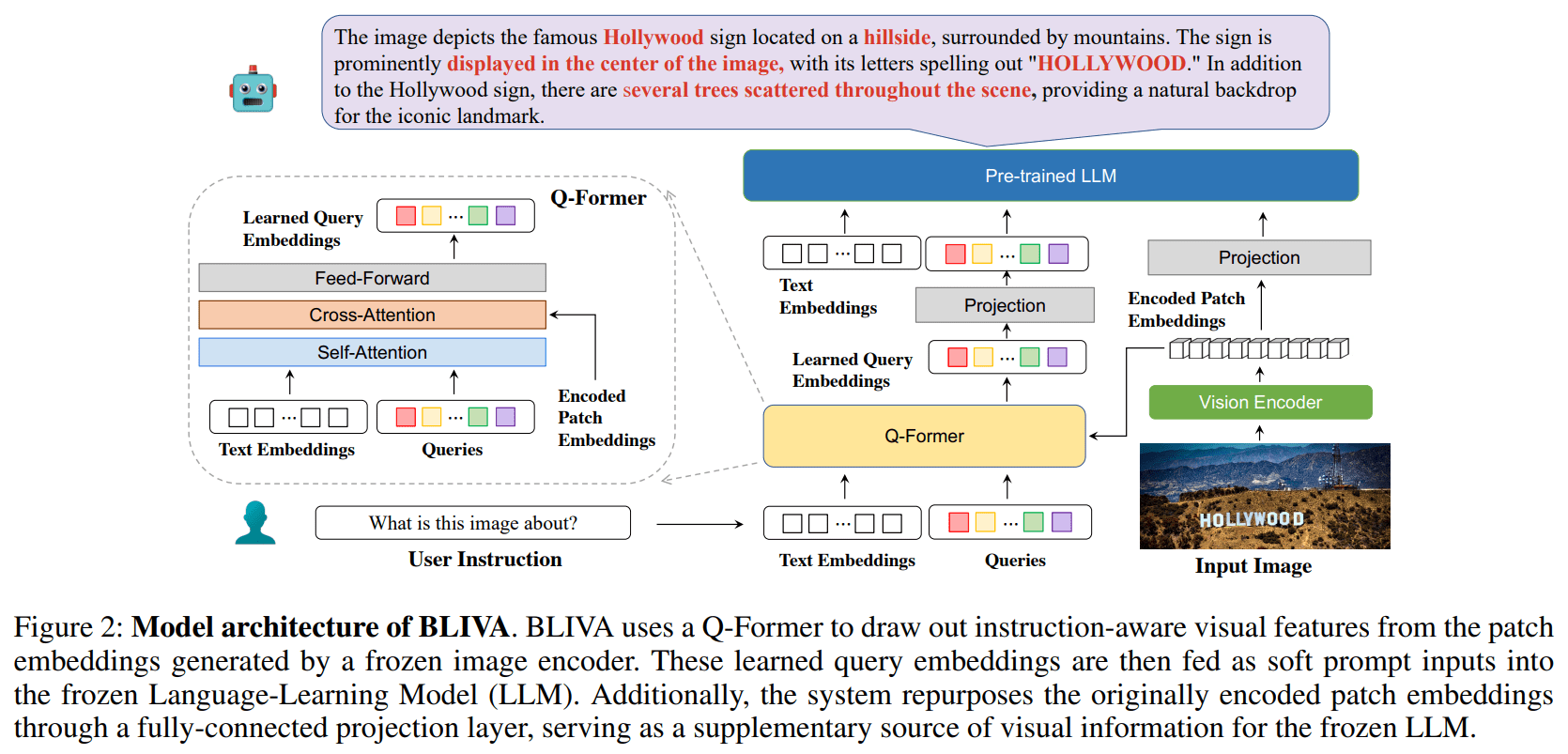
According to the researchers, this dual approach allows BLIVA to use both refined query-based embeddings tailored to the text and richer encoded patches capturing more visual detail.
BLIVA is pre-trained with approximately 550,000 image-caption pairs, and instruction tuned with 150,000 visual question-answer examples while keeping the visual encoder and language model frozen.
The team shows that BLIVA significantly improves the handling of text-rich images on datasets such as OCR-VQA, TextVQA, and ST-VQA. For example, it achieved 65.38% accuracy on OCR-VQA, compared to 47.62% for InstructBLIP. The new system also outperformed InstructBLIP on seven out of eight general, non-text VQA benchmarks. The team believes this demonstrates the benefits of multi-embedding approaches to visual comprehension in general.

The researchers also evaluated BLIVA on a new dataset of YouTube video thumbnails with associated questions, available on Hugging Face. BLIVA achieved 92% accuracy, significantly higher than previous methods. BLIVA's ability to read text on images such as road signs or food packaging, could enable practical applications in many industries, the team said. Recently, Microsoft researchers demonstrated a multimodal AI assistant for biomedicine based on LLaVA, called LLaVA-med.
More information and the code is available on the BLIVA Github, a demo is available on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.