Bytedance's DreamActor-M1 lets users control AI video faces and bodies with uncanny precision

Bytedance has unveiled DreamActor-M1, a new AI system that gives users precise control over facial expressions and body movements in generated videos.
The system uses what the company calls "hybrid guidance" - a combination of multiple control signals working together. DreamActor-M1's architecture has three main components. At its core is a facial encoder that can modify expressions independently from a person's identity or head position. According to Bytedance researchers, this solves a common limitation in previous systems.
The demo shows facial expressions and audio from one video being mapped onto both an animated character and a real person. | Video: Bytedance
The system manages head movements through a 3D model using colored spheres to direct gaze and head orientation. For body motion, it employs a 3D skeleton system with an adaptive layer that adjusts for different body types to create more natural movement.
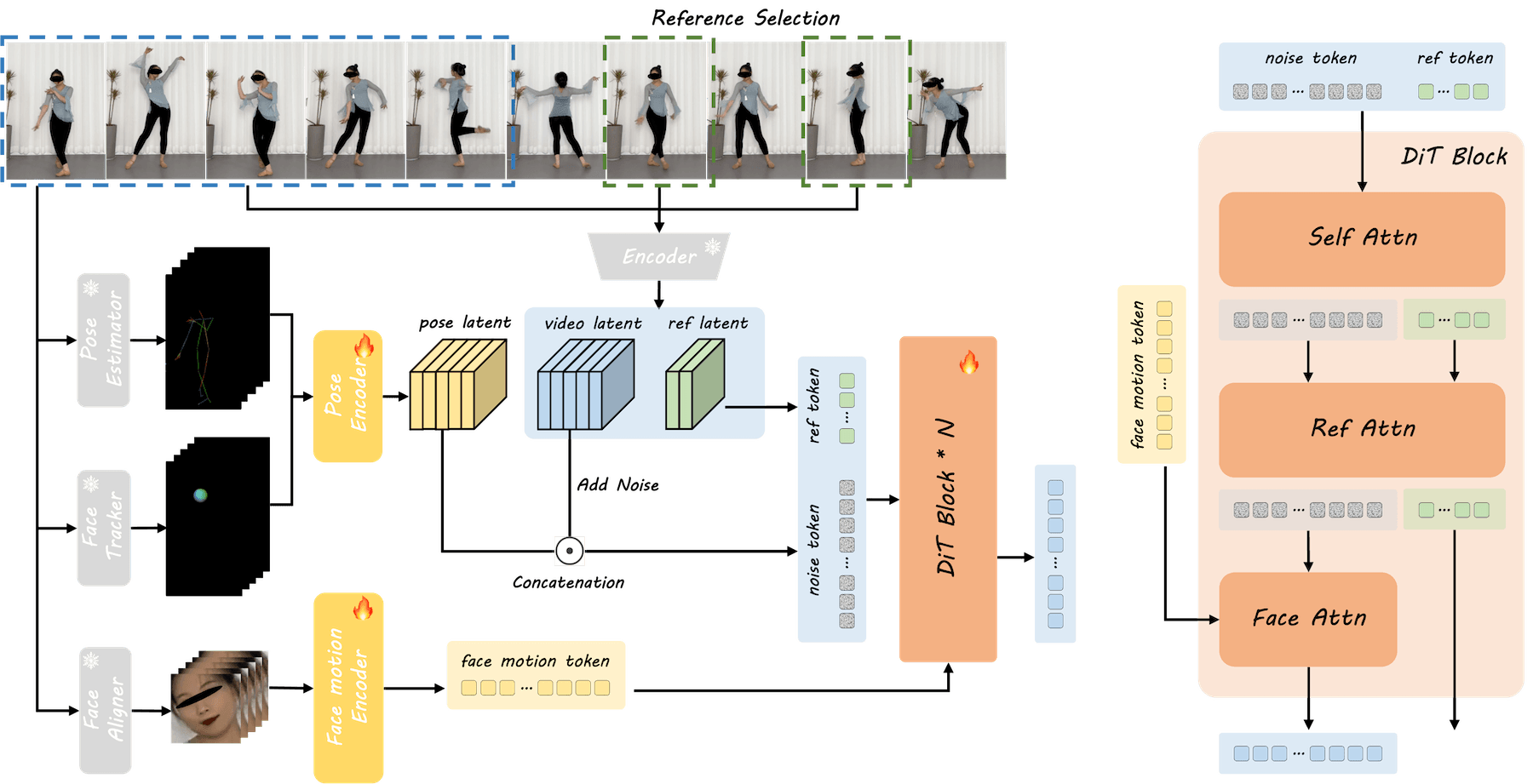
During the training phase, the model learns from images at various angles. The researchers say this allows it to generate new viewpoints even from a single portrait, filling in missing details like clothing and pose intelligently.

Training happens in three stages: first the model works on basic body and head movement, then it adds precisely controlled facial expressions, and finally it optimizes everything together for more coordinated results. Bytedance says the model was trained on 500 hours of video, with equal parts full-body and upper-body footage.
According to the researchers, DreamActor-M1 outperforms similar systems in both visual quality and motion control precision, including commercial products like Runway Act-One.
Video: Bytedance
The system does have limitations. It cannot handle dynamic camera movements, object interactions, or extreme differences in body proportions between source and target. Complex scene transitions also remain challenging.
Bytedance, which owns TikTok, is developing several AI avatar animation projects simultaneously. Earlier this year, the company launched OmniHuman-1, which is already available as a lip-sync tool on CapCut's Dreamina platform, showing how quickly Bytedance can bring research to users. Other ongoing projects include the Goku video AI series and InfiniteYou portrait generator.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.