ByteDance's StoryMem gives AI video models a memory so characters stop shapeshifting between scenes

Key Points
- Researchers from ByteDance and Nanyang Technological University have developed StoryMem, a system designed to maintain visual consistency in AI-generated videos across multiple scenes.
- The system works by storing key frames in a memory bank, which then serves as a reference point when generating new scenes, ensuring characters and objects remain visually coherent throughout.
- In benchmark tests, StoryMem outperformed the basic model by 28.7 percent and surpassed the previous state of the art by 9.4 percent.
A team from ByteDance and Nanyang Technological University has developed a system that keeps AI-generated videos consistent across multiple scenes. The approach stores key frames from previously generated scenes and uses them as references for new ones.
Current AI video models like Sora, Kling, and Veo deliver impressive results for individual clips lasting a few seconds. But combining multiple scenes into a coherent story reveals a fundamental problem: characters change appearance from scene to scene, environments look inconsistent, and visual details drift.
According to the researchers, previous solutions ran into a dilemma. Processing all scenes together in one model causes compute costs to skyrocket. Generating each scene separately and merging them loses consistency between sections.
The StoryMem system takes a third approach. It stores selected key frames in a memory bank during generation and references them for each new scene. This gives the model a record of what characters and environments looked like earlier in the story.

Smart selection keeps memory manageable
Instead of storing every generated frame, an algorithm picks visually significant images by analyzing content and identifying semantically distinct frames. A second filter checks technical quality and throws out blurry or noisy images.
The memory bank uses a hybrid system. Early key images stay as long-term references, while more recent images rotate through a sliding window. This keeps memory size in check without losing important visual information from the beginning of the story.
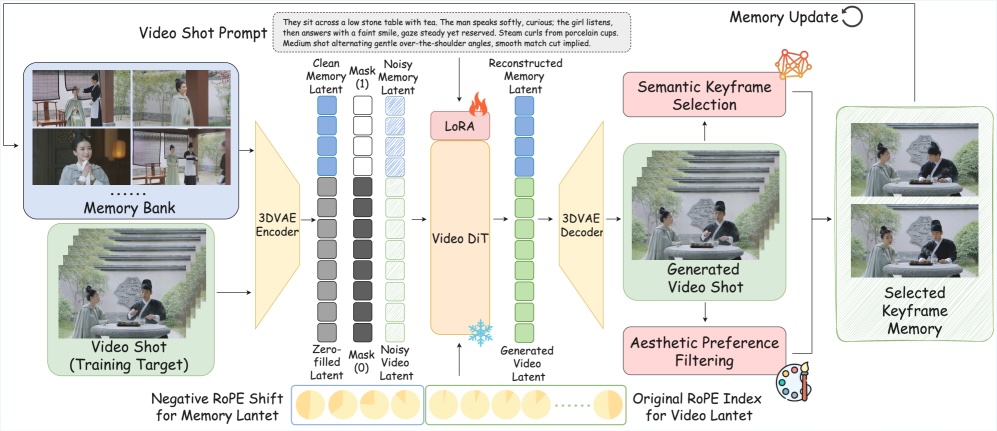
When generating a new scene, the stored images feed into the model alongside the video being created. A special position encoding called RoPE (Rotary Position Embedding) ensures the model interprets memory frames as preceding events. The researchers assign negative time indices to stored images so the model treats them as past events.
Adaptive keyframe extraction with semantic deduplication
A practical advantage of the approach is reduced training effort. Competing methods require training on long, continuous video sequences, which are rarely available in high quality. StoryMem works with a LoRA adaptation (Low-Rank Adaptation) of Alibaba's existing open-source model Wan2.2-I2V.
The team trained on 400,000 short clips, each five seconds long. They grouped the clips by visual similarity so the model learned to generate consistent sequels from related images. The extension adds only about 0.7 billion parameters to the 14 billion parameter model.

Benchmarks show major consistency gains
The researchers built their own benchmark called ST-Bench for evaluation. It includes 30 stories with 300 detailed scene instructions covering styles ranging from realistic scenarios to fairy tales.
According to the study, StoryMem shows significant improvements in cross-scene consistency. It performs 28.7 percent better than the unmodified base model and 9.4 percent better than HoloCine, which the researchers describe as the previous state of the art. StoryMem also achieved the highest aesthetics score among all consistency-optimized methods tested.
A user study backs up the quantitative results. Participants preferred StoryMem's output over all baselines in most evaluation categories.
| Method | Aesthetic Quality↑ | Prompt Following↑ | Cross-shot consistency↑ |
|---|---|---|---|
| Global | Single-shot | ||
| Wan2.2-T2V | 0.6452 | 0.2174 | 0.2452 |
| StoryDiffusion + Wan2.2-I2V | 0.6085 | 0.2288 | 0.2349 |
| IC-LoRA + Wan2.2-I2V | 0.5704 | 0.2131 | 0.2181 |
| HoloCine | 0.5653 | 0.2199 | 0.2125 |
| Ours | 0.6133 | 0.2289 | 0.2313 |
The framework supports two additional use cases. Users can feed in their own reference images as a starting point for the memory bank: photos of people or places, for example. The system then generates a story where these elements appear throughout. It also enables smoother scene transitions. Instead of a hard cut, the system can use the last frame of one scene as the first frame of the next.
Complex scenes still pose challenges
The researchers note some limitations. The system struggles with scenes containing many characters. The memory bank stores images without assigning them to specific characters, so when a new character appears, the model can sometimes apply visual properties incorrectly.
As a workaround, the researchers recommend explicitly describing characters in each prompt. Transitions between scenes with very different movement speeds can also look unnatural, since the frame connection doesn't carry speed information.
The project page with additional examples is already live. ST-Bench will be released as a benchmark for further research. The researchers have published the weights on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now